Python学習【365日チャレンジ!】143日目のマスターU(@Udemy11)です。
ここ数日のデータベース操作で、これまで持っていたデータベースに関するとっつきにくさがなくなってきているように感じます。
ターミナルでデータベースを操作することに慣れてきて、データベース操作が楽しくなってきています。
まだまだ一部の内容しか学習できていないので、レクチャーの内容に加えて一つでも自分のものにできるようコードやコマンドを打ち込んでいると、知らない間に時間が経っちゃうんですよね。
ということで、今日もPython学習を始めましょう。
昨日の復習
3日にわたって、最も有名なリレーショナルデータベースであるMySQLについて学習しました。
MacにMySQLをインストールして、Pythonからデータベースにアクセスしてデータをやり取りしましたが、SQL文は簡易なデータベースであるSQLiteと同じように扱うことができました。
ただ、ほとんどのレンタルサーバーは、セキュリティーの関係で自社サーバー以外からのアクセスを拒否しているので、レンタルサーバー内に置いたPythonからデータベースを扱う必要がありました。
初日は、MySQLのインストールから始まって、ターミナルでMySQLの新しいユーザーを作成し、作成したユーザーへデータベースを扱う権限を与えてから、2日目でPythonファイルを使ってMySQLを操作しました。
操作については、SQLiteと同じような扱い方でしたが、微妙に命令文が違うところもありましたね。
さらに、2日目でかなりハマってしまったところがあったので、3日目はハマったポイントを健忘録として残しておきました。
学習したMySQLの詳細については次の3つの記事をごらんください。

今日は、SQLAlchemyについて学習しましょう!
SQLAlchemyとは
SALAlchemyは、誰が判断したかはわかりませんが、Pythonでもっとも使用されている【ORM(Object relational mapping)】です。
ORMは、次のような機能を備えたものです。
- データベースからデータを取得する
- 取得したデータからオブジェクトを生成する
- オブジェクトを使ってデータベースを操作する
オブジェクトがデータベース合わせてSQL文を生成して、データベースとつなげてくれるので、操作するデータベースを変更するだけで同じ操作を実行することができるすぐれものです。
SQLAlchemyが扱えるデータベースには次のようなものがあります。
- Microsoft SQL Server
- MySQL
- Oracle Database
- PostgreSQL
- SQLite
有名どころのデータベースは大抵が利用可能ということですね。
それでは実際にSQLAlchemyを使って、データベースを操作してみましょう。
SQLAlchemyとPyMySQLのインストール
まず最初に、サードパーティーライブラリから2つのパッケージをインストールします。
PycharmのPreferencesからProject Interpreterを選んで+をクリックします。
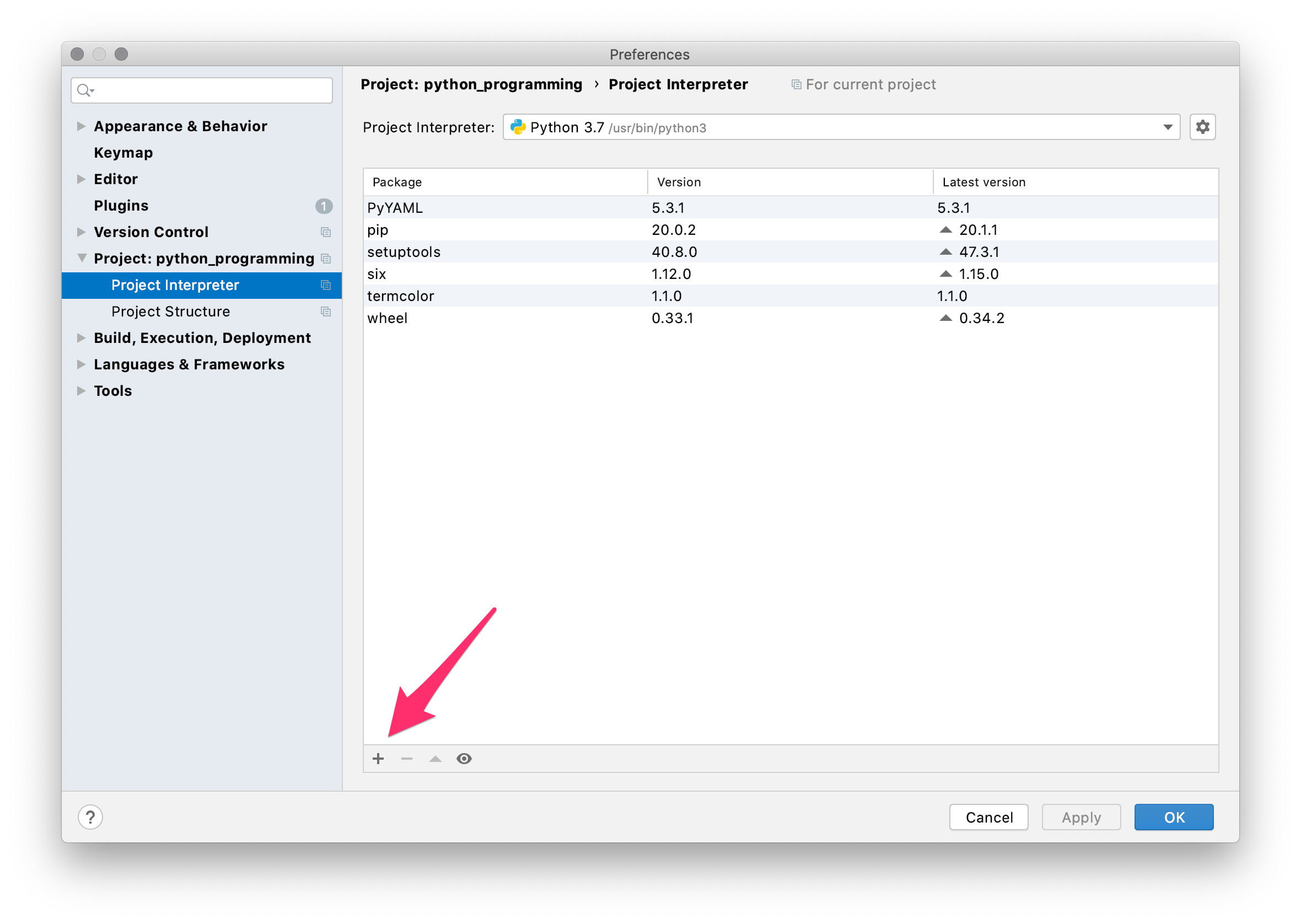
次に検索窓にsqlalchemyと入力して、左のメニューから【SQLAlchemy】を選んで、【Install Package】をクリックします。
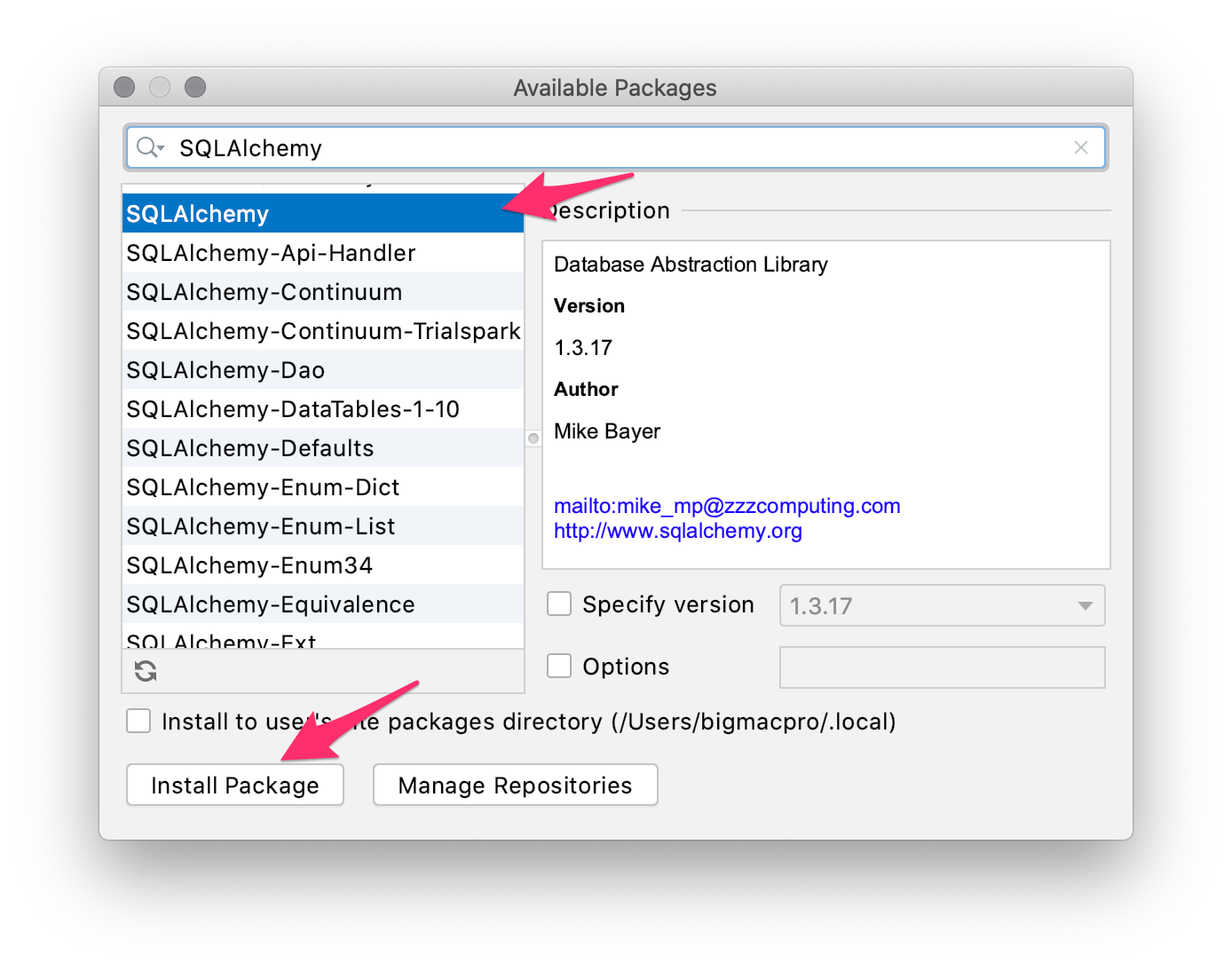
少し時間が経つとインストールが完了した表示が出るので、続いて検索窓にpymysqlと入力し、左メニューの【PyMySQL】を選んで【Install Package】をクリックします。
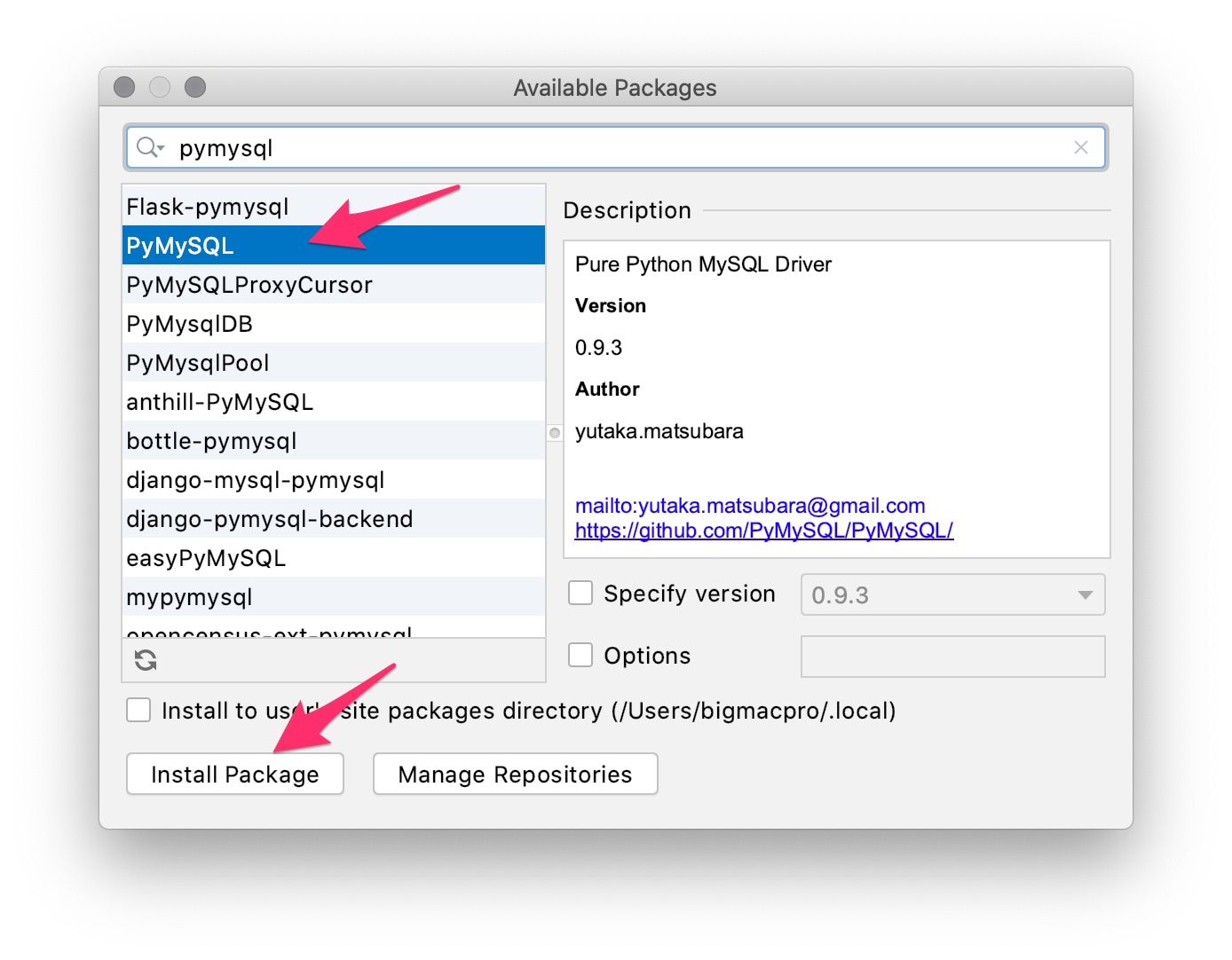
インストールが完了したら、開いているウインドウを閉じてSQLAlchemyとPyMySQLがインストールされているのを確認して、右下の【OK】をクリックします。
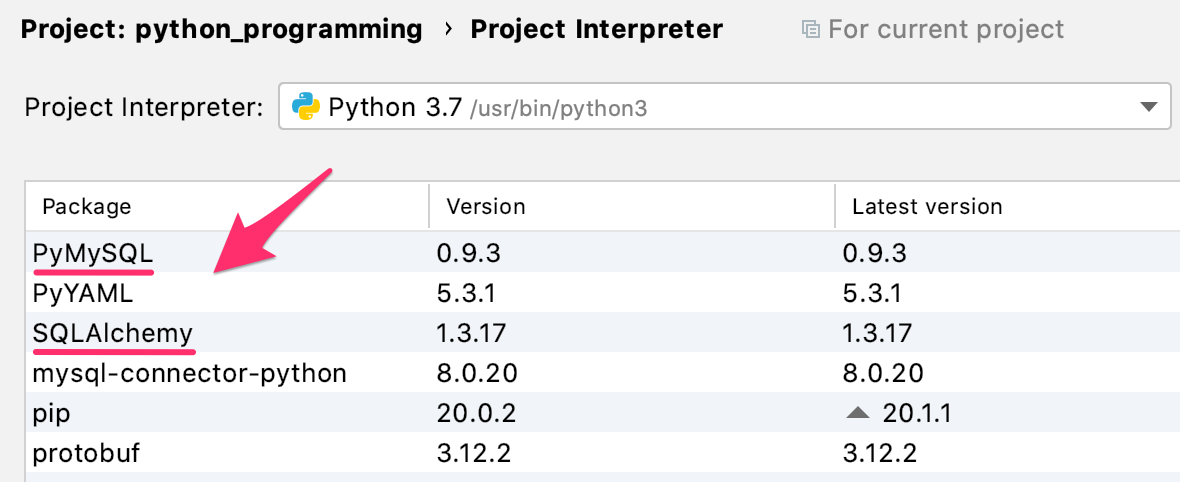
これでSQLAlchemyを使ってPythonからデータベースを操作する準備が整いました。
メモリーで実行
SQLiteを使いますが、今日はメモリーにSQLiteのデータベースを作成します。
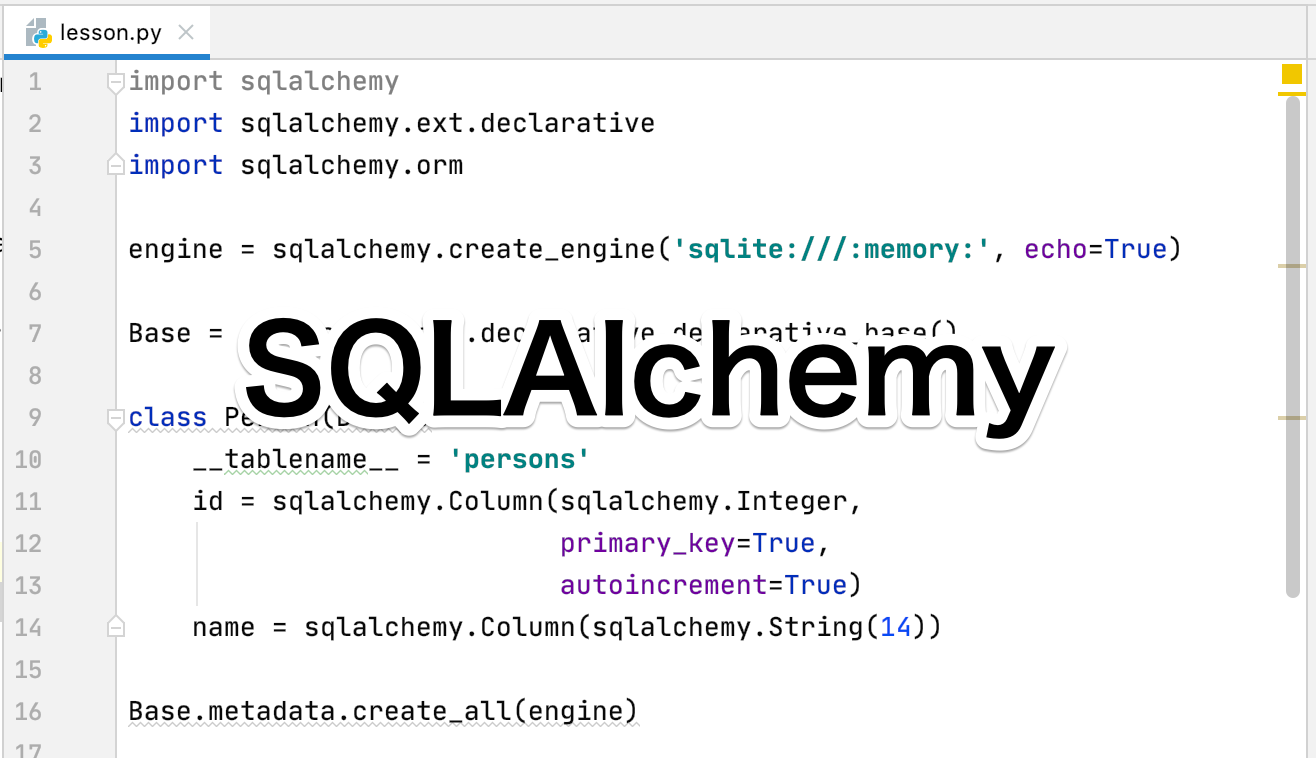
import sqlalchemy
import sqlalchemy.ext.declarative
import sqlalchemy.orm
#接続URLを使ってデータベースに接続
engine = sqlalchemy.create_engine('sqlite:///:memory:')
#データベースを扱うベースクラスを作成
Base = sqlalchemy.ext.declarative.declarative_base()
#ベースクラス(Base)を継承したPersonクラスを定義
class Person(Base):
__tablename__ = 'persons'
id = sqlalchemy.Column(sqlalchemy.Integer,
primary_key=True,
autoincrement=True)
name = sqlalchemy.Column(sqlalchemy.String(14))
#Personクラスで定義したテーブル情報をengineでメモリーに記録
Base.metadata.create_all(engine)一連の流れは、コメントで記述していますが順番にみていきましょう。
最初に必要なモジュールをインポートします。
次に、コネクターと同じような働きをするengineを定義します。
9行目でデータベースを扱うためのベースクラスを作って、12〜17行目でデータベースのテーブル情報を入れて、ベースクラスを継承したPersonクラスを定義します。
最後に、定義したテーブルをengineに渡してデータベースを作成します。
このコードを実行すれば、メモリー上にデータベースが作成されます。
レコードを追加
先程のコードは、メモリー上に書き込んでいるだけなので、実行したあとはデータベースも消去されます。
見た目上は何もおこらないので、何をしたのかよくわかりませんよね。
なので、上記のコードにレコードを追加して表示するコードを付け足します。
import sqlalchemy
import sqlalchemy.ext.declarative
import sqlalchemy.orm
engine = sqlalchemy.create_engine('sqlite:///:memory:')
Base = sqlalchemy.ext.declarative.declarative_base()
class Person(Base):
__tablename__ = 'persons'
id = sqlalchemy.Column(sqlalchemy.Integer,
primary_key=True,
autoincrement=True)
name = sqlalchemy.Column(sqlalchemy.String(14))
Base.metadata.create_all(engine)
#データベースに書き込むための準備
Session = sqlalchemy.orm.sessionmaker(bind=engine)
session = Session()
#レコードを追加
person1 = Person(name='Mark')
session.add(person1)
person2 = Person(name='Kate')
session.add(person2)
person3 = Person(name='Alex')
session.add(person3)
session.commit()
#データベースのレコードを取得して表示
persons = session.query(Person).all()
for person in persons:
print(person.id, person.name)追加した19行目20行目のsessionは、これまでのカーソルと同じような役割ですね。
23〜29行目は、3つのレコードを追加していますが、これまでのexecuteの役割と同じで、29行目のsession.commit()でデータベースに書き込んでいます。
最後の3行は、保存されたレコードをコンソールに表示するためのコードで、出力結果は次のようになります。
1 Mark
2 Kate
3 Alex続いて、レコードの変更と削除のコードを学習します
レコードの変更と削除
上記のコードの31行目に次の7行を挿入します。
person4 = session.query(Person).filter_by(name='Mark').first()
person4.name = 'Michel'
session.add(person4)
person5 = session.query(Person).filter_by(name='Kate').first()
session.delete(person5)
session.commit()31〜33行目はpersonsテーブルの中からnameがMarkの最初のレコードを見つけてMichelに変更するコードです。
35〜37行目は、personsテーブルの中からnameがKateの最初のレコードを見つけて削除するコードです。
37行目のsession.commit()でデータベースを保存しています。
記述していませんが、38行目以降のテーブルを抽出してコンソールに表示するコードは前のコードと同じで、出力結果はMarkがMichelに変更されて、Kateのレコードが削除されています。
1 Michel
3 AlexSQL文が不要
SQLAlchemyでデータベースを扱ってきましたが、今日はメモリー上にSQLiteのデータベースを作成して操作してみました。
メモリー上にデータベースを作るため、実行のたびにクリアーされて新しくデータベースが作成されるので、テーブルを作成するコードがそのままでも、コードが間違っていなければ、何度実行してもエラーは起こりません。
今回のコードに、SQL文は記述されていませんが、SQLAlchemyがSQL文を生成して実行しているので、その実行過程をコンソールに表示する方法があります。
実行コード5行目のengineオブジェクトを生成する際の引数にecho=Trueを付け加えることで、実行したSQL文などがすべてコンソールに表示されます。
engine = sqlalchemy.create_engine('sqlite:///:memory:', echo=True)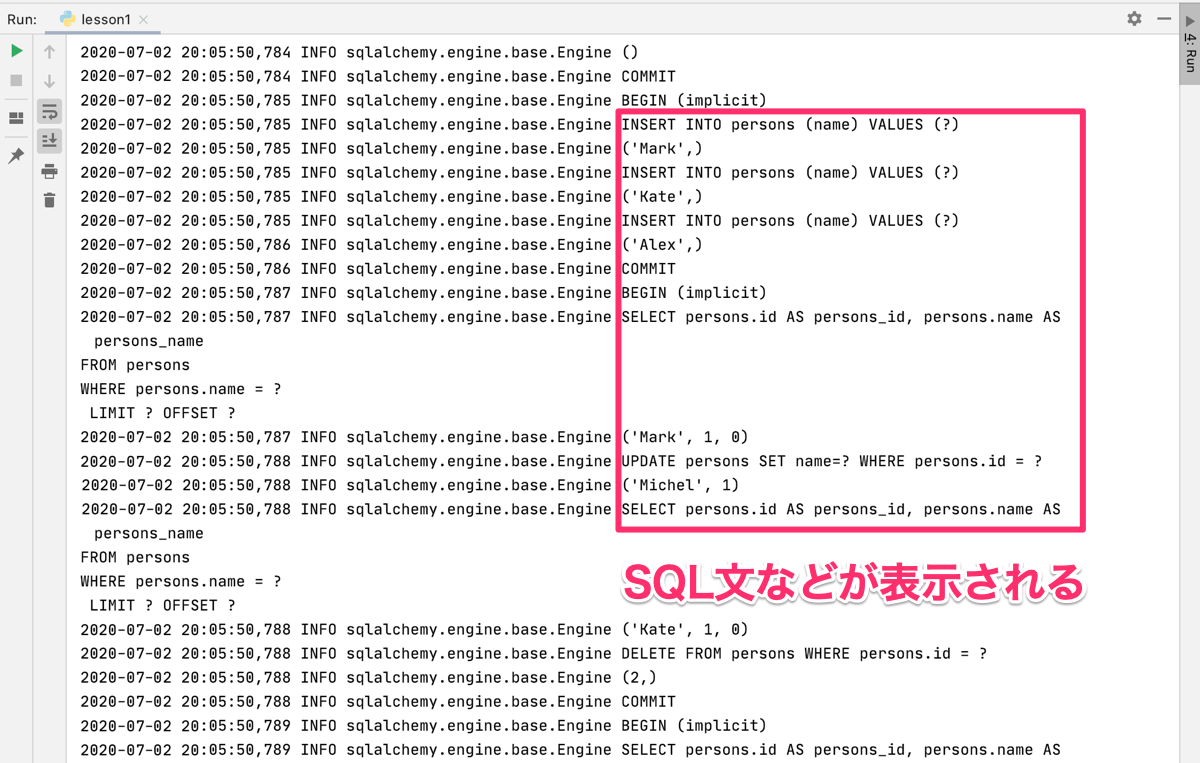
実際には、裏でこのようなコマンドが実行されていたということです。
同様に、実行コード5行目のengineオブジェクトの接続URLを変更すれば、SQL文を気にすることなくいろいろなデータベースを扱うことができるので、明日はメモリーにではなく、実際にデータベースファイルを作って操作していこうと思います。
それでは明日も、Good Python!