Python学習【365日チャレンジ!】72日目のマスターU(@Udemy11)です。
Pythonistaを毎日使っているのですが、Webでの日本語情報がかなり少ないように感じています。
この間のsetup.pyでのパッケージ化にしても、誰もやっていないのか、それとも他のやり方があるのか、ネットを探してもほとんど情報がないんですよね。
なので、Pythonをマスターできたら、Pythonistaに特化したサイトを作ろうかなと思っています。
いつのことになるのかは、まったくもってわかりませんが。。。。
それでは、今日もPython学習をすすめていきましょう。
昨日の復習
昨日は、組み込み関数について学習しました。
組み込み関数は、Pythonに最初から組み込まれている関数で、importで読み込まなくても使うことのできる関数です。
これまで最も出現頻度の高いprint関数も組み込み関数です。
その中で、昨日は、sorted関数を学習しました。
test = {
'田中': 77,
'鈴木': 65,
'吉田': 91,
'大田': 55
}
r = sorted(test, key=test.get, reverse=True)
print(r)出力結果
['吉田', '田中', '鈴木', '大田']イテラブル変数である辞書型変数testのvalueを参照して、降順に並べ替えたkeyを出力しています。
すでに組み込み関数はたくさん学習していますが、Pythonの公式ドキュメントを見れば、他の組み込み関数を参照することが可能です。
それでは、本日学習する標準ライブラリに移りたいと思います。
標準ライブラリ
こちらの公式ドキュメントに、標準ライブラリの解説がありますが、たくさんありすぎて何がなんやらわかりません。
このすべてのライブラリを覚える必要はなく、これからも全く使わないライブラリがあることは間違いありません。
Pythonの開発者ですら、すべての標準ライブラリが頭に入っているわけではないと思います。
この中から、自分が開発したいアプリやサービスに必要なライブラリを使えばいいので、この段階で、
こんなに憶えられないよ〜!
と嘆く必要はありません。
辞書をすべておぼえる人はいないように、Pythonの標準ライブラリをすべて憶えている人もいません。
要は、使う必要が出てきたときに、公式ドキュメントを参考にして使い方がわかればいいわけです。
標準ライブラリの使い方
組み込み関数は、importする必要なく利用することができました。
標準ライブラリは組み込み関数と違い、自作パッケージ同様に、importで読み込む必要があります。
ちなみに、組み込み関数も標準ライブラリなのですが、Pythonでコードを書くにあたって必要不可欠なものを集めているため、importでいちいち読み込むことなく、使えるようになっています。
使い方としては、これまでも学習してきたように
import ライブラリ名もしくは
from ライブラリ名 import オブジェクト名もしくは
from ライブラリ名.オブジェクト名 import メソッド名で読み込めば、ライブラリのオブジェクトを使うことができます。
collectionsライブラリ
酒井さんの講座の中では、標準ライブラリの中でも、使用頻度の高いcollectionsライブラリが紹介されていました。
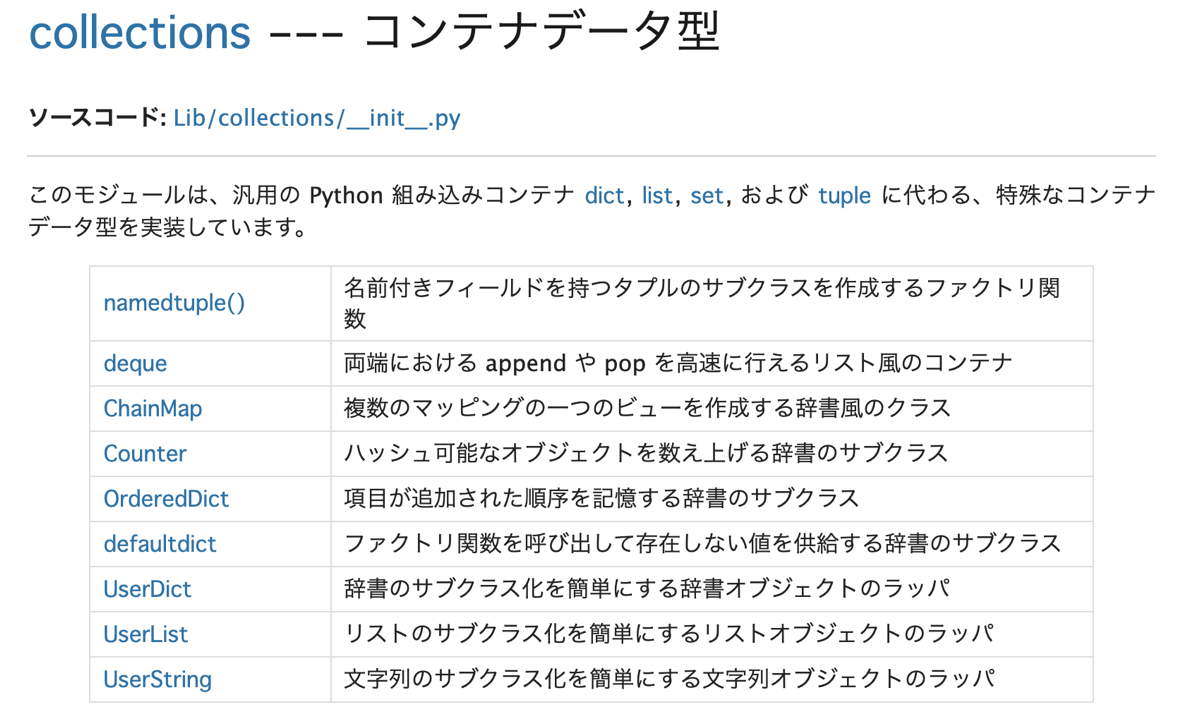
これらのcollectionsオブジェクトの中から、defaultdictについて学習しました。
collections.defaultdict()
アルファベットの文字列の中からそれぞれのアルファベットの数を数えて辞書型データにまとめる方法を考えてみます。
a = 'kjoviajdoiajdljkfalemkakjdoifa'
d = {}
for i in a:
if i not in d:
d[i] = 0
d[i] += 1
print(d)出力結果
{'k': 4, 'j': 5, 'o': 3, 'v': 1, 'i': 3, 'a': 5, 'd': 3, 'l': 2, 'f': 2, 'e': 1, 'm': 1}まずは、これまで学習してきた知識を使った方法です。
文字列変数aをループで回して、リスト型変数dの中にアルファベットが存在しない場合、そのアルファベットをkeyにして、valueに0を代入します。
その後、そのアルファベットのvalueに1をプラスしています。
文字列のforループは、一つ一つの文字で区切られるため、同じアルファベットが出てきたときに数字がプラスされるので、文字列の中のアルファベットをカウントできるということですね。
また、辞書型のメソッドsetdefaultを使っても同じ出力が可能です。
a = 'kjoviajdoiajdljkfalemkakjdoifa'
d = {}
for i in a:
d.setdefault(i, 0)
d[i] += 1
print(d)setdefaultは、辞書型のデータに、対象のkeyが存在しない場合は、指定したvalueを追加して、対象のkeyが存在する場合は何もしないメソッドです。
出力結果は最初と同じになります。
では、最後にcollectionsライブラリのdefaultdictオブジェクトを使ったコードを書いてみます。
from collections import defaultdict
a = 'kjoviajdoiajdljkfalemkakjdoifa'
d = defaultdict(int)
for i in a:
d[i] += 1
print(d)出力結果
defaultdict(, {'k': 4, 'j': 5, 'o': 3, 'v': 1, 'i': 3, 'a': 5, 'd': 3, 'l': 2, 'f': 2, 'e': 1, 'm': 1}) 標準ライブラリのcollectionsライブラリのdefaultdictオブジェクトを読み込んで、整数をvalueにする空の辞書型変数dを定義します。
そのあと、forループで文字列aを代入しながら、同じアルファベットに1をプラスすることで、アルファベットをカウントしています。
sortedと組み合わせる
昨日学習した組み込み関数sortedと組み合わせて使えば、出力結果をアルファベット順に並べることが可能です。
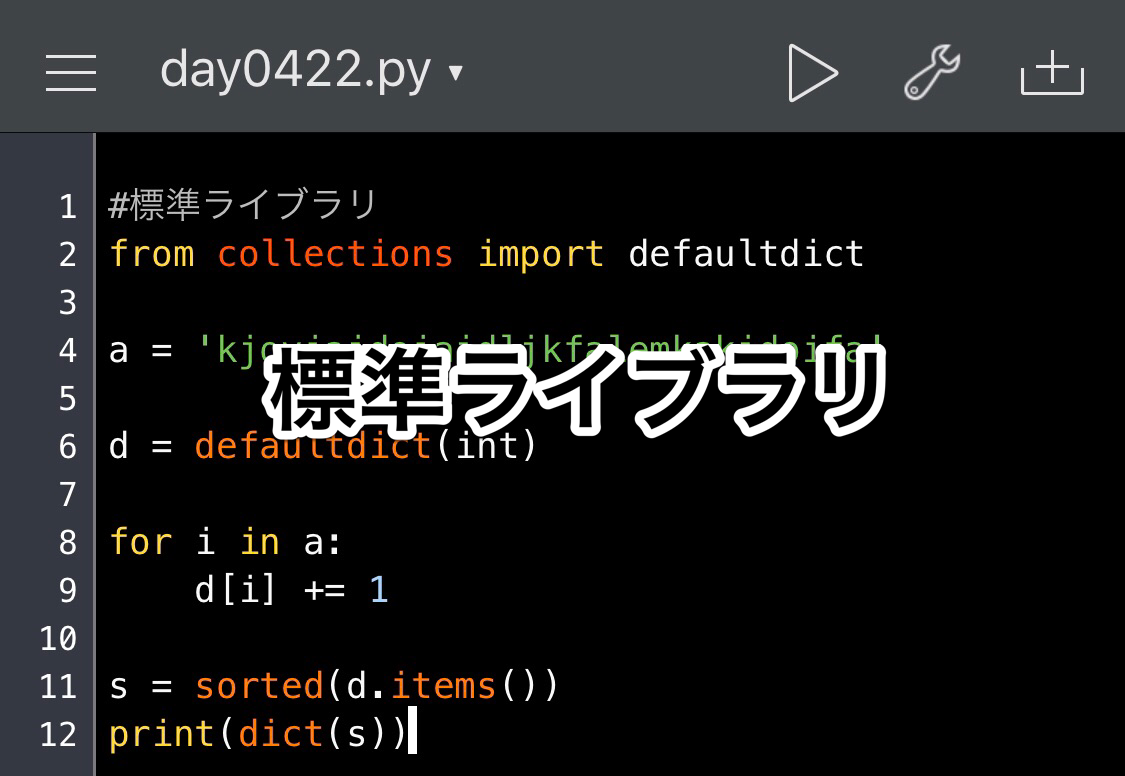
from collections import defaultdict
a = 'kjoviajdoiajdljkfalemkakjdoifa'
d = defaultdict(int)
for i in a:
d[i] += 1
s = sorted(d.items())
print(dict(s))出力結果
{'a': 5, 'd': 3, 'e': 1, 'f': 2, 'i': 3, 'j': 5, 'k': 4, 'l': 2, 'm': 1, 'o': 3, 'v': 1}itemsは以前学習しましたが、sorted(d.items())で、タプル化されたデータ('key', value)をkeyで昇順にソートしたリストになります。
それをさらに辞書型に戻した変数sを出力しています。
必要なものを必要なときに
標準ライブラリについては、便利な使い方ができるものがたくさん用意されているのですが、実際にどのように使うのか、公式ドキュメントを読むだけでは分かりづらいと思います。
今回学習したcollectionsにしても、こんな使い方があるってのはわかりましたが、実際にどのようなプログラムで使うのかをイメージするのは難しいですよね。
なので、これから具体的なプログラムを書いていく上で、必要になったときに学習すればいいわけで、いま使い方を憶えたとしても、記憶はどんどん忘れ去られていきます。
なので、
こんな使い方できるライブラリないかな?
と思ったときに、公式ドキュメントから使えそうなライブラリを探せばいいと思います。
どんなものでもそうですが、必要なものを必要なときに用意すればいいわけです。
Python学習も70日を超えて、どんどん内容が難しくなってくるので、思わず毎日更新を挫折しそうになりますが、次の目標である90日もそろそろ見えてきたので、しっかりモチベーションを保って頑張りたいと思います。
それでは明日も、Good Python!