Python学習【365日チャレンジ!】340日目のマスターU(@Udemy11)です。
それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、Google検索の1ページ目にヒットしたページのURLとそのURLにアクセスして完全なタイトルを取得しました。
lxmlを使って取得したデータをパースしていましたが、BeautifulSoupを使えばスムーズにURLを取得することができました。
urllib.parse.unquoteを使ってURLエンコードをデコードする必要があり、この部分には結構ハマってしまいました。
あとは、リストに入れたURLにアクセスしてタイトルを取得しましたが、try-except文を使ってエラーが起こったときに【取得できませんでした。】と出力するようにしました。
詳細については、昨日の記事をごらんください。

今日は、昨日のコードで取得できたURLとタイトルをCSVファイルに保存してみたいと思います。
昨日のコードのおさらい
昨日のコードでは、リストに入れたURLとタイトルを出力していましたが、不要なコードを削除したコードにします。
import re
import urllib.parse
from bs4 import BeautifulSoup
import requests
search_query = '東京 餃子のおいしい店'
r = requests.get('https://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=' + search_query)
html_soup = BeautifulSoup(r.text, 'html.parser')
url_results = []
for t in html_soup.select('.kCrYT > a'):
u_result = re.sub(r'/url\?q=|&sa.*', '', t.get('href'))
url_results.append(urllib.parse.unquote(u_result))
title_results = []
for i in url_results:
try:
search = requests.get(i)
search_soup = BeautifulSoup(search.text, 'html.parser')
titles = search_soup.find('title')
title_results.append(titles.text)
except:
print('取得できませんでした。')ここまでのコードで、リストのurl_resultsとtitle_resultsにデータが入っているので、そのデータをCSVファイルに書き込んでいきます。
CSVファイルに書き出し
CSVファイルへの書き出しについては、こちらの記事で学習しました。

今回は、2つのリストをまとめて書き込むので、zipを使ってリストを書き出していきます。
import csv
with open('url_title.csv', 'w') as csv_file:
fieldnames = ['TITLE', 'URL']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for t, u in zip(title_results, url_results):
writer.writerow({'TITLE': t, 'URL': u})csvライブラリをインポートしていなかったので、便宜上、ここでインポートしています。
30行目からのwithステートメントで、CSVファイルを書き込みモードで書き込んでいきます。
31行目でフィールドの名前をTITLEとURLに指定して、32行目でDictWriterオブジェクトを生成します。
33行目でフィールド名をヘッダに書き込んで、34行目のforループで2つのリストを回してTITLEとURLに書き込みます。
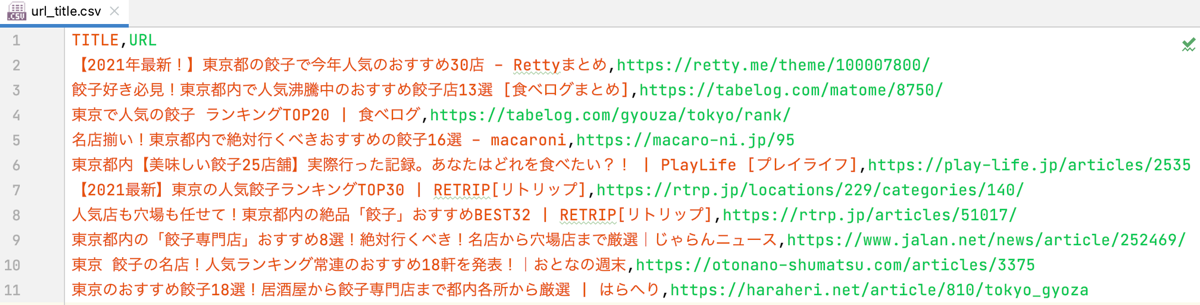
CSVファイル
問題なく処理が完了すると、Pythonファイルと同じ階層にurl_title.csvが作成されます。
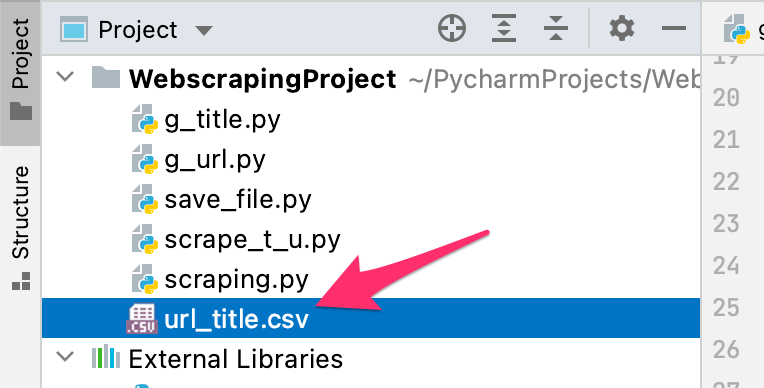
このファイルをダブルクリックで開いてみると、きちんとデータが保存されているのがわかります。
CSVの読み込み
最後に、書き出したCSVファイルを読み込んで出力するコードを追加してみます。
with open('url_title.csv', 'r') as csv_file:
reader = csv.DictReader(csv_file)
for r in reader:
print(r['TITLE'], r['URL'])withステートメントでurl_title.csvを読み込んで、DictReaderオブジェクトを生成して、1行ずつ出力しています。
出力結果
【2021年最新!】東京都の餃子で今年人気のおすすめ30店 - Rettyまとめ https://retty.me/theme/100007800/
餃子好き必見!東京都内で人気沸騰中のおすすめ餃子店13選 [食べログまとめ] https://tabelog.com/matome/8750/
東京で人気の餃子 ランキングTOP20 | 食べログ https://tabelog.com/gyouza/tokyo/rank/
名店揃い!東京都内で絶対行くべきおすすめの餃子16選 - macaroni https://macaro-ni.jp/95
東京都内【美味しい餃子25店舗】実際行った記録。あなたはどれを食べたい?! | PlayLife [プレイライフ] https://play-life.jp/articles/2535
【2021最新】東京の人気餃子ランキングTOP30 | RETRIP[リトリップ] https://rtrp.jp/locations/229/categories/140/
人気店も穴場も任せて!東京都内の絶品「餃子」おすすめBEST32 | RETRIP[リトリップ] https://rtrp.jp/articles/51017/
東京都内の「餃子専門店」おすすめ8選!絶対行くべき!名店から穴場店まで厳選|じゃらんニュース https://www.jalan.net/news/article/252469/
東京 餃子の名店!人気ランキング常連のおすすめ18軒を発表!|おとなの週末 https://otonano-shumatsu.com/articles/3375
東京のおすすめ餃子18選!居酒屋から餃子専門店まで都内各所から厳選 | はらへり https://haraheri.net/article/810/tokyo_gyoza保存されているCSVファイルの中身がきちんと表示されています。
まとめ
CSVファイルへの書き出しは、以前学習していたので、スムーズにコードを書くことができました。
悩んだのは、2つのリストの値をどのようにしてCSVファイルに書き込むかというところで、最初は順番に一つずつリストの値を書き込もうとしたのですが、どうもうまく行かなかったので、2つのリストをリスト内包括とzipを使って一つのリストにまとめてから書き込むようにしました。
これでうまく書き込むことができたのですが、普通に2つのリストをforループで回せることに気づいて、今回のコードが完成しました。
検索結果のページによって、文字化けが起こることは解決していませんが、できることをどんどん試していきたいと思います。
それでは、明日もGood Python!