Python学習【365日チャレンジ!】280日目のマスターU(@Udemy11)です。
寒くなると釣りに行くモチベーションが下がってしまいます。
もちろん水温も下がるので、魚たちはより安定した水温を求めて深場に移動するらしく、ぽかぽか陽気の秋に比べると釣果もかなり落ちてしまうんですよね。
10月には絶好調だったアオリイカもなかなかつれなくなって、年越しそば用のイカ天を確保しておこうと思っていたのに未だに確保できていません。
暖かい黒潮が流れる本州最南端の串本へ行ってみたいんですが、いつのことになるやら。。。
それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、タプルを拡張させたような使い方ができるnamedtupleを学習しました。
タプルは値を変更できないのが特徴ですが、同じような機能を持ったオブジェクトを作成できるのがnamedtupleです。
namedtupleの追加メソッドである_makeや_replaceは、他のメソッドとのコンフリクトを避けるため、先頭に_(アンダースコア)がついていました。
namedtupleの基本については、昨日の記事をごらんください。

今日は、namedtupleを使ってCSVファイルを活用する学習します。
CSVの復習
CSVファイルの取り扱いは、こちらの記事で学習しました。

CSVファイルからnamedtupleに値を取り込んで活用することができるのですが、CSVファイルの扱いを少し復習しておきましょう
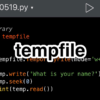
import csv
with open('names.csv', 'w') as csvfile:
fieldnames = ['first', 'last', 'type']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'first': 'Master', 'last': 'U', 'type': 'male'})
writer.writerow({'first': 'Taro', 'last': 'Yamada', 'type': 'male'})
writer.writerow({'first': 'Hanako', 'last': 'Tanaka', 'type': 'female'})
with open('names.csv', 'r') as f:
csv_reader = csv.reader(f)
header = next(csv_reader)
for row in csv_reader:
print(row[0], row[1], row[2])最初にCSVファイルを作成して、値を書き込んでいきます。
3行目でwithステートメントでCSVファイル(named.csv)を書き込みモードで作成し、2行目でヘッダの名前を変数fieldnamesに代入しています。
4行目でwiterオブジェクトを作成して、5行目でヘッダを、6行目から8行目でそれぞれの値を書き込んでいます。
10行目からは作成したCSVファイルを読み込んで、出力します。
10行目で作成したnames.csvを読み込みで開き、11行目でcsv_readerオブジェクトを生成します。
12行目は、ヘッダの出力をスキップするコードです。
13行目、14行目でforループを使って、CSVに入力されてる値を取り出して出力しています。
出力結果
Master U male
Taro Yamada male
Hanako Tanaka female14行目の出力コードは、print(row)だけでも出力できますが、['Master', 'U', 'male']のように、リストで3行表示されます。
namedtuple
続いてnamedtupleを使って同じ結果を出力してみます。
with open('names.csv', 'r') as f:
csv_reader = csv.reader(f)
Names = collections.namedtuple('Names', next(csv_reader))
for row in csv_reader:
names = Names._make(row)
print(names.first, names.last, names.type)先ほどのコードの2行目にimport collectionsを追加していますが、便宜上省略して、12行目からのコードだけ記述しています。
13行目までのcsv_readerオブジェクトを作るまでは同じコードになり、14行目でnamedtupleを使って、CSVに書き込んだヘッダーfieldnamesをnext(csv_reader)で引数field_nameに指定して、Namesという名前のサブクラスを作成します。
あとは、15行目でforループを使って_makeでnamesオブジェクトに値を入れて、16行目のprintでそれぞれのフィールドの値を取り出しています。
出力結果
Master U male
Taro Yamada male
Hanako Tanaka female出力結果はnamedtupleを使わない場合と同じになりますが、取り出したデータがnamedtupleに入っているので、さらにそれらの値を加工して活用することができます。
まとめ
結果だけを考えると、namedtupleを使って、わざわざややこしいやり方をする必要がないんじゃないかと思えてきますが、あくまでこのように使うという例を挙げているだけです。
なので、学習した先にあるもっと便利な使い方があるので、やっぱり実践に入らないとその便利さは感じられないかもしれません。
毎日ちょっとでも積み重ねていくことが重要なので、少しずつ自分のものにしていきましょう。
ということで、明日もGood Python!