Python学習【365日チャレンジ!】339日目のマスターU(@Udemy11)です。
押入れの中から、オムロンの小型マッサージピローを見つけました。
これまでは活躍場面がなかったのですが、あまりにも腰が痛かったり、肩こりがひどいので、この機会に活用してみることにしました。
これが意外と気持ちよくて、ソファーに寝転んで、背中の肩甲骨のあたりにおいてマッサージをしていると、痛気持ちよくて知らない間に寝てしまいました。
せっかくなので、壊れるまでしっかりと活用したいと思います。

| 評価 | 4.5 |
|---|
それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、Google検索の1ページめにヒットしたページのURLにアクセスして完全タイトルを取得しました。
URLを抜き出してそのURLにアクセスしてタイトルを抽出したわけですが、URLがおかしかったり、アクセスしたページが存在しなかったりすることがあるので、エラーが起こることを想定して最後までプログラムを処理できるコードにカスタマイズする必要がありました。
不完全なコードでしたが、昨日検索したキーワード鬼滅の刃 映画感想など、検索結果によってはきちんとデータを取得することができました。

今日は、エラー対応のためtry-exceptを使って、処理を完了できるコードに挑戦してみます。
最終的なコード
最終的に今日の時点で完成したコードがこちらです。
import re
import time
import urllib.parse
from bs4 import BeautifulSoup
import requests
search_query = '東京 餃子のおいしい店'
r = requests.get('https://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=' + search_query)
html_soup = BeautifulSoup(r.text, 'html.parser')
url_results = []
for t in html_soup.select('.kCrYT > a'):
u_result = re.sub(r'/url\?q=|&sa.*', '', t.get('href'))
url_results.append(urllib.parse.unquote(u_result))
for i in url_results:
print(i)
title_results = []
for i in url_results:
try:
search = requests.get(i)
search_soup = BeautifulSoup(search.text, 'html.parser')
titles = search_soup.find('title')
title_results.append(titles.text)
except:
print('取得できませんでした。')
time.sleep(2)
for t in title_results:
print(t)出力結果

実際の検索結果ページはこんな感じです。
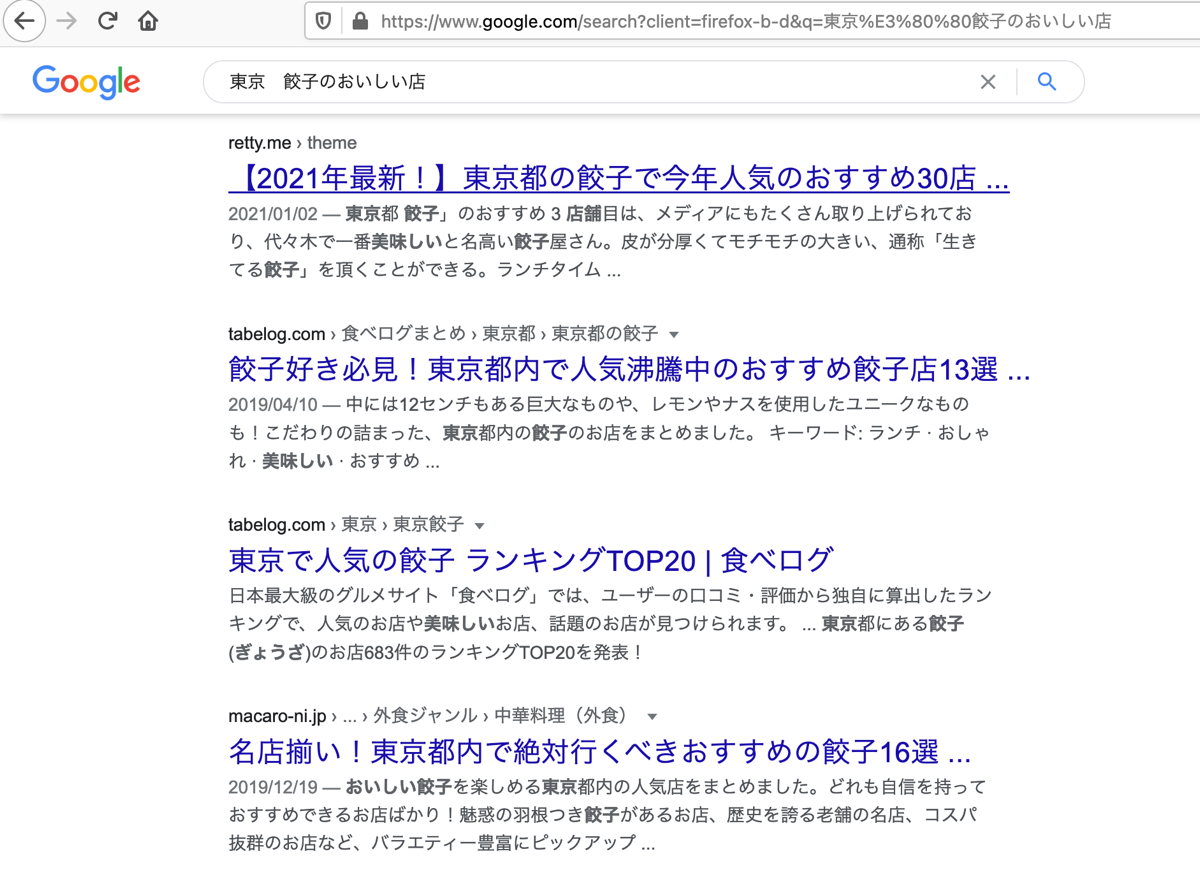
省略されているタイトルもきちんと取得できているのがわかります。
それではパーツごとに確認してみましょう。
インポートするライブラリ
import re
import time
import urllib.parse
from bs4 import BeautifulSoup
import requests昨日までは、lxmlを使っていましたが、どうにもうまくいかなかったので、BeautifulSoupを使ってみました。
他には、正規表現のre、検索にインターバルを入れるためのtime、URLのエンコード・デコードができるurllib、HTTPでデータを取得するためのrequestsをインポートしています。
検索ワードから結果をパースする
search_query = '東京 餃子のおいしい店'
r = requests.get('https://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=' + search_query)
html_soup = BeautifulSoup(r.text, 'html.parser')8行目で検索するキーワードを指定して、10行目で検索結果のページをrequests.getで取得し、11行目でBeautifulSoupを使って取得したテキストをhtml.parserで解析します。
URLをリストに保存
url_results = []
for t in html_soup.select('.kCrYT > a'):
u_result = re.sub(r'/url\?q=|&sa.*', '', t.get('href'))
url_results.append(urllib.parse.unquote(u_result))
for i in url_results:
print(i)13行目で抽出したURLを入れるリストurl_resultsを作ります。
14行目からのforループで、BeautifulSoupとre、urllibを使ってクラス名がkCrYTの中のaタグの中からURLを抽出して、リストurl_resultsに追加していきます。
urllib.parser.unquoteを使って結果をデコードしているのですが、これは取得したURLに?や=が入っているときは、%3Fや%3Dに変換されているため、そのままリストに入れると、あとからそのURLにアクセスするときにページが存在しないエラーになってしまうからです。
18行目、19行目でリストを一つずつ出力します。
タイトルの抽出
title_results = []
for i in url_results:
try:
search = requests.get(i)
search_soup = BeautifulSoup(search.text, 'html.parser')
titles = search_soup.find('title')
title_results.append(titles.text)
except:
print('取得できませんでした。')
time.sleep(2)
for t in title_results:
print(t)21行目で抽出したタイトルを入れるリストtitle_resultsを作成します。
22行目から32行目でforループを使って、リストurl_resultsを回して一つずつタイトルを抽出します。
タイトルを取得できない場合があるので、try-exceptを使ってエラーの際は【取得できませんでした。】と出力するようにしています。
tryの部分は、24行目でリストurl_resultsに格納されているURLからrequests.getで値を取得して、25行目のBeautifulSoupでパースし、26行目でパースしたsearch_soupから1つ目のtitleを抽出し、27行目でリストtitle_resultsに抽出したテキスト部分を追加しています。
try-exceptが1まわりするたびに、time.sleepで2秒待つようにしています。
これは、Google検索に短時間でアクセスが集中した場合、不正なアクセスと判断されないようにするためですが、短時間に何度も抽出しなければこのコードは必要ないかと思います。
34行目と35行目でタイトルを入れたリストtitle_resultsを一つずつ表示しています。
まとめ
Google検索の結果からURLを抽出する際に、過去にやったことがある方法だと抽出できなかったものの、lxmlを使った同じやり方で抽出していましたが、どうにもURLの抽出コードがきれいに書けなかったので、BeautifulSoupを使ってみると、すんなり求める値を抽出することができました。
過去のやり方にこだわらず、いろいろと試してみることが大切ですね。
今回のコードで、最もハマったのは、URLエンコードで?が%3Fに変換されて保存されるところです。
リストに保存されたURLにアクセスするので、ページが見つからずに値を取得できておらず、一番最初のコードはexceptでpassにしていたので、何が問題なのかわかりませんでした。
そこで、exceptでErrorを出力するようにしたところ、エラーが起こっているのがわかったので、原因を探ってみるとURLエンコードにたどり着きました。
さらに、どうすればもとの?として保存できるのかを調べてurllib.parse.unquoteにたどりつくまでにもかなり時間を要してしまいました。
結果、なんとかURLとタイトルを抽出できるコードになりましたが、検索キーワードによっては、アクセス先のタイトルが文字化けを起こすものがあるので、そこの原因はわかっていません。
とりあえず、今日はここまでで満足して、明日につなげたいと思います。
それでは、明日もGood Python!