Python学習【365日チャレンジ!】337日目のマスターU(@Udemy11)です。
印鑑証明が必要になったので、実印の登録に市役所に行ってきました。
以前、大阪府に引っ越した際に住民票を移したのですが、この際に登録していた印鑑登録も抹消されていいたので、あらためて登録する必要がありました。
もしかしたら、再び引っ越して戻ってきた時に印鑑を登録していたかもしれなかったので、登録しているかどうか確認したところ、きちんと登録していたようなのでそれを発行してもらうことにしました。
すると、びっくり!
【見たこともないような印鑑】が登録されているではありませんか!
その印鑑がどこにあるのか全くもって思い出せなかったので、今回持参した印鑑で再度登録したのですが、うちに返ってみてさらにびっくり。
いつも印鑑をおいているところに【見たこともないような印鑑】が普通においているではありませんか!
ほんと年をとると、忘れっぽくなって困りますよね〜。
もしかしたら、若年性健忘症かもしれないと不安に襲われてしまいます。。。
不安は動くことでしか解消できないので、今日もPython学習を始めましょう。
昨日の復習
昨日は、BeautifulSoupを使ってGoogle検索の1ページ目に表示されるサイトのタイトルを抽出しました。
表示されているタイトルは、HTMLのタグh3タグを指定することで抜き出すことができましたが、34文字以上のタイトルの場合は最後が省略されて…で表示されるので、リンクをたどったページからtitleタグを抽出する必要があります。
詳しくは、昨日の記事を御覧ください。

今日は、検索にヒットしたページのリンクをたどるためのURLを抽出してみたいと思います。
URLを抽出するコード
昨日と同じようにBeautifulSoupで抽出できるかとおもっていろいろと試してみたのですが、どうにもこうにもうまく抽出できなかったので、以前使ったことがあったlxmlライブラリを使用してみました。
Anacondaをインストールしている場合はすでにインストールされていると思いますが、まだの場合はターミナルでpip install lxmlを実行してインストールしておきます。
準備が整ったらコードを書いていきます。
import lxml.html as lx
import re
import requests
search_query = 'Udemy'
r = requests.get('https://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=' + search_query)
html_l = r.text.encode()
root = lx.fromstring(html_l)
url_results = []
for t in root.cssselect('div.kCrYT a'):
res = re.sub(r'/url\?q=|&sa.*', '', t.get('href'))
result = re.sub(r'/search\?gl=JP&ie=UTF-8&q=.*', '', res)
if result != '':
url_results.append(result)
print(result)https://about.udemy.com/jp/出力結果
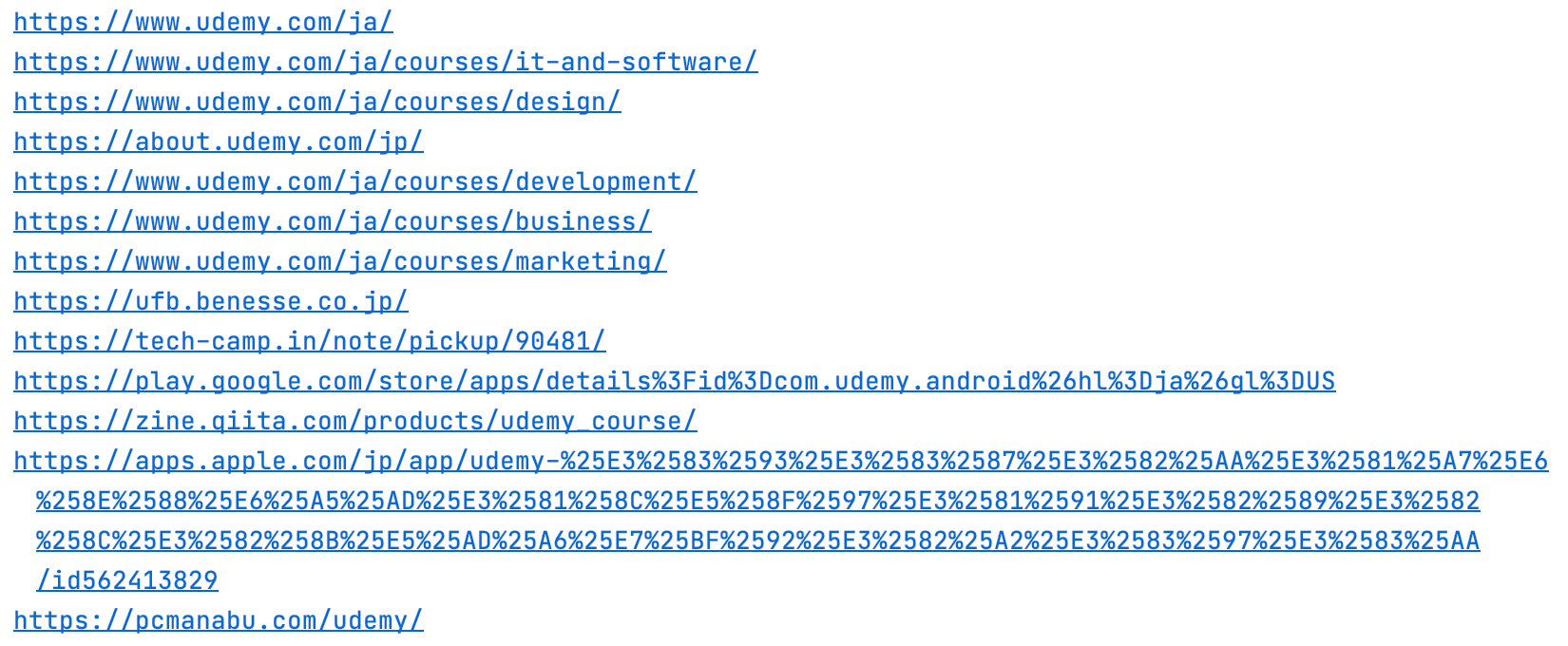
タイトルを抽出したときは8つでしたが、URLは14個も抽出されました。
よく見てみると、Udemyのサイト内のカテゴリ6つのURLも含まれていました。
部分ごとにコードを見ていきましょう。
インポートするライブラリ
import lxml.html as lx
import re
import requests多分、BeautifulSoupでも問題なくできると思うのですが、結構時間をかけてもうまく行かなかったので、lxmlをかわりに使っています。
あとは、正規表現を扱うreとサイトからHTTPでデータを取得するrequestsをインポートしています。
検索キーワードと解析オブジェクト
search_query = 'Udemy'
r = requests.get('https://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=' + search_query)
html_l = r.text.encode()
root = lx.fromstring(html_l)昨日と同じように、5行目で検索するキーワードをsearch_queryに代入します。
7行目のrequests.getで検索結果をrに入れて、8行目でテキストをエンコードしてhtml_lに代入したあと、9行目でlxmlで解析するためのオブジェクトrootを作成します。
データの抽出
url_results = []
for t in root.cssselect('div.kCrYT a'):
res = re.sub(r'/url\?q=|&sa.*', '', t.get('href'))
result = re.sub(r'/search\?gl=JP&ie=UTF-8&q=.*', '', res)
if result != '':
url_results.append(result)
print(result)10行目で空のリストurl_resultsを作ります。
11行目からforループでcssセレクタでkCrYTをクラス名に持つdivタグ内のaタグを抽出して、12行目で正規表現のre.subを使って、t.getでhref要素を抽出し、先頭に/url?=があれば、/url?=から後ろの文字をresに代入します。
さらに同じように、resの先頭が/search?gl=JP&ie=UTF-8&q=で始まるデータを削除して空白''に変換してresultに代入します。
14行目のif文でresultが空白''以外のときに、10行目で定義したリストurl_resultsに追加して、resultを出力します。
まとめ
Googleの検索結果のHTMLを見ると、気分が落ち込んじゃいます。
表示されているのは非常にシンプルなのに、HTMLが複雑すぎて、どのコードがどこを表示しているのかわからなくなってくるんです。
Chromeのデベロッパーツールを使えば、HTMLのコードを選択するとページのどこがそのコードなのかハイライトされるのですが、私にはちょっと使いづらいんです。
また、見つけたコードのクラスを指定しても、不要な部分まで抽出してしまったり、全く違う部分が抽出されたりするので、コードを紐解いていくのがもう大変。
といってもこの作業をしなければ、Webスクレイピングの根本的なところが理解できないので、やるしかありません。
URLを抽出できたので、あとはそのサイトからタイトルを抽出すれば、昨日のような省略されて…が表示されるタイトルではないタイトルを取得することができます。
明日は、今日取り出したURLにアクセスして正式なタイトルを取得していこうと思います。
それでは、明日もGood Python!