Python学習【365日チャレンジ!】105日目のマスターU(@Udemy11)です。
昨日、【JIN-仁-】の漫画について触れましたが、Python学習が終わってから何気なくAmazonプライムで検索してみると、シーズン1と完結編が出てきたので、ついつい観てしまいました。
Youtubeのように、再生速度を2倍とかにできないので、全部観るにはめっちゃ時間がかかりそうです。
当分寝不足は避けられませんね。。。
それでは今日もPython学習をすすめていきましょう!
昨日の復習
昨日は、1人目と2人目の質問の処理までカバーできるコードを書いてみました。
2人目からは条件分岐が必要になるので、1人目だけの質問より少しむずかしいコードが必要でしたね。
条件分岐は次のような感じでした。
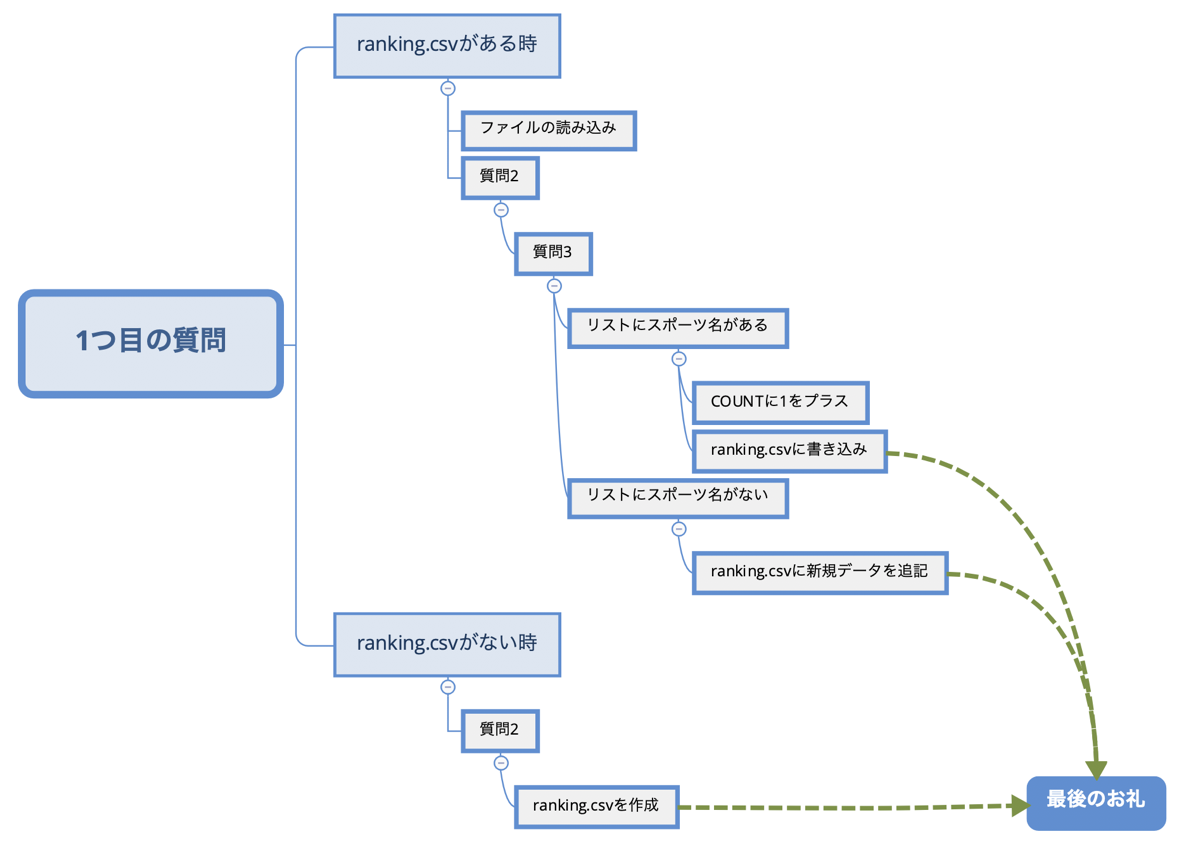
3人目の質問については、もう少し複雑な条件分岐が考えられますが、4人目以降でも同じ条件分岐で対応できるので、今日で一旦この対話アプリケーションは完成となる予定です。
それでは、コードを書いていきましょう!
読み込むライブラリ
読み込むライブラリは、Vol.3でもインポートしたcsv、osに加えて、operatorを加えた3つになります。
import csv
import operator
import os今回始めて出てくるoperatiorモジュールは、読み込んだCSVをCOUNTの値の多い順に並べるために使います
最初の質問と最後のお礼
最初の質問とranking.csvの有無チェックと最後のお礼は、何人目の質問でも同じように使うので、最初と最後に記述します。
name = input('こんにちは。私はジャービスです。あなたの名前を教えてください。\n')
c_name = name.title()
check = os.path.exists('ranking.csv')
# メインで処理するコード
print('\n{}さん、回答ありとうございました。\n良い1日をお過ごし下さい!'.format(c_name))importの行は省いて記述しています。
最初の質問と、最後のお礼の間に、メインで処理するコードが入りますので、順番に処理コードを書いていきます。
条件分岐
ここからがメインで処理するコードになりますが、まずは、最初の条件分岐です。
ranking.csvが存在するかどうか条件分岐のコードは、2人目のときのコードと同じです。
if check is True:
# ranking.csvが存在するときの処理
else:
# ranking.csvが存在しないときの処理
# (一人目の2つ目の質問とCSVの作成・書き込み)2人目のコードと違うところは、ranking.csvが存在するときの処理です。
続いてranking.csvが存在するときのコードを書いていきます。
CSVの読み込みとソート
ranking.csvを読み込んだあとは、JarvisがおすすめするスポーツをCOUNTの値が大きい順に並べて順番に抽出するための準備をします。
ranking.csvの読み込みは2人目のときと同じですが、新たに並び替えて順番に抽出できるジェネレーターを準備します。
with open('ranking.csv', 'r') as rank_r:
ranking = csv.DictReader(rank_r)
result = sorted(ranking, key=operator.itemgetter('COUNT'), reverse=True)
recommend = (i['NAME'] for i in result)前回のコードと違うところは、sorted()関数を使って、変数rankingをoperator.itemgetter()で取り出したCOUNTの降順に並び替えたあと、ジェネレーターのrecommendを作成しているところです。
ジェネレーターで順番に取り出す
次に、JarvisがCOUNTの数が多い順に、そのスポーツが好きかどうかを尋ねます。
答えがYesかNo、もしくはそれ以外の回答によって、条件を分岐させたループで処理します。
c_rec = next(recommend)
try:
while True:
you_like = input('\nわたしがおすすめするスポーツは、{}です。\nあなたはこのスポーツが好きですか? [Yes/No]\n'.format(c_rec))
if 'Y' in str.upper(you_like):
break
elif 'N' in str.upper(you_like):
c_rec = next(recommend)
continue
else:
print('\nYes か Noで答えてください')
except StopIteration:
passスポーツを一つずつ取り出せるのがジェネレーターで、next()を使って取り出した値を変数c_recに代入します。
質問に対してYesが返された場合は、ループを抜けて次の質問へ、Noの場合は、next(recommend)で次のスポーツについて質問をします。
回答がYesかNo以外の場合は、YesかNoで答えるよう出力したあと、同じ質問を繰り返します。
whileループの中に最初のnext(recommend)を入れてしまうと、YesかNo以外の入力をしたときのループで次のスポーツが代入されてしまうため、whileループの外に入れています。
try except文を使っているのは、ジェネレータの値をすべて使ったあとのエラーを処理するためです。
大好きなスポーツ
最後の質問についての処理は、昨日書いたコードと全く同じになります。
この部分のコードについては、昨日の記事を参考にしてください。

流れとしては、次のような感じです。
- 質問でスポーツ名を取得
- 書き込むためのデータを整理
- 条件に応じたデータをCSVに書き込む
という感じで、完成したコードをみてみましょう、
完成したコード
# 簡単なアプリケーション対話ロボット
import csv
import operator
import os
name = input('こんにちは。私はジャービスです。あなたの名前を教えてください。\n')
c_name = name.title()
check = os.path.exists('ranking.csv')
if check is True:
with open('ranking.csv', 'r') as rank_r:
ranking = csv.DictReader(rank_r)
result = sorted(ranking, key=operator.itemgetter('COUNT'), reverse=True)
recommend = (i['NAME'] for i in result)
c_rec = next(recommend)
try:
while True:
you_like = input('\nわたしがおすすめするスポーツは、{}です。\nあなたはこのスポーツが好きですか? [Yes/No]\n'.format(c_rec))
if 'Y' in str.upper(you_like):
break
elif 'N' in str.upper(you_like):
c_rec = next(recommend)
continue
else:
print('\nYes か Noで答えてください')
except StopIteration:
pass
sports = input('\n{}さん、あなたの大好きなスポーツは何ですか?\n英語で答えてください\n'.format(c_name))
c_sport = sports.title()
rank_r.seek(0)
sport_data = []
for i in ranking:
if i['NAME'] == c_sport:
num_s = i['COUNT']
count_s = int(num_s) + 1
i['COUNT'] = count_s
sport_data.append(i)
check_sport = []
for i in sport_data:
check_sport.append(i['NAME'])
if c_sport not in check_sport:
with open('ranking.csv', 'a') as new_d:
writer = csv.writer(new_d)
writer.writerow([c_sport, 1])
else:
with open('ranking.csv', 'w') as add_d:
fieldnames = ('NAME', 'COUNT')
writer = csv.DictWriter(add_d, fieldnames=fieldnames)
writer.writerows(sport_data)
else:
sports = input('\n{}さん、あなたの好きなスポーツは何ですか?\n英語で答えてください\n'.format(c_name))
c_sport = sports.title()
with open('ranking.csv', 'w') as rank_csv:
fieldnames = ('NAME', 'COUNT')
writer = csv.DictWriter(rank_csv, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'NAME': c_sport, 'COUNT': 1})
print('\n{}さん、回答ありとうございました。\n良い1日をお過ごし下さい!'.format(c_name))改良の余地はありまくり
ということで、課題の対話アプリケーションを完成することはできましたが、このコードは、とりあえず与えられた課題をこなせるというだけのコードです。
昨日も気になったwithステートメントでファイルを開くコードの中にさらにwithステートメントでファイルを開いているというコードになってしまっているため、改善の余地はたくさんありそうです。
次回は、オブジェクト指向ということで、Jarvisというクラスが質問をしたり、ファイルを読み込んだり、書き込んだりするメソッドを持っているようなコードを書いてみようと思います。
今回のコードと同じように、1人目の質問のコードから作っていきたいと思います。
それでは、明日もGood Python!