Python学習【365日チャレンジ!】156日目のマスターU(@Udemy11)です。
WebでPythonの組み合わせを考えるとWebから必要な情報を集めるスクレイピングをイメージしてしまいますが、この使い方はWebでPythonを活用するほんの一部の使い方です。
今日から、WebやネットワークにおけるPythonの活用方法について学習していきましょう!
昨日の復習
昨日は、これまでに学習したデータベースの総復習をしました。
手軽に使用できるリレーショナルデータベースのSQLiteやWordPressでも使われているMySQL、メモリでデータベースを扱えるmemcached、RDBに取って代わる勢いのあるNoSQLのMongoDBやグラフ型データベースのNeo4jなど、いろいろな形のデータベースがありました。
詳しくは、昨日のデータベース総復習から各データベースの記事を参考にしてみてください。

今日から新しいセクションであるWebとネットワークの領域にすすみます。
Webで使われるデータフォーマット
Webで使われるデータフォーマットと聞いて思いつくのは、画像のデータフォーマットである【JPEG】や【PNG】、【GIF】ではないでしょうか?
少し前までは、GIFアニメなどもありましたが、最近ではJPEGとPNGがほとんどで、使われ方としては、写真で使うならJPEG、画像キャプチャなどはPNGという使われ方がされています。
一方でテキストに関するデータでいうと、HTMLやCSSがWebサイトを表示するための基本的な情報が入っています。
同じテキストファイルでも、CSVやXML、JSONはデータベースとしての役割を持っていて、それぞれのフォーマットに同じ情報を入れても記述の仕方が大きく変わってきます。
CSVについては、すでにJarvisを作成する際に、学習しました。

今回は、XMLをPythonで扱う方法について学習します。
XMLとは
XMLは、Extensible Markup Language(エクステンシブル マークアップ ラングエッジ)の略で、記述方法は、HTMLと同じように、<>で囲んだタグを使ってデータを保存していきます。
データを受け取るクライアント側の処理が容易にできるので、インターネット創世記の終わりにHTMLをさらに拡張できる言語として期待されていました。
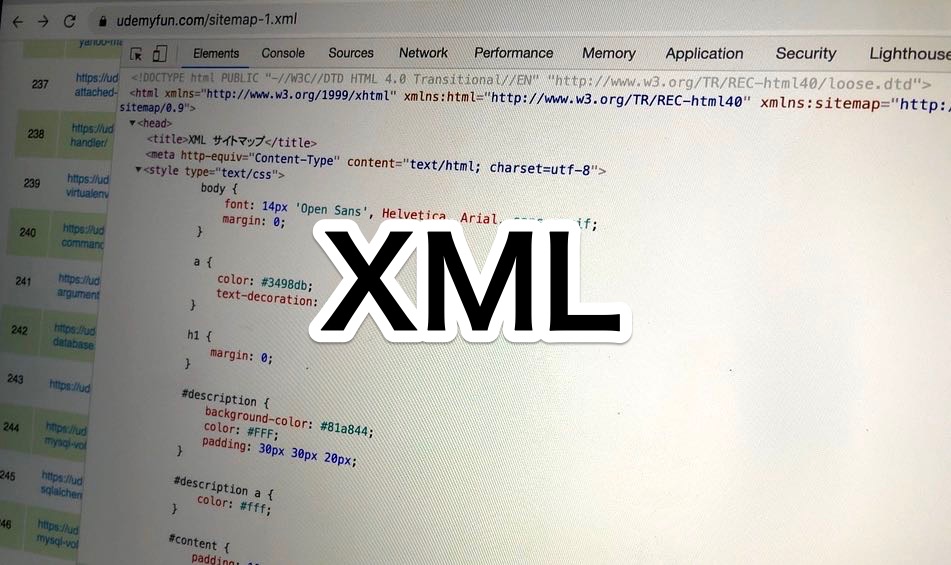
XMLは、わかりやすいところで、サイト構造をコンピューターにわかりやすく伝えるサイトマップとして使われていますし、企業間の電子商取引分野や企業内システムでも活用されている汎用性の高いフォーマットです。
ただ、最近ではJSONのほうが記述が簡単でサイズも小さく収まるので、JSONが使われるケースが増えていますが、システムを変えるにはそれなりにコストがかかるため、XMLがメインで使われているシステムも多く存在します。
XMLの記述方法
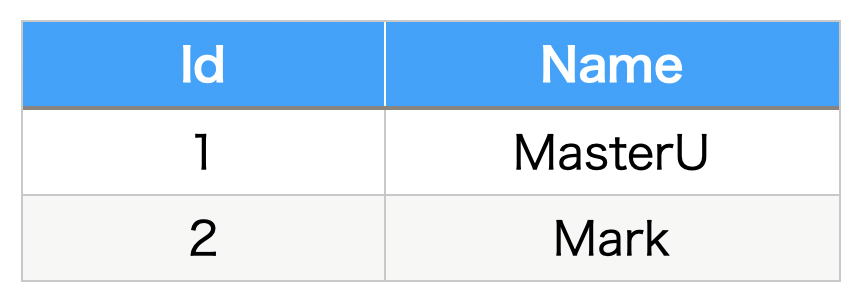
XMLの記述は、HTMLと同じように記述しますが、例えば、上記の表をXMLで記述すると次のようになります。
<?xml verssion='1.0' encoding='utf-8'?>
<root>
<employee>
<employ>
<Id>1</Id>
<Name>MasterU</Name>
</employ>
<employ>
<Id>2</Id>
<Id>Mark</Name>
</employ>
</employee>
</root>ちなみにCSVだとこんな感じ
Id, Name
1, MasterU
2, MarkJSONの場合は次のとおり。
[
{'Id': '1', 'Name': 'MasterU'},
{'Id': '2', 'Name': 'Mark'}
]随分と記述方法が違いますね。
XMLを作成
PythonでXMLを扱うにはxml.etree.EleentTreeをインポートして使います。
import xml.etree.ElementTree as ET
root = ET.Element('root')
tree =ET.ElementTree(element=root)
employee = ET.SubElement(root, 'employee')
employ = ET.SubElement(employee, 'employ')
employ_id = ET.SubElement(employ, 'Id')
employ_id.text = '1'
employ_id = ET.SubElement(employ, 'Name')
employ_id.text = 'MasterU'
employ = ET.SubElement(employee, 'employ')
employ_id = ET.SubElement(employ, 'Id')
employ_id.text = '2'
employ_id = ET.SubElement(employ, 'Name')
employ_id.text = 'Mark'
tree.write('test.xml', encoding='utf-8', xml_declaration=True)最初のインポートの記述ではasを使うのはコードスタイル状は推奨されていませんが、as ETと記述することが多いようです。
XMLにかかれているインデントのくくりと同じようにemployee→employ→Id, Nameのくくりで考えるとわかりやすいかと思います。
最後にtree.writeを使ってtext.xmlに書き込んでいます。
このコードを実行すれば、先程紹介した記述例と同じXMLファイルが作成されます。
XMLファイルの最初の1行<?xml verssion='1.0' encoding='utf-8'?>は、Pythonのコードの最終行にあるxml_declaration=Trueで挿入されて改行されますが、書き込んだコードは改行なしで1行にすべて収められています。
作成されるXMLファイルの中身はこんな感じの2行のファイルになります。
<?xml verssion='1.0' encoding='utf-8'?>
<root><employee><employ><Id>1</Id><Name>MasterU</Name></employ><employ><Id>2</Id><Id>Mark</Name></employ></employee></root>XMLの読み込み
続いて作成したXMLの中のデータを取り出してみます。
import xml.etree.ElementTree as ET
tree = ET.ElementTree(file='test.xml')
root = tree.getroot()
for employee in root:
for employ in employee:
for person in employ:
print(person.tag, person.text)出力結果
Id 1
Name MasterU
Id 2
Name Markインポートは同じです。
先にtest.xmlファイルを読み込んだtreeオブジェクトを作りgetroot()を使って、イテラブルオブジェクトrootを生成したあと、forループを使って中身を読み込んでいきます。
これも、XMLのインデント構造をイメージするとわかりやすいかと思います。
HTMLみたい
XMLは、HTMLと同じような対のタグを使って記述するので、ホームページを作成する人にとっては理解が速いフォーマットです。
特に、Search Consoleなどに利用するサイトマップはXMLで作られているので、知っている人も多いと思います。
ただ、最近ではXMLよりもシンプルな記述が可能なJSONに変換して情報を取得するなど、JSONのほうが利便性が高くなってきているようですが、XMLは古いシステムなどでは生き残っていくと思います。
新しいフォーマットや言語、システムはどんどんと生み出されて、より利便性の高いものにアップデートされていきます。
とはいえ、新しいものばかりを追い求めていては、これまでの資産を活用できなくなるので、ひととおり、ざっと理解しておくことも重要です。
ということで、今日はPythonでXMLを扱う方法を手短に紹介しました。
HTMLを理解していれば、ある程度理解はできていると思うので、サラッと流して次のレクチャーにすすみましょう!
それでは明日もGood Python!