Python学習【365日チャレンジ!】318日目のマスターU(@Udemy11)です。
世間ではこの日をクリスマスといいますが、プレゼントはサンタから届きましたか?
私のサンタは私なので、ビッグフィッシュを入れられるクーラーを贈ってあげました。
といっても、使う機会があるかどうかは微妙なところです。
この時期はヒラメが釣れるらしいので、近場でヒラメが釣れているという釣果情報があったポイントへちょくっと行ってきたのですが、
安定の異常なし
状態で、2時間ほどキャストし続けるという筋力トレーニングをこなしました。
トボトボ歩いて移動しながらなので、それなりにカロリーを消費したと思うのですが、体重は全く減っていませんでした。
それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、ランダムな配列の作り方や行列の操作について学習しました。
randomを使って任意の範囲の値の配列を作成したり、行列の入れ替えをしたり、配列の合計や平均を出したりすることができました。
random_sampleにエイリアスが3つあって同じ処理ができることやrandintで任意の整数の範囲からランダムに値を抽出して配列を作成することも学習しました。
くわしくは、昨日の記事をごらんください。

今日は、データ解析の前処理ができるPandasを学習します。
Pandasとは
Pandasは、Numpyと同じく、データ解析を効率よく処理するためのライブラリで、データの読み込み、統計量の表示、グラフ化など、データ解析の9割を占めると言われている【前処理】を高速に処理することができます。
Pandasは、NumpyやMatplotlibと並んで、Pythonのデータ解析には必要不可欠なライブラリになっています。
これら3つを含むデータ解析に必要なライブラリのインストールはpipでインストールできますので、こちらの記事を参考にしてみてください。

そういえば、Numpyの記事ではインストールについてふれませんでしたが、Anacondaをインストールした時点で主要なライブラリがインストールされていたような気がするので、これらのライブラリのインストールは必要ないのかもしれません。
Series
早速Pandasを使っていきたいとおもいます。
Pandasパッケージのモジュールは、Numpyをインポートして使用していますので、基本的にNumpyと組み合わせて使います。
import numpy as np
import pandas as pd
s = pd.Series([1, 2, np.nan])
s
# 0 1.0
# 1 2.0
# 2 NaN
# dtype: float64Seriesは、値を指定するだけで、インデックスの付いた1次元の配列を作成してくれます。
このコードでは、np.nanを使ってnanを含む3つの値の入った配列が作られます。
Numpyと同じように、値を抽出したり、合計や平均を出すことができます。
s[0]
# 1.0
s.sum()
# 3.0
s.mean()
# 1.5
s.max()
# 2.0他にも使えるメソッドがたくさんあるので、s.と入力したあと、tabキーを押すと、使えるメソッドが表示されます。
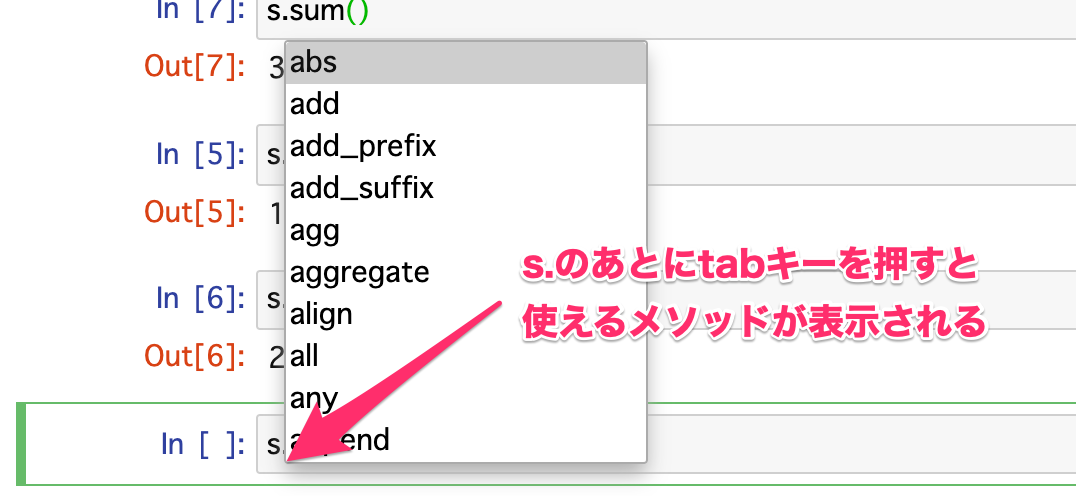
めっちゃたくさんあるので、いろいろ試してみてください。
DataFrame
DataFrameは、2次元の配列オブジェクトを作成するクラスです。
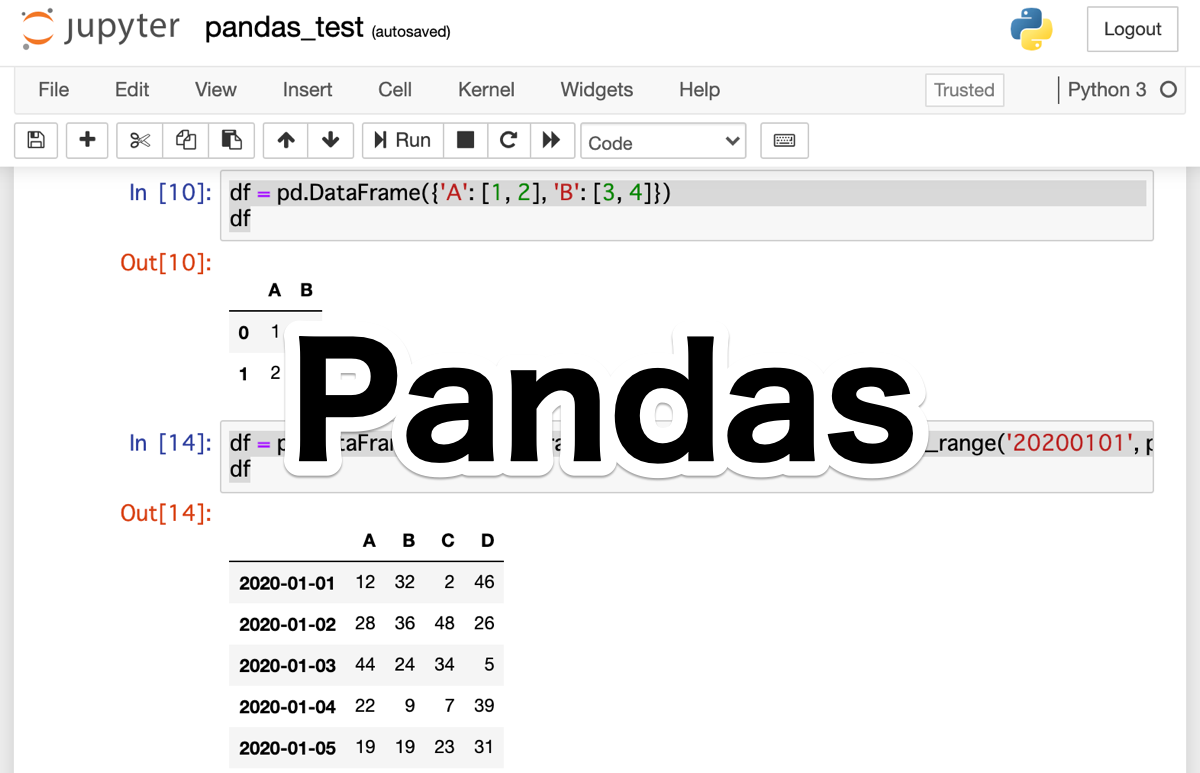
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df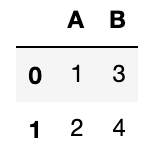
2次元の2行2列の配列を、エクセルの表のように見やすく表示してくれます。
次に、ランダムに作成する整数の配列を作成し、行列の見出しをつけてみます。
df = pd.DataFrame(np.random.randint(1, 50, (6, 4)), index=pd.date_range('20200101', periods=6), columns=['A', 'B', 'C', 'D'])
df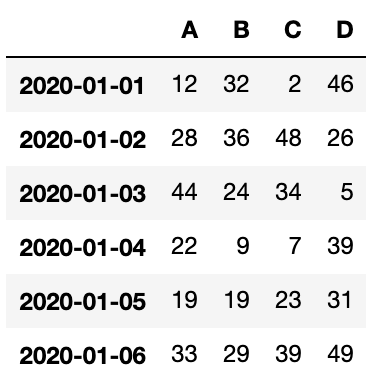
np.random.randint(1, 50, (6, 4))で1から50までの整数をランダムに選んだ6行4列の配列を作り、引数indexで、2020-01-01から続く6つの日付を行の見出しにして、columnsで列の見出しをアルファベットに指定しています。
head
headを使えば、配列の先頭行だけを表示することもできます。
df.head(1)
tail
tailは、後ろから指定した行数を表示することができます。
df.tail(2)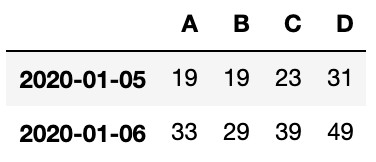
index
indexは、行の見出しを出力します。
df.index
# DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
# '2020-01-05', '2020-01-06'],
# dtype='datetime64[ns]', freq='D')columns
columnsは、列の見出しを取り出すことができます。
df.columns
# Index(['A', 'B', 'C', 'D'], dtype='object')values
valuesは、値のみを配列で取り出すことができます。
df.values
# array([[12, 32, 2, 46],
# [28, 36, 48, 26],
# [44, 24, 34, 5],
# [22, 9, 7, 39],
# [19, 19, 23, 31],
# [33, 29, 39, 49]])T
numpyのTと同じように、行列の入れ替えをすることができます。
df.T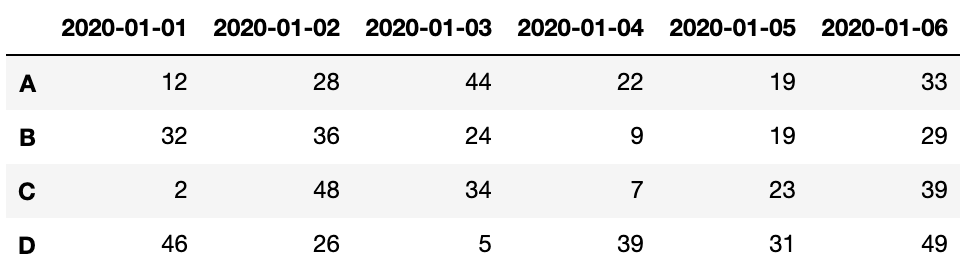
describe
describeは、各列の値の数や平均、標準偏差や最大値、最小値などを一覧にして取得することができます。
df.describe()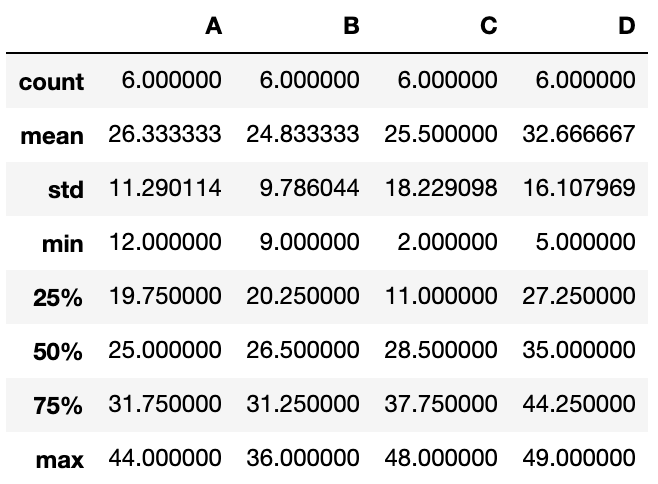
sort_values
sort_valuesを使って、指定した見出しの列を昇順に並べ替えることができます
df.sort_values(by='B')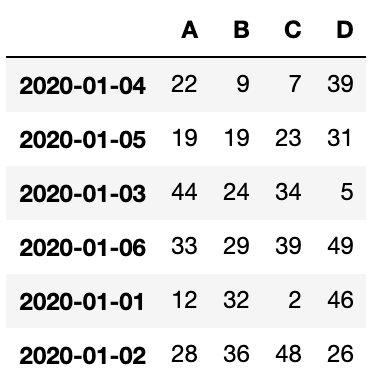
B列を基準にして昇順に並べ替えています。
まとめ
Pandasの基本的な使い方はもっとたくさんありますが、今日は、一旦ここで終了します。
あまりに一気にたくさんのことを学習すると、先に習ったことを忘れてしまうので、少しずつあたまに入れていったほうが最終的に効率よく理解が進むかと思います。
Numpyと共通する部分があるので、Numpyをしっかりと理解できていれば、Pandasもそれなりに理解できるでしょう。
「1日1歩、3日で3歩、3歩歩いて2歩下がる」くらいののんびりした考え方で、地に足を付けて学習していきましょう!
それでは、明日もGood Python!