Python学習【365日チャレンジ!】149日目のマスターU(@Udemy11)です。
とりあえず、ほしかったものを購入して物欲のピークを乗り越えました。

色々悩んだ結果、フィッシングメーカー大手のDAIWAブランドを買っちゃうんですよね。
これで一旦は物欲も収まってPython学習に集中できるかと思いきや、今度は釣りに行きたい欲求が襲ってきそうです。
そんな欲求を抑えながら、今日もPython学習を始めましょう。
昨日の復習
昨日、一昨日と2日間で、MongoDBを学習しました。
MongoDBは、NoSQLの中でも人気のあるデータベースで、JSON形式でデータを保存したり、取り出したりして使いました。
データベースにデータを挿入すると、自動的に_idというカラムが生成され、ObjectIDというオブジェクトで扱えるようになりました。
MongoDBをPythonで使う方法は、こちらの記事をごらんください。

MongoDBの使う準備(インストールなど)については、こちらの記事を参考にしてください。
今日は、Hbaseについて学習しましょう!
Hbaseとは
Hbaseは、UNIXベースのデータベースなので、Macへのインストールは簡単ですが、Windowsにインストールするにはたくさんの手順が必要になります。
Hbaseは、大量のカラム(フィールド)を扱うことができるNoSQLのデータベースで、より詳しく知ろうと思って、下記の記事を読んでみましたが、全くもってちんぷんかんぷん。

とりあえず、RDBの欠点を解消して、データ整合性よりも処理速度を重視したNoSQLの1つという理解で、実際にHbaseをさわっていきたいとおもいます。
Hbaseのインストール
私は基本的にMacを使っているのでbrew install hbaseで簡単にインストールできますが、Windowsを使っている場合は、下記のページを参考にチャレンジしてみてください。

私のような初心者にはかなり難しいないようなので、間違いなく挫折してしまいそうです。
ほんとMacで良かったって感じです。
ということで、早速Hbaseをインストールしますが、相変わらずhomebrewのアップデートが結構あって、時間がかかりました。
インストールが完了すれば、Hbaseを起動しますが、バックグラウンドで稼働させる必要がないので、今回はstart-hbase.shを実行します。
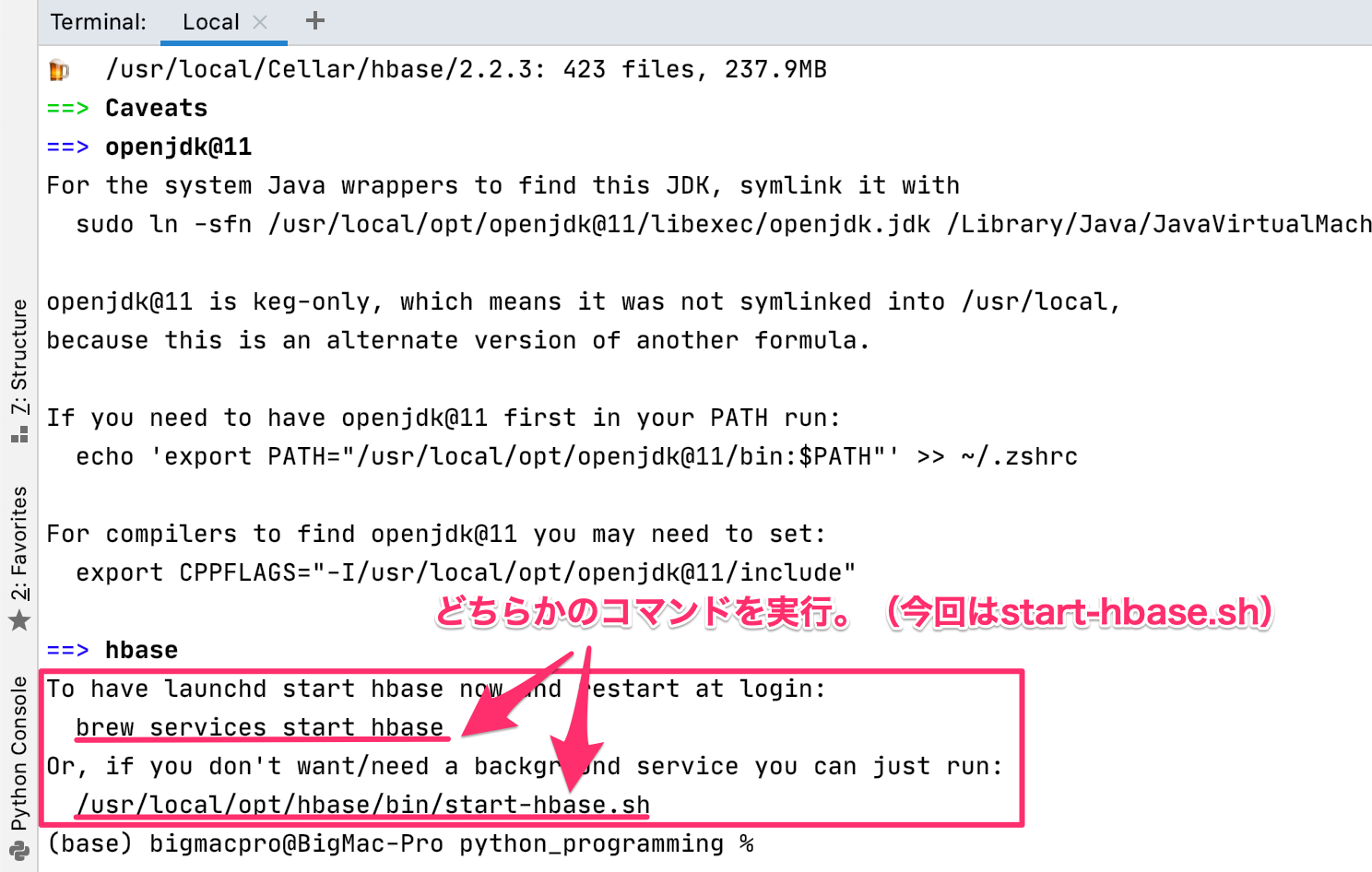
Hbaseをターミナルから操作
続いて、Hbaseを操作していきますが、ターミナルでstart-hbase.shを実行すると、いろいろな警告(warnning)が出ますが、オプションが将来のバージョンでサポートされなくなるなどのもので、とりあえずHbaseを使うことができます。
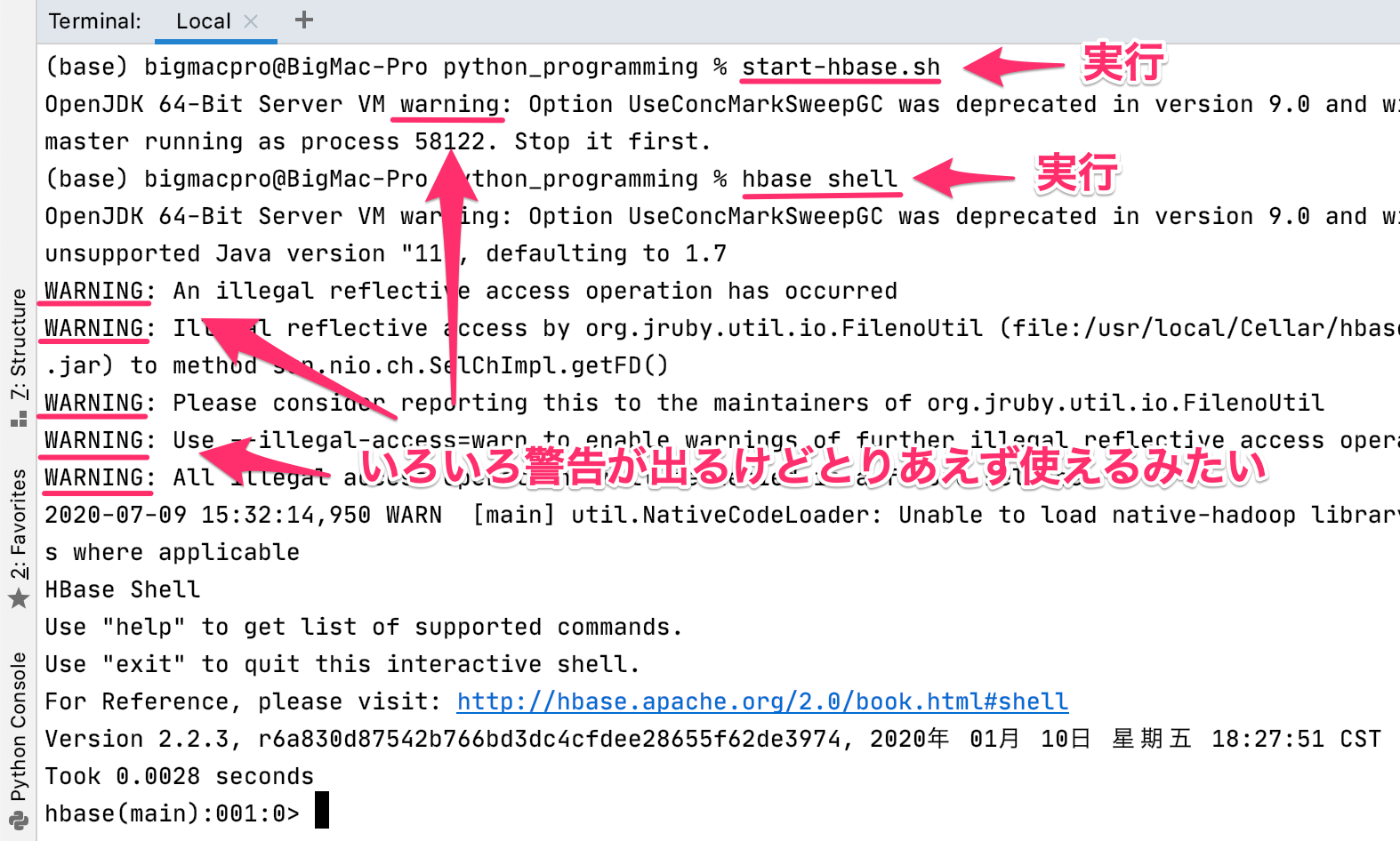
ここから次のようなワイドカラム型のデータを作ってみましょう。
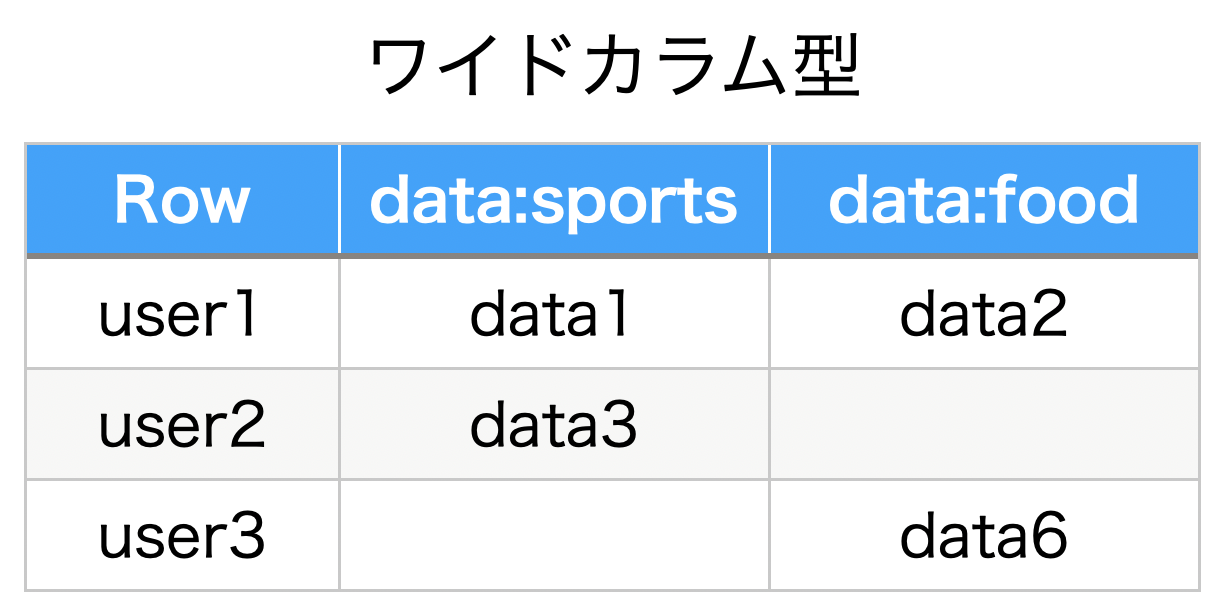
まずはテーブルを作成して1行1列のデータを挿入します。
次のコマンドを順番に実行していきます。
create 'test', 'data'put 'test', 'user1', 'data:sports', 'data1'scan 'test'

1つ目は、テーブルを作るコマンドで、testテーブルを作成し、dataファミリーカラムを作成します。
2つ目は、作ったテーブル(test)にデータを入れて(put)いきますが、user1というRow(行)を作り、その行のdata:sportsというColumn(列)の項目に、data1という値を入れています。
3つ目で作ったテーブル(test)を表示しています。
リレーショナルデータベースの場合は、このテーブルにデータを追加する場合はRow(行)を増やしていくだけで、user1に関する情報を加えるには別のテーブルを作って紐付けるやり方をします。
Hbaseの場合は、どんどんColumn(列)を増やしてuser1に関する情報を追加していくことができますので、データを追加していきましょう。
行列のデータを追加
続いて、残りの部分のデータを追加していきましょう。
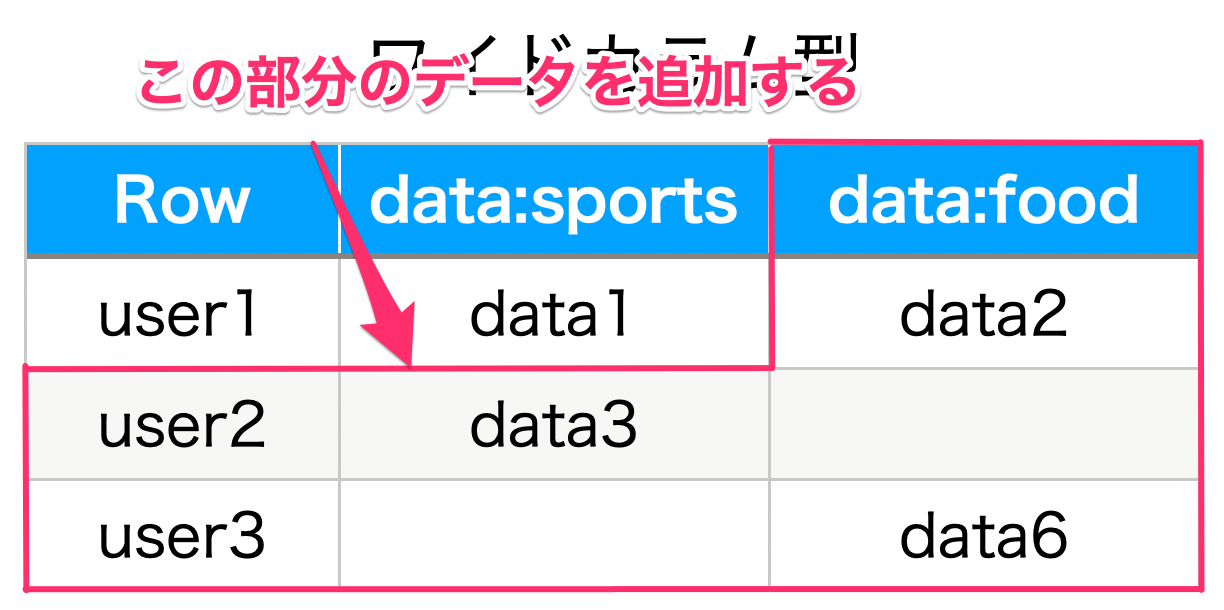
次のコードを実行します。
put 'test', 'user1', 'data:food', 'data2'put 'test', 'user2', 'data:sports', 'data3'put 'test', 'user3', 'data:food', 'data6'scan 'test'
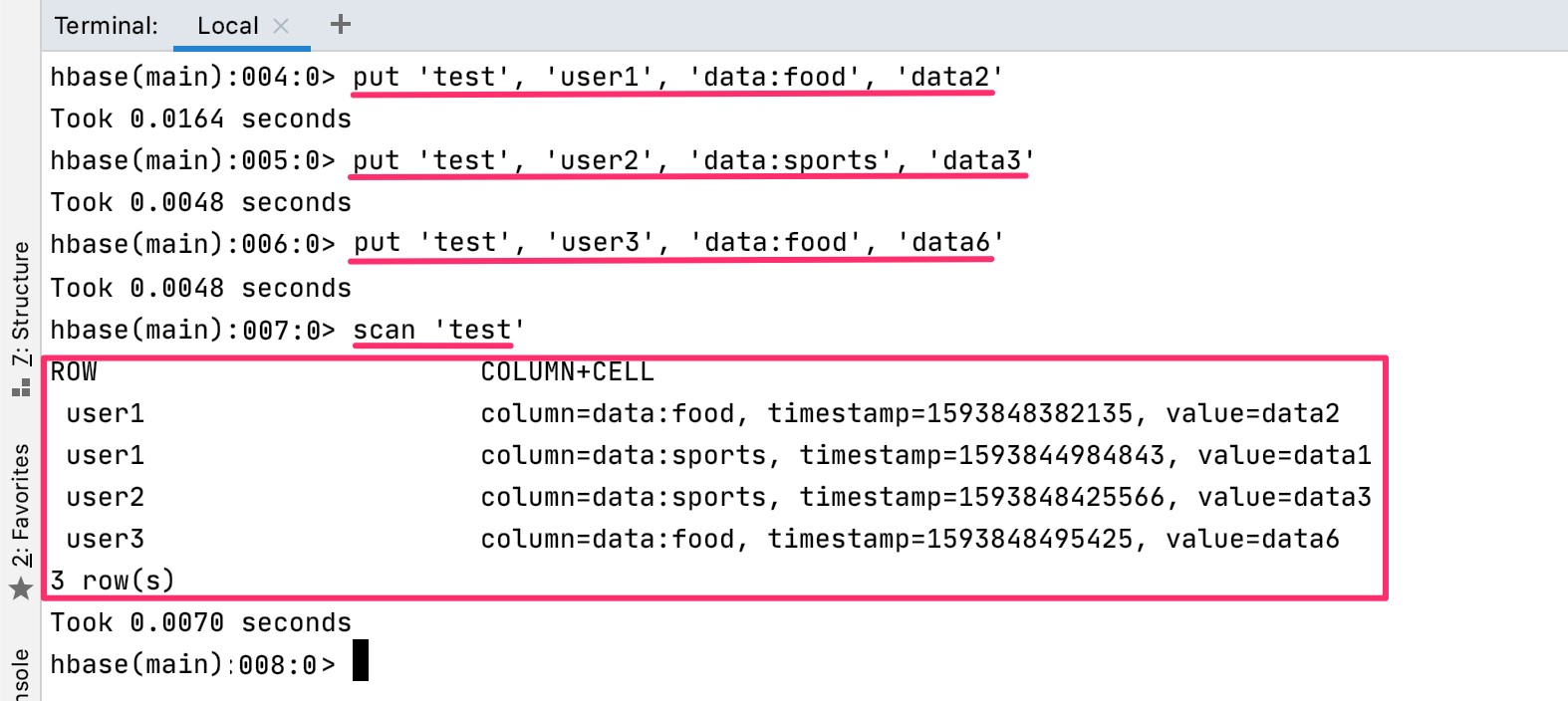
user1行のdata:sports列にはdata1、data:food列にはdata2が挿入されています。
また、user2行のdata:sports列にはdata3、user3行のdata:food列にはdata6が追加されて、3つの行が存在するのがわかります。
データを選んで取得する
次に保存されているテーブルの値を取り出してみましょう。
行を取り出すにはgetコマンドを使って、get 'test', 'user1'のように、テーブル名と行の名前を指定します。
列を取り出すには、テーブル全体を取り出すscanコマンドを使って、scan 'test', {COLUMN => ['data:sports']}のように、テーブルとカラムを指定します。
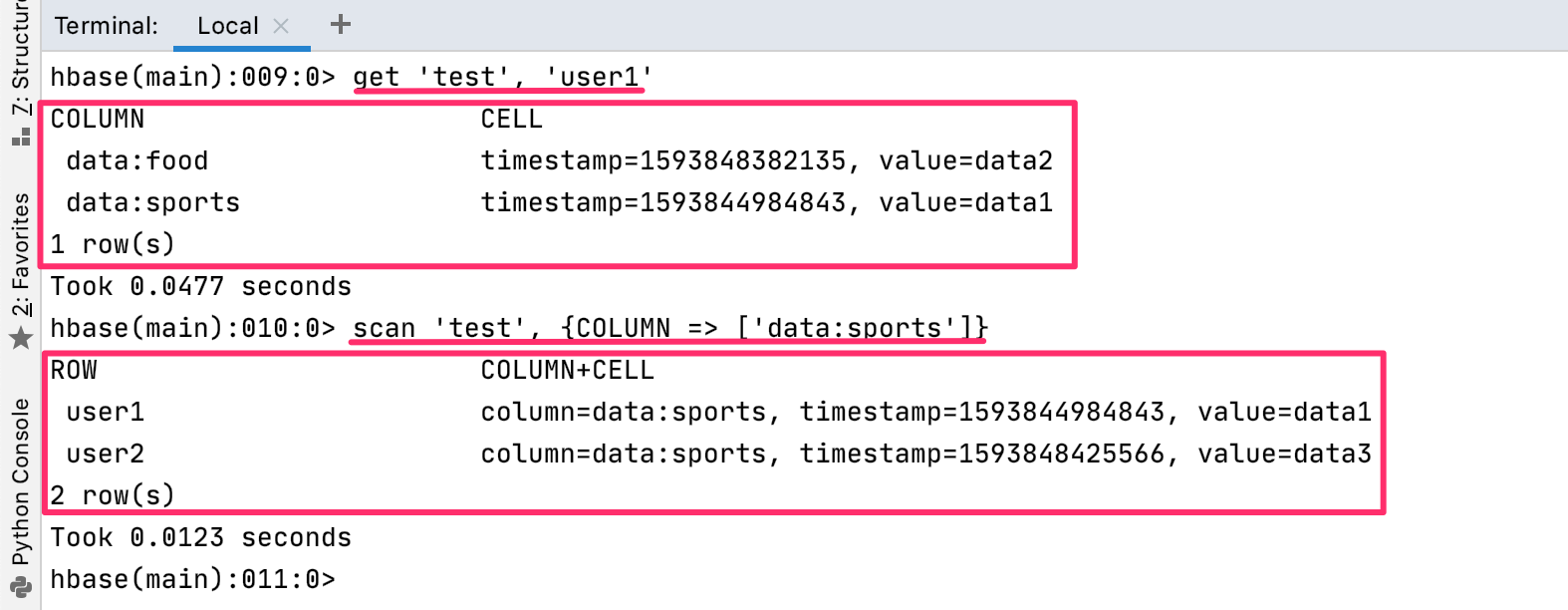
データを表示したあとに、行を指定したときは1行(1row(s))、列を指定したときは2行(2row(s))と表示されています。
値の削除
次に値を削除してみます。
user1行のdata:sports列の値を削除する場合は、次のようなコマンドを実行します。
delete 'test', 'user1', 'data:sports'
削除したあと、scan 'test'を実行してみると値が削除されているのがわかります。

行全体を削除するには、deleteallコマンドを使って、deleteall 'test', 'user1'を実行します。
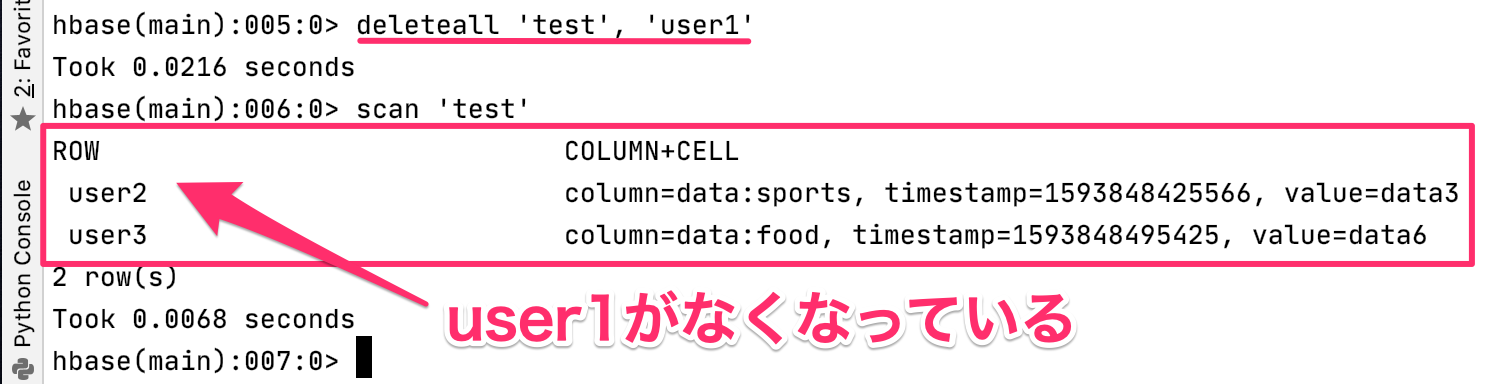
同じようにdeleteallを使って列全体が削除できないかと試してみましたが、削除することができませんでした。
一つ一つの行から列の値を1つずつ削除するしかないようです。
テーブルの削除
テーブルを削除するには、削除するテーブルを使用不可(desable)にしておく必要があります。
使用停止したあと、dropコマンドを使って削除できます。

Hbaseの終了
Hbaseのターミナルでの操作をひととおり学習してきましたが、最後にHbaseを終了するにはquitを実行します。
Hbaseの操作から抜けたあとは、stop-hbase.shを実行してHbaseを終了します。
brew services stopで終了しようと試したところ、Error: Service `hbase` is not started.とエラーになりました。
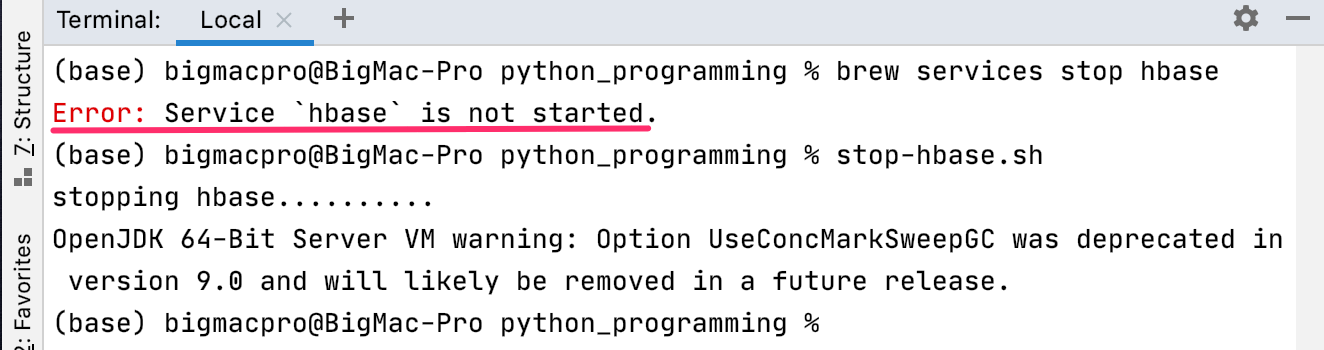
最初にbrew services startで起動させていれば、このコマンドで停止することができましたが、今度はstop-hbase.shでは停止させることができませんでした。
コマンドも対になっているということですね。
ターミナルの操作
すでに何度が伝えていますが、私はターミナルでPCを操作することに憧れを持っていました。
実際にコマンドを実行していると、スペルミスなどでエラーを起こしてしまうのですが、得体のしれない不安感はある程度なくなっていきます。
マウスを使ってビジュアル的に操作することと同じく、実行できないコマンドはエラーで知らせてくれます。
ただそれが英語で説明されるので、よくわからないことが多く、目に見えない処理をしているので、きちんと処理されているのか確認する必要があります。
コマンドを理解して、ターミナルを操作できるようになれば、めちゃくちゃ処理が早くなるので、プログラマーはターミナルなどのコマンドを使って操作するわけですね。
学校教育に例えると、いまは小学校1年生の学習をしているような感じですが、なるべく速く小学校卒業程度にはレベルアップしたいと思います。
それでは明日もGood Python!