Python学習【365日チャレンジ!】237日目のマスターU(@Udemy11)です。
本屋でプログラミング関係の本を眺めていると、「いちばんやさしGit&GitHubの教本」というのがあったので、購入して読み進めてみました。
GitHubという言葉は知っているし、プログラムをダウンロードしたこともあるのですが、GitにしてもGitHubにしてもいまいちどういうものなのか理解していませんでした。
本を読んでもいまいちその利便性がわかりづらく、Gitがコマンドを使ったファイル管理程度にしか理解できませんでした。
バージョン管理ができるというところがいいのか、GUIを使わないから処理が速くていいのかよくわからないのですが、Dropboxでも他のクラウドサービスでもファイルを共有して共同作業ができるので、メリットがいまいち理解できないんですよね。
プログラマーにとっては必要不可欠なツールだとは思うので、そのうち使ってみようとは思っているのですが、なにぶんPython学習で手一杯なので、一息ついたら取り組んでみようと思います。
それでは、今日もPython学習をはじめましょう。
昨日の復習
昨日は、ファイルを暗号化、復号化する方法を学習しました。
ファイルの暗号化・複合化は、任意の文字列の暗号化・複合化と同じように使うことができました。
withステートメントでファイルを開き、アスキーコードの文字列を使い、AES.MODE_CBCアルゴリズムで暗号化したあと、別のファイルを作ってデータを保存しました。
複合化についても同じアルゴリズムを使って暗号化されたデータを複合化してファイルに保存しました。
詳細については、昨日の記事をごらんください。

今日は、hashlibを使ったハッシュ化を学習します。
hashlib
ハッシュと聞くと、ハッシュタグとハッシュドビーフが思い浮かびます。
Pythonで使うハッシュは、「寄せ集め」の意味のハッシュで、任意のデータを固定されたランダムに思えるハッシュ値に不可逆変換して置き換えたものです。
AESは、暗号化することができて、暗号化されたデータを復号化してもとに戻すことができましたが、ハッシュの場合は、ある文字列をハッシュ値には変換できるけどハッシュ値からもとの文字列に変換することができません。
今回学習するhashlibは、データをハッシュ化するための標準ライブラリで、SHA1、SHA224、SHA256、SHA384、SHA512、RSA、MD5といったアルゴリズムを利用してデータをハッシュ値に変換することができます。
ハッシュ化が暗号化とちがうのは、、ハッシュ化したハッシュ値をもとの値に復元することができないところです。
ただ、ハッシュ化するデータが同じであれば、生成されるハッシュ値は同じになります。
早速コードを書いていきましょう。
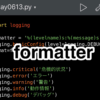
import hashlib
print(hashlib.sha256(b'udemyfun').hexdigest())
print(hashlib.sha256(b'udemyfun').hexdigest())
print(hashlib.sha256(b'udemyf').hexdigest())出力結果
04dfaac4b48be67d60b866a23a99814d168f59175573adccc0f8730b2064994e
04dfaac4b48be67d60b866a23a99814d168f59175573adccc0f8730b2064994e
583e17796e6a79e518b3b699d5fac2e9b758fea3904fed4937af0753e2c26759コードの3行目と4行目は同じデータ(udemyfun)をsha256というアルゴリズムでハッシュ化して、hexdigestで16進数の値(ダイジェスト値)を返しています。
出力を見るとどちらの行も同じハッシュ値になっているのがわかるかと思います。
コードの5行目はudemyにしているので、他の2つとはちがうハッシュ値が返されています。
ハッシュ化の使用例
最もメジャーなハッシュ化の使用例が、IDとパスワードを使ったログイン処理です。
実際にIDとパスワードを作成して、リストに保存したあと、IDとパスワードのチェックができるか確認してみましょう。
import hashlib
user_name = 'user1'
user_pass = 'abcdefgh'
db = {}
def get_digest(password):
password = bytes(user_pass, 'utf-8')
digest = hashlib.sha256(password).hexdigest()
return digest
db[user_name] = get_digest(user_pass)
def is_login(user_name, password):
return get_digest(password) == db[user_name]
print(db)
print(is_login(user_name, user_pass))3行目から5行目で、変数user_nameとuser_passに値を代入して、それらを保存する空の辞書型データdbを作成します。
関数get_digestの引数にpasswordを指定し、変数user_passをutf-8でバイトに変換します。
そのあと、passwordをsha256で16進数のハッシュ値(digestに変換し、返り値に指定します。
12行目でdbにハッシュ化されたpasswordをuser_nameと一緒にキーバリューで保存しています。
14行目の関数is_loginは、user_nameとpasswordを引数で受け取って、dbに保存されているキーバリューと同じかどうかを判断して返り値にしています。
最後にdbと関数is_loginの引数にuser_nameとuser_passを代入した返り値を出力しています。
出力結果
{'user1': '9c56cc51b374c3ba189210d5b6d4bf57790d351c96c47c02190ecf1e430635ab'}
True最初に設定したuser_nameとuser_passをそのままis_loginでも使っているので、最後の返り値は当然Trueになっています。
最後のコードのis_login(user_name, user_pass)の引数を変えてis_login(user_name, 'password')とすれば、Falseが返ってきて、ログインできない状況になるということです。
まとめ
普段なにげなしに使っているIDとパスワードを使ったログインの仕組みがなんとなくわかったような気がしませんか?
データベースに保存しているが、生のユーザーIDとパスワードだった場合は、情報漏えいがあった場合はすぐさまログインが可能になってしまいますが、パスワードがハッシュ化されていることで、あらゆる文字のハッシュ値対応表を持っていない限り、不正ログインされることはありません。
暗号化は復号化が前提ですが、ハッシュ化はもとの値に復元できないので、セキュリティーに優れているため、多くのシステムで活用されています。
よりセキュリティーを高めるためのハッシュ化の方法があるのですが、今日はここまでにして、明日、その方法を学習したいと思います。
それでは明日もGood Python!