Python学習【365日チャレンジ!】341日目のマスターU(@Udemy11)です。
今日は、阪神淡路大震災が起こった日で、26年が経過しました。
当時はまだ大学生で、この日は関東の雪山でスキーを楽しんでいたのですが、出来事に気づいたのは、スキー場からの帰り道でした。
車の中で聞くラジオから、関西で大きな地震が起こったことがニュースとして流れていて、当時は携帯電話もないので、慌てて公衆電話から実家に電話するも全くつながらず、状況が把握できませんでした。
その当時から考えると、通信手段が飛躍的に発展して、リアルタイムで世界の出来事がわかる世の中になりました。
ほんと、テクノロジーの進化はわたしたちの暮らしを豊かにしてくれる反面、世界の脅威の一つとして、人工知能がリストアップされています。
それほどテクノロジーがわたしたちの生活を脅かす存在になっているのが現状ですが、ソフトバンクの孫会長は、逆に人工知能を使って、他のリストアップされている世界の驚異を取り除くことも可能ではないかと話していました。
この先、テクノロジーがどのように進化していくのかは、自分自身で確認するしかありませんので、じっくり世の中の状況を観察していきましょう。
それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、Google検索の1ページ目にヒットしたURLとサイトにアクセスして、タイトルを取得して、CSVファイルに書き出しました。
CSVファイルへの書き出しは、過去に学習した内容を復習しながらスムーズに書き出すことができましたが、2つのリストを一度に書き込む際にzipを使うところで少しだけ手間取りました。
詳細についてはこちらの記事をごらんください。

今日は、URLとタイトルを取得するファイルとCSVに書き込むファイルに分けて、書き込みファイルから取得ファイルをインポートして実行してみようと思います。
data_stock.py
まずは、Google検索の結果からURLを取得して、取得したURLからタイトルを取得するコードです。
import re
import urllib.parse
from bs4 import BeautifulSoup
import requests
search_query = 'Python オンライン講座'
r = requests.get('https://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=' + search_query)
html_soup = BeautifulSoup(r.text, 'html.parser')
url_results = []
for t in html_soup.select('.kCrYT > a'):
u_result = re.sub(r'/url\?q=|&sa.*', '', t.get('href'))
url_results.append(urllib.parse.unquote(u_result))
title_results = []
for i in url_results:
try:
search = requests.get(i)
search_soup = BeautifulSoup(search.text, 'html.parser')
titles = search_soup.find('title')
title_results.append(titles.text)
except:
print('取得できませんでした。')検索キーワードを変更しただけで、コードは昨日と変更していません。
次に、CSVファイルに取得したデータを書き出すファイルを作成します。
save_file.py
csvとdata_stock.pyをインポートして、リストの名前を少し変更すれば完成です。
import csv
import data_stock as ds
with open('url_title.csv', 'w') as csv_file:
fieldnames = ['TITLE', 'URL']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for t, u in zip(ds.title_results, ds.url_results):
writer.writerow({'TITLE': t, 'URL': u})
with open('url_title.csv', 'r') as csv_file:
reader = csv.DictReader(csv_file)
for r in reader:
print(r['TITLE'], r['URL'])data_stockをdsとしてインポートして、9行目でリストを取得するときに、ds.を付け加えます。
これで、save_file.pyを実行すれば、【Python オンライン講座】の検索で取得したURLとタイトルがurl_title.csvが作成されます。
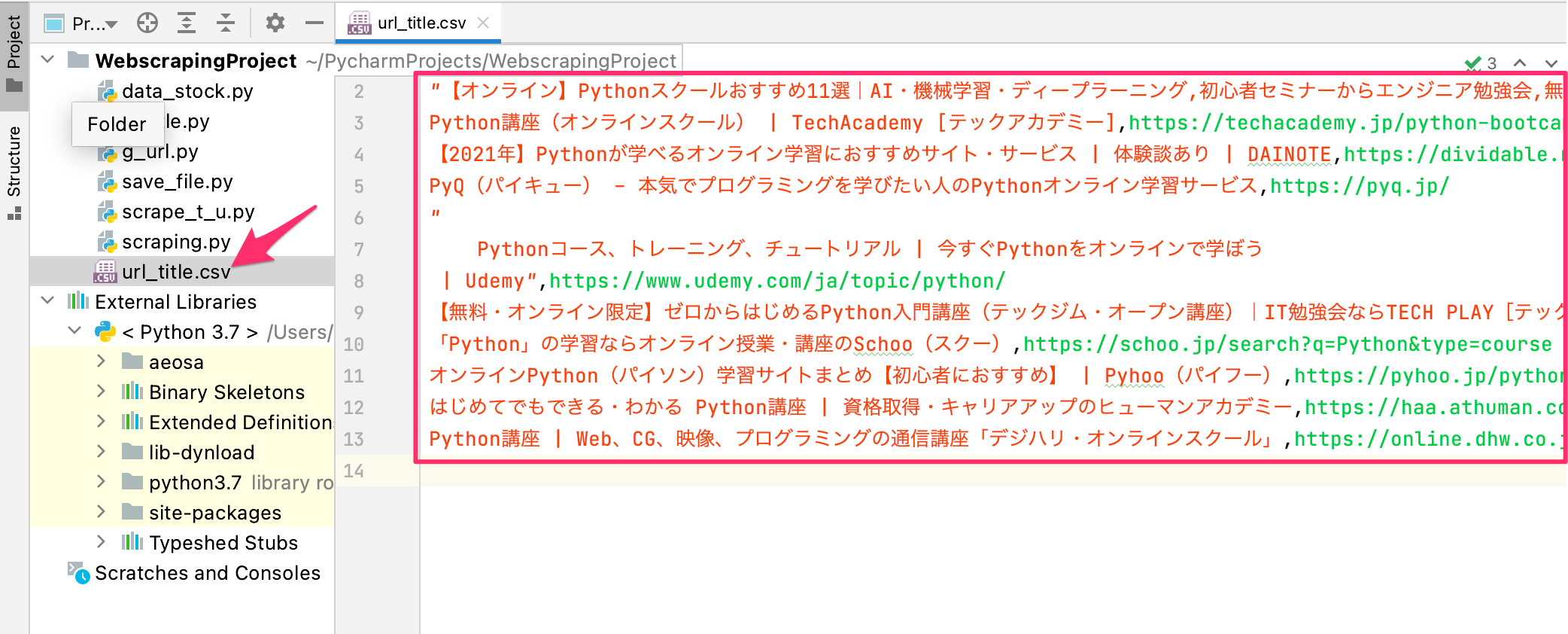
まとめ
ファイルを分ける必要はないかと思いますが、一応、役割分担的に、取得するファイルと書き込むファイルに切り分けてみました。
また、昨日の記事では、タイトルを取得する際、timeで次のURLにアクセスする間隔をあけていましたが、よくよく考えると、Google検索にアクセスしているわけではないので、入れる必要がないんじゃないかということで、コードから外しました。
うまく動作したのを確認したあとは、「これいらないんじゃないの?」と思うコードをどんどん削って、スッキリしたコードにしていきましょう。
それでは、明日もGood Python!