Python学習【365日チャレンジ!】336日目のマスターU(@Udemy11)です。
朝晩の冷え込みだけでなく、昼間も寒い日がつづくので、なかなか動き出せずに体がカチンコチンになってしまっています。
寝ている間に寝違えてしまったようで、左を向くと首が痛くてたまりません。
寝違えたこの傷みはどのくらいで無くなるんでしょうか?
とりあえず、普段は首を温めて、お風呂に入ったときは、首までつかってゆっくり養生しようと思います。
それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、Webスクレイピングによく使われるPythonのライブラリについて紹介しました。
代表的なライブラリはBeautifulSoupですが、単体ではなく、requestsなどのHTTP通信を扱えるライブラリと一緒に使う必要がありました。
その他、SeleniumやScrapyなどを使ってWebスクレイピングをすることができます。

アフィリエイトなどに必要なWebサイト分析には、Webスクレイピングが欠かせません。
そんなWebスクレイピングについて、今日から実際にコードを書きながら少しずつ実践していきたいと思います。
BeautifulSoupとrequests
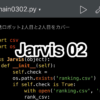
まずはBeautifulSoupとrequestsを活用して、Google検索からヒットしたページのタイトルを抽出してみます。
from bs4 import BeautifulSoup
import requests
search_query = 'Udemy'
html = requests.get('https://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=' + search_query)
soup = BeautifulSoup(html.text, 'lxml')
h3_text = soup.find_all('h3')
titles = []
for i in h3_text:
title = i.get_text()
titles.append(title)
for _ in titles:
print(_)BeautifulSoupとrequestsをインポートしたあと、検索するキーワードをsearch_queryに代入します。
requests.getを使って、search_queryで検索したGoogle検索の結果をhtmlに代入します。
htmlのテキストをHTMLパーサーのlxmlでパース(解析)した値をsoupに代入し、その中から、h3タグを抜き出してh3_textとします。
10行目でtitlesという空のリストを作り、h3_textに入っているh3タグからテキストを抜き出してtitlesリストに代入していきます。
15行目のforループでtitlesのリストを一つずつprint出力しています。
出力結果
Udemy
【受講生1万人越え!】Udemy「神」講師の最新講座5選+α - Qiita ...
Udemyとは?特徴・評判・おすすめ講座を紹介します | テック ...
Udemy - オンラインコース - Google Play のアプリ
Udemy メディア
Udemy for Business | 最先端のITスキルは実務を通じて学ぶ時代へ ...
「Udemy:ビデオで授業が受けられる学習アプリ」をApp Storeで
ユーデミー実際の検索結果と比べてみるとトップに表示される広告やヒットしたサイト内の他の記事やカテゴリは含まれていないのがわかります。
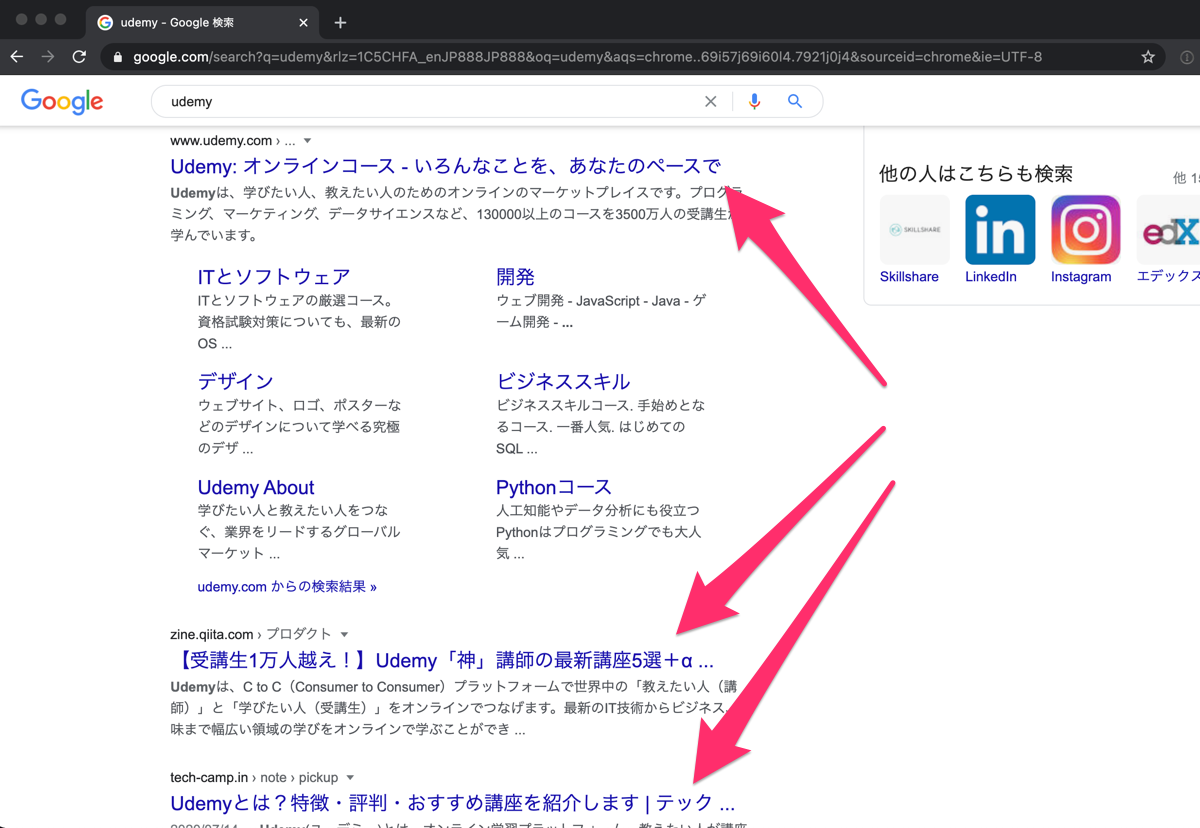
Google検索結果のHTMLを見ながら、ヒットするページのタイトルがh3タグでくくられていたので、これでタイトルを抽出することができましたが、34文字以上あるタイトルの場合、…で省略されてしまいます。
省略せずにタイトルを取得するには、このあと、URLを取得して、リンク先のHTMLからtitleタグを抽出する必要が出てきますので、今日はひとまずここまでで終了します。
まとめ
Google検索の1ページ目から情報を抜き出すコードは、Python学習365日チャレンジを開始する前にサンプルコードを元に作ったことがあったのですが、そのときのコードをそのまま実行しても何も抽出されませんでした。。
Google検索の結果をHTMLで見ると、以前抽出できていたコードで指定するタグの属性やクラスが変更されていて、ヒットする結果がないようで、Googleの仕様が変更されたのかと思いつつ、いろいろと試して、この結果にたどり着きました。
とりあえず目的の値は抽出できましたが、ちょっと時間がかかりすぎたので、一緒に抜き出したかったURLの抽出は明日に持ち越すことにしました。
実際にコードを書きながら、実行して、ああでもないこうでもないとやっているときが、わからないなりにも楽しいので、ついつい記事にまとめる時間がなくなってしまいますが、なんとかあと1ヶ月、記事は書き続けたいと思います。
それでは、明日もGood Python!