Python学習【365日チャレンジ!】148日目のマスターU(@Udemy11)です。
欲しいと思っているアイテムを購入するときってほんとワクワクしますよね。
実はそのワクワクも、欲しい物を購入してしまうと一気に冷めてしまうことがありますが、それは欲しい物を購入するという目的を達したことで脳の活動が停止するからだという説があります。
私の場合、欲しいアイテムは釣りに関するアイテムなので、実際に使うまでが目的であり、購入してすぐに熱が冷めるということはありません。
また、釣りは満足するということがなく、釣りにいって帰ってきても、すぐに次の釣りのことを考えるので、飽きることがないんですよね。
中国のことわざに
【一時間、幸せになりたかったら酒を飲みなさい。】
〜中略〜
【永遠に、幸せになりたかったら釣りを覚えなさい。】
というものがありますが、釣りは一生の趣味にできるので、ほんとおすすめです。
【ブラックジャックによろしく】で有名な漫画家の佐藤秀峰さんもここ数年、どっぷりと釣りにはまってますからね。

それでは、今日もPython学習をはじめましょう!
昨日の復習
昨日は、MongoDBのインストールをしてPythonで使える状態にしました。
brewを使ってMongoDBをインストールするためには、単純なbrew installではエラーが出るので、別のコマンドを利用しました。
MongoDBを立ち上げたり終了したりする方法は、MySQLと同じコマンドbrew services start(もしくはstop) データベース名を使いました。
PythonファイルからMongoDBを扱うためのパッケージpymongoをインストールしておく必要もありました。
MondoDBを使うための準備については、昨日の記事を参考にしてください。

今日は、MongoDBを実際に操作していきます。
MongoDBをスタート
PythonでMongoDBを使うには、まずターミナルでbrew services start mongodb-community@4.2を実行してMongoDBを稼働します。
そのあと、データベースを保存するディレクトリ(mdb)を作って、コマンドmongod --dbpath ./mdbを実行すれば、MongoDBを扱う準備が整います。
Pycharmの左に表示されるディレクトリにはmdbフォルダが作成され、必要なファイルが準備されています。
とはいえ、どれがどんなファイルなのかはわかりませんけどね。。。
MongoDBの使い方
それでは、MongoDBのコードを書いていきましょう。
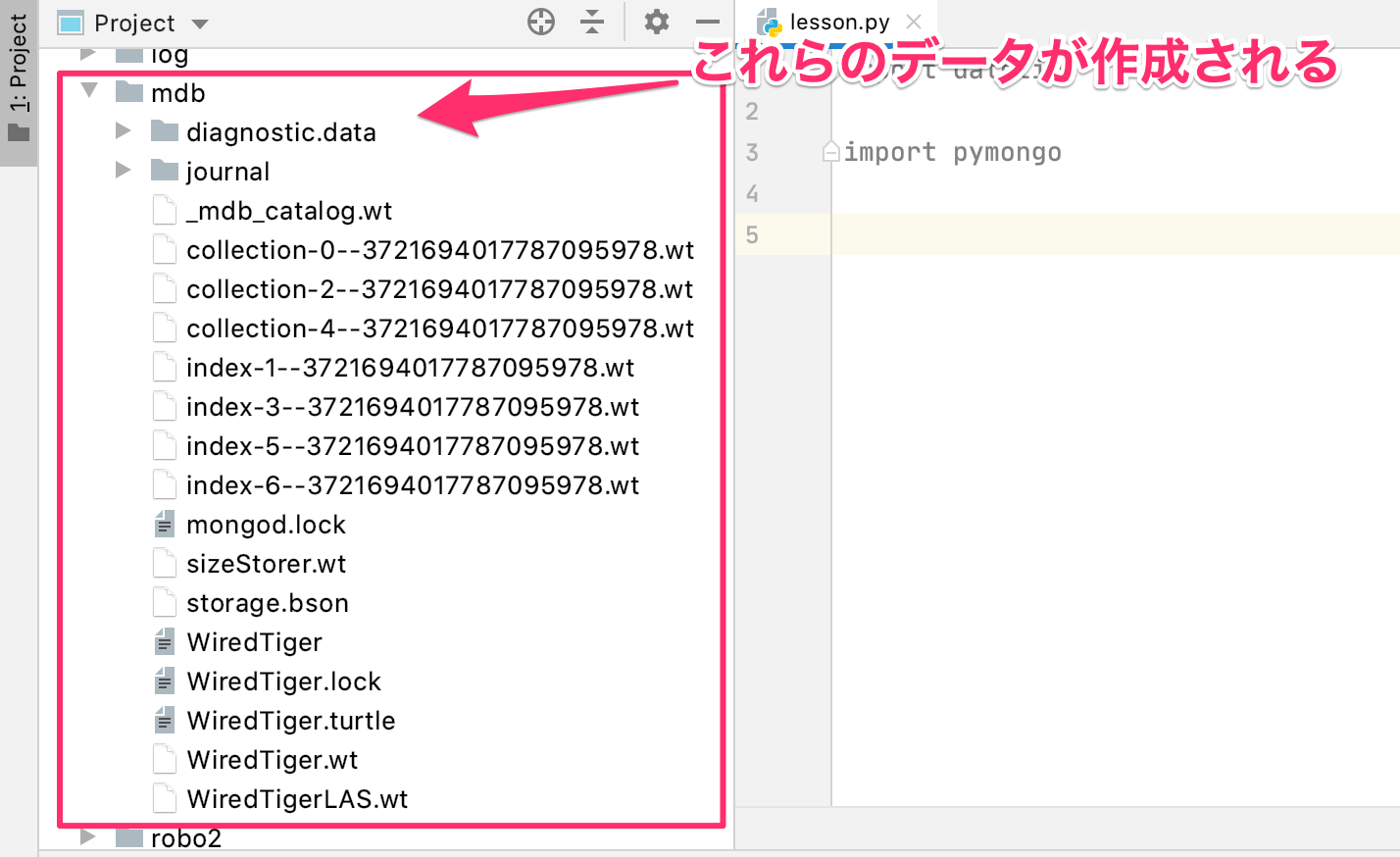
import datetime
from pymongo import MongoClient
client = MongoClient('mongodb://localhost:27017/')
db = client['test_db']
stack1 = {
'name': 'customer1',
'pip': ['python', 'java', 'go'],
'info': {'os': 'mac'},
'date': datetime.datetime.utcnow()
}
db_stacks = db.stacks
stack_id = db_stacks.insert_one(stack1).inserted_id
print(stack_id, type(stack_id))
print(db_stacks.find_one({'_id': stack_id}))出力結果
5efc8a65d8cf13d6836ea58f <class 'bson.objectid.ObjectId'>
{'_id': ObjectId('5efc8a65d8cf13d6836ea58f'), 'name': 'customer1', 'pip': ['python', 'java', 'go'], 'info': {'os': 'mac'}, 'date': datetime.datetime(2020, 7, 1, 13, 6, 45, 354000)}ホストへの接続はMySQLと同じような感じで、6行目で接続しています。
localhostの部分は127.0.0.1でも問題ありません。
動作を記録した時間を残すため、1行目でdatetimeを読み込んで、3行目で昨日インストールしたpymongoからMongoClientモジュールを読み込みます。
6行目は、データベースへのログインで、その後データベースtest_dbを作って、9行目から14行目で、JSON形式でname、pip、info、dateのデータを作成します。
16行目、17行目で、先程作成したstack1の値をデータベースに保存します。
イメージ的には、MySQLのテーブルにデータを保存するイメージです。
18行目では、保存したデータとタイプを出力しています。
出力結果を見ると、不規則な文字が並んで、タイプはbson.objectid.ObjectIdとなっていますが、MongoDBでは、データが挿入されると、自動的に_idという名前のカラムが作られて、自動的に値が作成されます。
それがこの値で、文字列ではないオブジェクト(ObjectID)となります。
19行目では、データベースの中から自動的に作成された_idをstack_idで検索して表示するコードになります。
表示結果には、自動で挿入されたObjectIDが最初に表示されているのがわかります。
酒井さんのレクチャーをみたときは、このObjectIDの情報を知らなかったので、_idと言われても一体何のことかわかりませんでした。
ネットで調べてみると、MongoDBはデータ挿入の際に、自動的にidが振り分けられるObjectIDというオブジェクトで、自動的に_idカラムが作成されるということがわかり、レクチャーの内容が理解できるようになりました。
酒井さんの講座のデータベースのレクチャーは、それぞれの触りだけをやっているので、自分で調べないといけない部分が多いですね。
ちなみに、19行目では、stack_idで検索しているので、出力した値である5efc8a65d8cf13d6836ea58fを入れた変数で検索しても問題ないように感じますが、このやり方だとエラーが出ます。
検索結果をきちんと出力するためには、ObjectIdモジュールをインポートして検索する必要があります。
18行目以降の部分だけ変更してみたコードがこちら。
from bson.objectid import ObjectId
str_stack_id = '5efc8a65d8cf13d6836ea58f'
print(db_stacks.find_one({'_id': ObjectId(str_stack_id)}))出力結果
{'_id': ObjectId('5efc8a65d8cf13d6836ea58f'), 'name': 'customer1', 'pip': ['python', 'java', 'go'], 'info': {'os': 'mac'}, 'date': datetime.datetime(2020, 7, 1, 13, 6, 45, 354000)}他の検索方法としては、わかっているkeyとvalueを指定して検索する方法があります。
print(db_stacks.find_one({'name': 'customer1'}))出力結果
{'_id': ObjectId('5efc8a65d8cf13d6836ea58f'), 'name': 'customer1', 'pip': ['python', 'java', 'go'], 'info': {'os': 'mac'}, 'date': datetime.datetime(2020, 7, 1, 13, 6, 45, 354000)}この検索を具体的にどのように使うのかは今後の学習で理解していく必要がありますが、実際にコードを書いてみることで、全くわからなかったコードが少しは理解できるようになります。
検索方法
valueに複数の値が入っているリストや辞書型でも検索することが可能ですが、その場合は、きちんとすべての値を指定しないと検索結果にヒットしません。
例えば、'pip': ['python', 'java', 'go']で検索するのなら、このままfind_oneの引数に入れる必要があるということです。
print(db_stacks.find_one({'pip': ['python', 'java', 'go']}))例えば、python、java、goのうち、1つでも抜けると検索に引っかからないので、上記のように、すべての値を入れる必要があります。
続いて、最もよく使われる日付からの検索ですが、複数のスタックを保存している場合は、forループを使って、次のようにコードを書けば、現在より前のタイムスタンプのデータを抽出することができます。
now = datetime.datetime.utcnow()
for stack in db_stacks.find({'date': {'$lt': now}}):
print(stack)$ltはless thanの意味で<と同じです。
$gtはgreater thanで>と同じことですね。
同じコードを何度も実行すると、17行目のコードを実行するたびにstack_idを生成してしまうので注意が必要です。
また、MongoDBの使い方としては、大量にデータをデータベースに入れておいて、あとで検索するやり方がメインで使われているとのことです。
データの更新
続いて、データの更新作業をやってみましょう。
変更するのは17行目以降です。
db_stacks.find_one_and_update({'name': 'customer1'}, {'$set': {'name': 'user00'}})
print(db_stacks.find_one({'name': 'user00'}))出力結果
{'_id': ObjectId('5efc7c407b03a61f3fb7fa9a'), 'name': 'user00', 'pip': ['python', 'java', 'go'], 'info': {'os': 'mac'}, 'date': datetime.datetime(2020, 7, 1, 12, 6, 24, 791000)}データの更新にはfind_one_and_updateを使って、第一引数に検索値、第2引数に新しく更新する値を入力します。
出力結果で、’name’が【user00】に変更されているのがわかるかと思います。
データの削除
最後にデータの削除をする命令文はdelete_one()を使います。
db_stacks.delete_one({'name': 'user00'})
print(db.stacks.find_one({'name': 'user00'})17行目でデータを削除しているので、18行目でnameがuser00のものは見つからず、Noneが返されます。
ほんのさわり
酒井さんの講座で学習するデータベースはどれも一緒ですが、学習しているのはほんのさわりだけです。

私の場合、さわりの部分だけでもわからないことがいっぱいあって、ネットで調べまくっているのですが、理解できるまでに結構な時間がかかってしまいます。
自分のものにするためには、このような地道な作業が必要なので、継続して学習することを意識していこうと思います。
それでは明日もGood Python!