Python学習【365日チャレンジ!】229日目のマスターU(@Udemy11)です。
Google翻訳の使い勝手が向上してから、他の翻訳ツールを使ってはいなかったのですが、iOS14の純正翻訳アプリとGoogle翻訳などと使い勝手を比較している記事があったので、ちらっとのぞいてみました。

いったいAppleは何をしているのか?というくらい、純正アプリのできの悪さにも驚きですが、Google翻訳よりも精度の高い【DeepL】という翻訳サイトを知って衝撃を受けています。
アプリではなくてWeb翻訳なのですが、Google翻訳よりも日本語っぽい翻訳をしてくれるので、Pythonのドキュメンテーションや英語のニュース記事などを読むのが楽になります。
iPhoneのホーム画面に登録して使えるので、ぜひ使ってみてください。
ホーム画面への登録方法はこちらの記事が参考になります。

それでは、今日もPython学習をはじめましょう。
昨日の復習
昨日は、他のマシンで走るプロセスをネットワーク越しに共有する方法について学習しました。
サーバーとクライアントのファイルを作成して、データのやり取りをしましたが、2つのクライアントのうち、データを受け取るほうが入力を待っている状態になっていたり、その状態でデータが入力されたらすぐにデータを受け取って出力されたりするコードを書いてみました。
ネットワークでのデータやり取りは、プログラムの醍醐味ともいえるので、いろいろとコードを変更しながら試してみました。
詳細については、昨日の記事をごらんください。

今日は、スレッドでの並列処理を簡単にできるThreadPoolExecutorを学習します。
concurrent.futures
threadingやmultiprocessingを使って、スレッドやプロセスの並列処理ができましたが、concurrent.futuresを使えば、より簡単にスレッドやプロセスの並列処理を扱うことができます。
まずは、Threadについて、concurrent.futuresを使った並列処理のコードを書いてみたいと思います。
import concurrent.futures
import logging
logging.basicConfig(
level=logging.DEBUG, format='%(threadName)s: %(message)s'
)
def worker(x, y):
logging.debug('start')
r = x * y
logging.debug(r)
logging.debug('end')
return r
if __name__ == '__main__':
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
f1 = executor.submit(worker, 2, 5)
f2 = executor.submit(worker, 2, 5)
logging.debug(f1.result())
logging.debug(f2.result())最初にconcurrent.futuresをインポートして、ロギングについてのコードは、これまで同様に、デバッグでスレッド名とメッセージが出力されるようなコードにしています。
if以下の実行コードには、ThreadPoolExecutorを使って、引数のmax_workersに2を指定して、います。
17行目、18行目で上記の関数workerをターゲットにして、2と5を引数に入れたオブジェクトf1、f2を作成して、19行目と20行目でworkerから返ってくる値を出力しています。
実行結果
ThreadPoolExecutor-0_0: start
ThreadPoolExecutor-0_0: 10
ThreadPoolExecutor-0_0: end
MainThread: 10
ThreadPoolExecutor-0_0: start
ThreadPoolExecutor-0_0: 10
ThreadPoolExecutor-0_0: end
MainThread: 10スレッド名がThreadPoolExecutorになって、start、10、endが出力されたあと、MainThreadで返り値の10が出力されています。
同じ出力をもう一回繰り返してプログラムが終了しています。
16行目のmax_workerは、並列処理ができるスレッドの数なので、この値を1にすると並列処理をせずに、一つ一つスレッドを処理していきます。
map
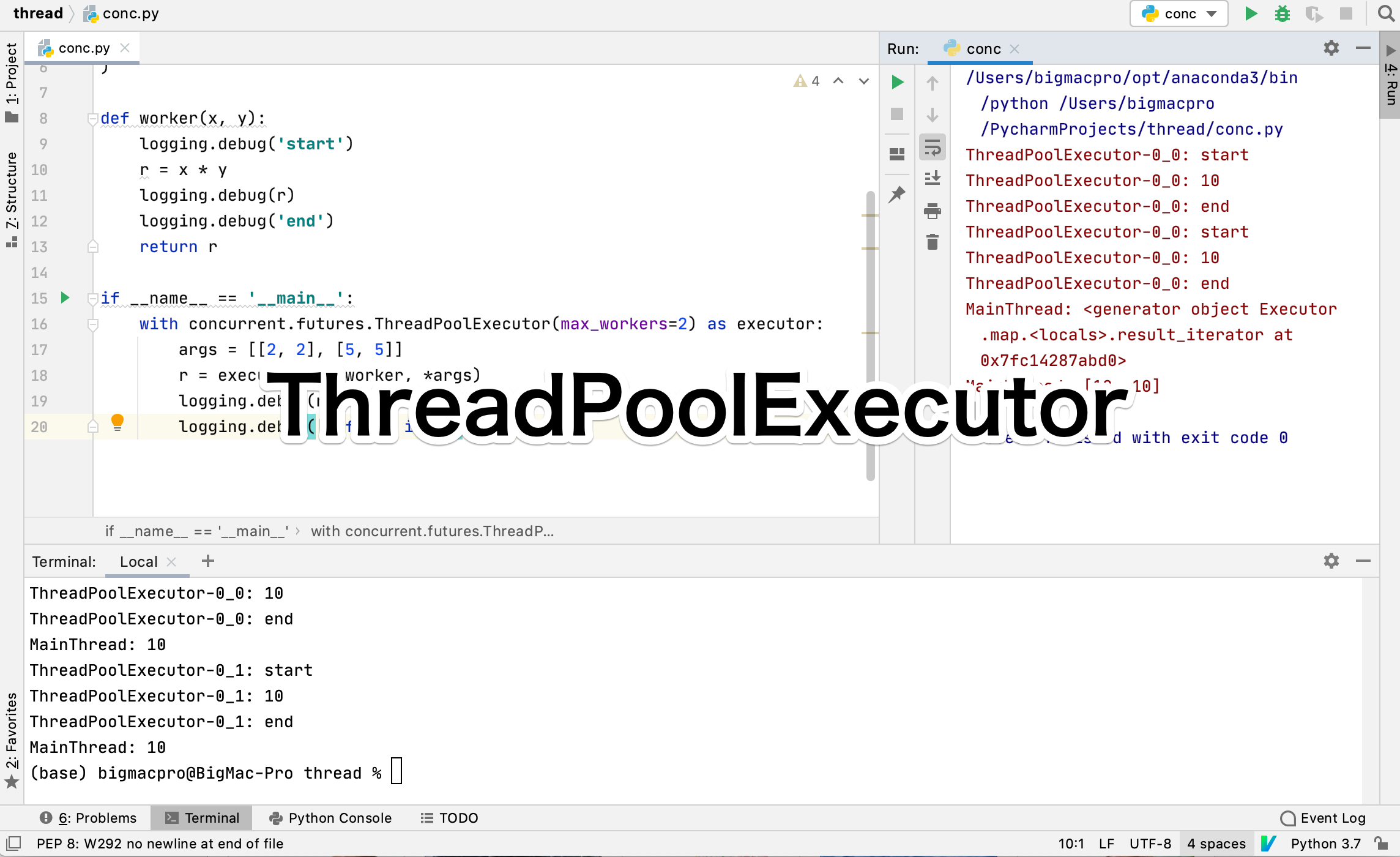
次は、ThreadPoolExecutorで、並列処理が終了してから次のコードの処理をするmapを使ってみましょう。
if __name__ == '__main__':
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
args = [[2, 2], [5, 5]]
r = executor.map(worker, *args)
logging.debug(r)
logging.debug([i for i in r])15行目からを変更します。
15行目のexecutorは同じで、16行目のリストargs引数を2つづつに入れています。
17行目でmapでターゲットをworkerと引数に*argsを指定して、rを出力、20行目でリスト内包表記で返り値をリストで返しています。
実行結果
ThreadPoolExecutor-0_0: start
ThreadPoolExecutor-0_0: 10
ThreadPoolExecutor-0_0: end
ThreadPoolExecutor-0_0: start
ThreadPoolExecutor-0_0: 10
ThreadPoolExecutor-0_0: end
MainThread: .result_iterator at 0x7fc14287abd0>
MainThread: [10, 10] 出力の7行目は、rを出力していますが、ジェネレーターオブジェクトで、イテレーターであることがわかります。
最終行で返り値がリストで出力されています。
色々試す
これまでのエントリーでもそうですが、サンプルコードを紹介していますが、関数の処理の間にtime.sleepを入れてみるとか、プリント出力してみるなど、ちょっとコードを変えて実行してみると、エラーが起こったり、出力が変わったりするので、色々と試してみてください。
ほんと、トライ&エラーは大切ですよ。
それでは、明日もGood Python!