Python学習【365日チャレンジ!】273日目のマスターU(@Udemy11)です。
トランプ大統領はいつになったら敗北を受け入れるんでしょうね。
報道によると、トランプ家の中でも、敗北を受け入れる派と受け入れない派に分かれているようですが、分断が得意なトランプ大統領は、家族をも分断してしまうんでしょうか?
日本に報道されるのは、民主党利権?まみれのメディア情報がほとんどとはいえ、正式な選挙の結果は受け入れたほうがいいんじゃないかと思いますけどね。
それでは、今日もPython学習を始めましょう。
昨日の復習
昨日は、ioストリームを使ってZipファイルの中のファイルをハードディスクに保存せずに確認する方法を学習しました。
Zipファイルをハードディスクに展開するのではなく、インメモリに記録して、必要な情報だけを入手し、インメモリを削除してくれるので、データ領域を有効に活用することができました。
詳細については昨日の記事をごらんください。

今日は、辞書型データをリストに入れて便利に扱えるChainMapを学習します。
maps
ChainMapは、collectionsライブラリのクラスで、辞書型データをまとめてしまうのではなく、個別に保有することができて、mapsを使えば辞書型データをリストとして扱うことができます。
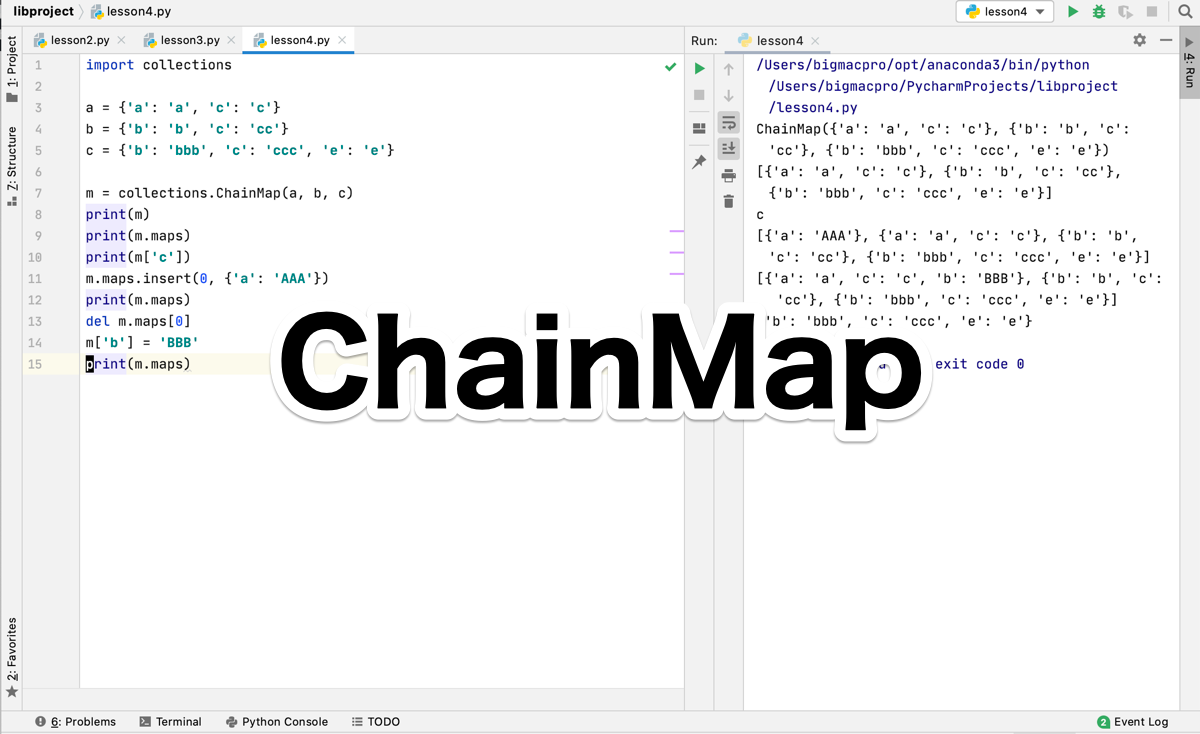
import collections
a = {'a': 'a', 'c': 'c'}
b = {'b': 'b', 'c': 'cc'}
c = {'b': 'bbb', 'c': 'ccc', 'e': 'e'}
m = collections.ChainMap(a, b, c)
print(m)
print(m.maps)出力結果
ChainMap({'a': 'a', 'c': 'c'}, {'b': 'b', 'c': 'cc'}, {'b': 'bbb', 'c': 'ccc', 'e': 'e'})
[{'a': 'a', 'c': 'c'}, {'b': 'b', 'c': 'cc'}, {'b': 'bbb', 'c': 'ccc', 'e': 'e'}]最初にcollectionsをインポートして、3行目から5行目で辞書型のデータa,b,cの3種類を定義しています。
7行目でChainMapの引数にa,b,cを代入したあと、mとm.mapsを出力しています。
出力結果を見るとわかりますが、mは、ChainMap()の中に辞書型データがそれぞれ保持されて、m.mapsは、リストの中に辞書型データが保持されています。
先頭データ優先
ここで、ChainMapのbを出力してみましょう
print(m['b'])出力結果
bChainMapのmには、keyがbのvalueを持った値がbだけでなくbbbもありますが、最初に格納されている辞書型データbのkeyがbであるvalueのbが出力されて、辞書型データcに入っているkeyがbのvaluebbbは出力されません。
つまり、ChainMapは、順序も記憶していて、異なる辞書型データに複数のkeyが存在する場合は、順番に格納されたうちの最初の辞書型データに含まれるkeyのvalueが返されます。
print(m['e'])に変更すると、1番目、2番めの辞書型データaとbには、eがkeyの値は存在しないので、3番めに格納されている辞書型データcのkeyeのvalueeが出力されます。
反対にしてみる
次に、格納されている辞書型データの順番をひっくり返してみます。
m.maps.reverse()
print(m.maps)出力結果
[{'b': 'bbb', 'c': 'ccc', 'e': 'e'}, {'b': 'b', 'c': 'cc'}, {'a': 'a', 'c': 'c'}]reverseメソッドは、順番を反対にしてくれますが、格納された辞書型データの順番をひっくり返すので、順番が入れ替わって辞書型データの値が出力されます。
次に、print(m['b'])を10行目に追加して実行してみると、辞書型データcが先頭になっているので、出力結果にbbbが追加されます。
insert
mapsはリスト型なので、値を挿入するinsertを使うことができます。
最初のコードの8行目以降を次のように変更してみます。
m.maps.insert(0, {'a': 'AAA'})
print(m.maps)出力結果
[{'a': 'AAA'}, {'a': 'a', 'c': 'c'}, {'b': 'b', 'c': 'cc'}, {'b': 'bbb', 'c': 'ccc', 'e': 'e'}]insertでmの先頭に辞書型データの{'a': 'AAA'}を追加したので、m.mapsを出力すると、先頭に挿入した辞書型データが追加されているのがわかります。
del
辞書型データの値を取り除くには、delを使います。
m.maps.insert(0, {'a': 'AAA'})
print(m.maps)
del m.maps[0]
print(m.maps)出力結果
[{'a': 'AAA'}, {'a': 'a', 'c': 'c'}, {'b': 'b', 'c': 'cc'}, {'b': 'bbb', 'c': 'ccc', 'e': 'e'}]
[{'a': 'a', 'c': 'c'}, {'b': 'b', 'c': 'cc'}, {'b': 'bbb', 'c': 'ccc', 'e': 'e'}]11行目の2回めのm.mapsの出力では、挿入した{'a': 'AAA'}が削除されているのがわかります。
値の更新
値の更新は、リストの更新と同じように、mのkeyを指定して=で値を入れてやります。
一番最初のコードの8行目から記述してみます。
m['c'] = 'CC'
print(m.maps)出力結果
[{'a': 'a', 'c': 'CC'}, {'b': 'b', 'c': 'cc'}, {'b': 'bbb', 'c': 'ccc', 'e': 'e'}]ChainMapmのkeyがcのvalueをCCに変更しているので、最初に入っている辞書型データaのkeyがcのvalueが上書きでCCに更新されます。
ちなみに最初の辞書型データaに存在しないkeyが指定された場合は、最初の辞書型データの最後に値が追加されます。
m['b'] = 'BB'
print(m.maps)出力結果
[{'a': 'a', 'c': 'c', 'b': 'BB'}, {'b': 'b', 'c': 'cc'}, {'b': 'bbb', 'c': 'ccc', 'e': 'e'}]まとめ
m.mapsはリストなので、順番を変えたり、追加したり、削除したり、値を更新したりすることができます。
通常の辞書型データは、updateを使って2つのデータを統合することはできますが、個別に値をリストにして保持できるChainMapはデータを加工して自由度の高い使い方ができるクラスです。
とはいえ、できること、できないことがあるので、公式ドキュメントを見れば詳しく知ることができますので、いろいろと試して、「これはできるんだな、あれはできないんだな」ということを理解するようにしましょう。
それでは、明日もGood Python!