Python学習【365日チャレンジ!】169日目のマスターU(@Udemy11)です。
今日は肉(29)の日ですね。
数字の語呂合わせってパスワードなどに使うことがあるかと思いますが、注意をしたほうがいいですよ。
例えば東急を【10(とう)9(きゅー)】にしたり、富士山を【22(ふじ)3(さん)】にしたりして、パスワードを覚えやすい数字にかえても、誰でも思いついちゃいますからね。
なので、パスワードの管理には、パスワード管理アプリの【1Password】を使うのがおすすめです。
憶えておくのはマスターパスワードだけなので、セキュリティーも利便性も向上しますよ。
それでは今日もPython学習を始めましょう。
昨日の復習
昨日まで4日間をかけてFlaskの使い方を学習しました。
Webサーバーの構築やHTTPメソッドを使った情報のやり取り、データベースに情報を保存したり取り出したりする方法を学習しました。
Flaskの学習については、こちらの記事をごらんください。


今日は、beautifulsoupを使ったWebスクレイピングのやり方について学習します。
Webスクレイピングとは
Webスクレイピングは、Webに散らばるHTMLページなどから、必要な情報を抜き出すことです。
scraping()は【削り取る、削ぎ落とす】という意味なので、Webページの情報をごそっと持ってきて、必要なところだけいただくというイメージですね。
ECサイトなどからリアルタイムの価格情報や評価情報などをスクレイピングして、自分のサイトに最新情報を表示するというような使い方がされていますが、スクレイピングはサーバーに負荷をかけるので、サイトによっては、スクレイピング禁止といった表示のあるところもあります。
イメージ的にはあまり良いイメージのないスクレイピングですが、サーバーに負担をかけない使い方をして大量にあふれる情報から必要な情報だけを抜き取ることもできる便利なテクニックであることは間違いありません。
BeautifulSoup
Beautiful Soupは、HTMLのファイルやXMLのファイルからデータを取り出すことができるPythonライブラリで、Pythonの世界では知らないものはいないくらい有名なサードパーティーライブラリの1つです。
Anacondaを使ってPythonをインストールした場合は、デフォルトで組み込まれているので、個別にインストールすることなく使うことができます。
詳細についてはBeautiful Soupのドキュメンテーションをごらんになってみてください。

日本語でも表示できるので、内容は理解できるかと思います。
Beautiful Soupの使い方
それでは、実際にBeautiful Soupを使って本サイト(udemyfun.com)をスクレイピングしてみます。
from bs4 import BeautifulSoup
import requests
html = requests.get('https://udemyfun.com')
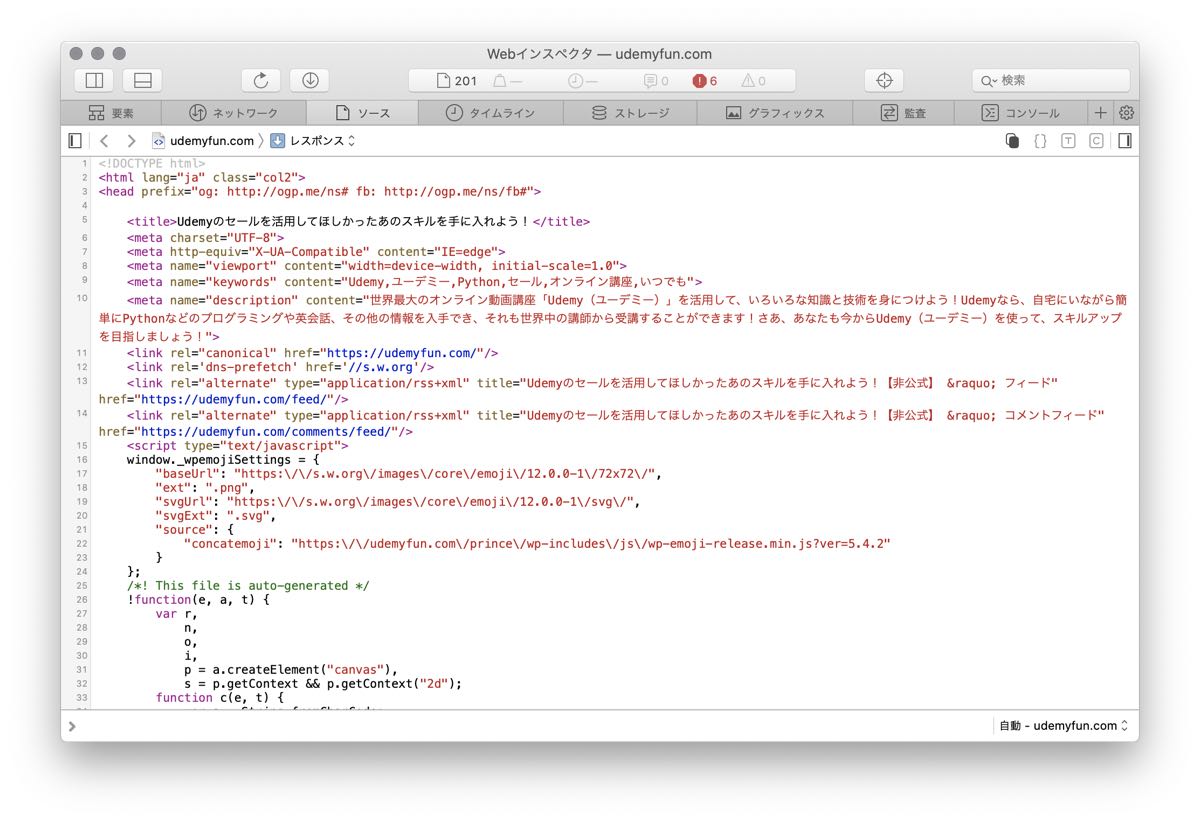
print(html.text)出力結果
<!DOCTYPE html>
<html lang="ja" class="col2">
<head prefix="og: http://ogp.me/ns# fb: http://ogp.me/ns/fb#">
<title>Udemyのセールを活用してほしかったあのスキルを手に入れよう!</title>
以下省略インポートしているBeautifulSoupとrequestsですが、このコードでは、BeautifulSoupは使っていません。
GETリクエストでudemyfun.comを取得して、取得したデータを出力しています。
出力は長くなるので、省略していますが、次のようなWebページのHTMLが出力されています。
次にBeautiful Soupを使ってデータを抜き出してみます。
from bs4 import BeautifulSoup
import requests
html = requests.get('https://udemyfun.com')
soup = BeautifulSoup(html.text, 'lxml')
titles = soup.find_all('title')
print(titles)出力結果
[<title>Udemyのセールを活用してほしかったあのスキルを手に入れよう!</title>]今回は、7行目でBeautifulsoupを使っていますが、HTMLの解析をするのに役立つlxmlライブラリを指定しています。
取得したsoupからtitleタグを見つけて取り出したデータをtitlesに入れて出力しています。
出力結果はリストに<title>タグで囲まれたデータが入ったものになります。
テキストだけ抽出
抽出したタイトルは、タグもはいっているので、テキストだけ抜き出してみます。
先程抽出したリストには、値が1つしか入っていないので、先程のコードの10行目を次のように変更すればテキストだけ抽出できます。
print(titles[0].text)class指定されたタグを抽出
次に、h2タグにclassを指定している部分を抽出してみましょう。
変更するのは9行目10行目です
h2title = soup.find_all('h2', {'class': 'section-title'})
print(h2title[0].text)h2にsection-titleとクラスをしているタグのテキストを抜き出します。
こちらのタグも1つしかないので、抽出したリストの1つ目の値をテキストで取り出しました。
出力結果は、次のようになります。
Udemyのセールでお得にオンライン学習!【非公式Udemyファンサイト】H2タグを抽出
最後に、H2タグをすべて抽出してみましょう
htwo = soup.find_all('h2')
for h in htwo:
print(h.text)出力結果
Udemyのセールでお得にオンライン学習!【非公式Udemyファンサイト】
世界最大のオンライン学習プラットフォームUdemy
驚きの講座数
自由な学びのスタイル
30日間返金保証で超安心!
学習スタイルが変わるオンライン講座
Udemy(ユーデミー)のセールはすごくおトク!
Udemyのセールはいつなの?
Udemyのセールは見逃すな!
関連記事クラスを指定しているタグも抽出できています。
アフィリエイトなどでは、上位表示を狙っているキーワードが上位のサイトからh2タグの文章などを参考にしたりしますが、Pythonを使うことでライバルサイトの分析もできちゃいますね。
スクレイピングは便利
Webサイトから必要な情報を抜き出すスクレイピングは非常に便利です。
ECサイトのように、APIを用意して、情報を提供してくれていれば、情報を有効活用できますが、Webからピンポイントで情報を抜き出すには、Webスクレイピングのスキルが必要になります。
どのように使うかは、自分次第なので、Webスクレイピングを有効活用していろいろな情報を収集・活用してみてください。
それでは、明日もGood Python!