
なんとか目標の1週間をクリアできたPython学習7日目のマスターU(@Udemy11)です。
昨日までは、バックスラッシュの使い方を学びましたが、復習をしておきます。
- 文中の’を表示するための【\】
- 改行を出力するための【\n】
- 文中の【\】をそのまま表示するための【r】
- 改行の出力を無効にする【\】
- 変数定義の際にコードを見やすくするための【\】
4つ目と5つ目は出力の際の改行を無効にするためなので、同じ使われ方ですが、printの際に書くか、変数定義の際に書くかの違いがあります。
それでは、今日も復習と合わせて新しいく学んだことを紹介します。
記事の内容は、酒井潤さんの講座を参考にさせていただき、学習した内容を紹介しています。
Pythonをひととおり学習したい人にはピッタリの講座で、セールの際は、値段も専門書1冊の値段よりも安く受講できるので、超おすすめの講座です。
昨日までの復習コード
昨日の復習コードを書いてみましょう!
print('I don\'t know')
print('Hi,Mike\nHow are you?')
print(r'C:\name\name')
print("""\
Line1
Line2
Line3\
""")
x = 'ggggggg'\
'jjjjjjj'
print(x)出力データ
I don't know
Hi,Mike
How are you?
Line1
Line2
Line3
gggggggjjjjjjj人の記憶は、復習しないとどんどん忘れてしまいます。
一度聴いただけの情報は、次の日に90%以上忘れてしまっているそうです。
でも、すぐに復習したり、何分後、何時間後に同じことを復習すると記憶に残るパーセンテージが上がることがわかっています。
つまり、何度も何度も繰り返して実行すれば、しっかりと記憶が定着するということです。
継続は力なり
ですね。
リテラルとは
酒井さんの講座を受講していると、プログラミングの現場で使われている専門用語が色々と出てきます。
例えば、丸括弧がparentheses(パレンテス?パーレン)だったり、角括弧がbracket(ブラケット)だったり、Pythonとは関係のないところで感心したりしています。
今回新しく登場したのが【リテラル(literal)】で、シングルクォーテーションで括られている部分のことを指す言葉になります。
英語のliteralは「文字どおり」「定義どおり」を意味するように、ソースコードのなかに直接記述した定数のことです。
リテラルと変数のあわせ技

定義された変数とリテラルを組み合わせて出力することができるのですが、このあわせ技には、注意点があります。
print出力で、リテラルを2つそのまま続けて入力しても、間に数式の【+】を入れても同じように、2つの文字をつなげて出力することができます。
print('Py' 'thon')
print('Py' + 'thon')しかし、変数xとyに文字列を代入したあと、print出力をする場合、xとyは【+】でつなげる必要があります。
また、変数とリテラルを繋げる場合も【+】を使えば、つなげて出力することができます。
x = 'Py'
y = 'thon'
print(x + y)
print(x + 'thon')出力結果は全て【Python】になります。
ちなみにprint出力に変数を続けて入力する場合に【,(カンマ)】で続けると、間にスペースが入って出力されます。
print(x, y)出力結果
Py thon酒井さんの講座の一番最初のチャプターで説明がありましたが、このスペースをカンマや他の文字に変更する場合は【sep = ‘,’】を追加すれば出力されます。
print(x, y, sep = ',')出力結果
Py,thonあと、出力の最後に改行を指定する【end = ‘\n’】もチラッと触れていましたが、改行を指定せずに使うと、改行されずに次のコードのprint出力に繋がります。
print(x, y, end = '!')
print(x , y)出力結果
Py thon!Py thon普通にprint出力すれば末尾に改行が入るので、endを使うと改行が無視されるからかもしれません。
まー、こんな使い方する人はいないんでしょうけど。。。
変数出力の注意点
リテラルの場合は、print出力の際に、【+】で繋げなくても、そのまま続けて入力すれば、エラーは起こらずに出力されますが、2つの定義された変数を使う場合は、必ず【+】でつなげる必要があります。
NG print(x y)
NG print(x 'thon')初心者からすると、リテラルと同じように続けて入力しても大丈夫なんじゃないかと思ってしまいますが、このあたりのルールは間違いながら覚えるしかありません。
スライスで指定したindexの文字を抽出
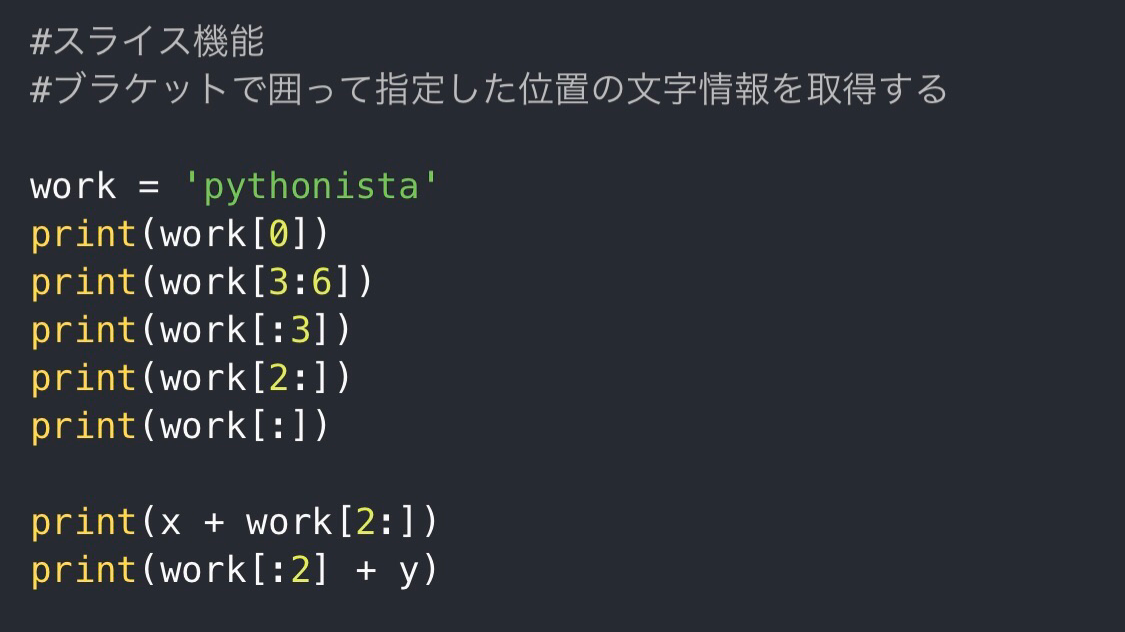
続いて、定義した文字列の中の指定した位置(index)の文字を抽出するために使うのが、blacket(角括弧)です。
文字を抽出するから【スライス】と言われてるんでしょうね。
上のコードは【pythonista】を代入したworkという変数の指定した位置にある文字を出力するコードですが、1行目から順番に見ていくとこうなります。
print(work[0])0番目の位置(最初の文字)を出力します。
print(work[3:6])3番目の位置(4つ目)から6番目の位置(7つ目)の前の文字までを出力します。
print(work[:3])最初の位置を省略することもできるので、こちらは、最初から3番めの位置(4つ目)の前の文字までを出力します。
print(work[2:])最初の位置と同様に、後ろの位置も省略することができるので、これは、2番めの位置(3つ目)から最後の文字までを出力します。
print(work[:])最初も最後も省略することもできますが、意味がないので、普通にprint(work)としたほうがいいですね。
最後の2行は、上記のあわせ技の説明の際に定義していたxとyを活用しています。
xには’Py’、yには’thon’が代入されています。
print(x + work[2:])
print(work[:2] + y)リテラルと変数のあわせ技同様に、変数とスライスも合わせて利用することが可能です。
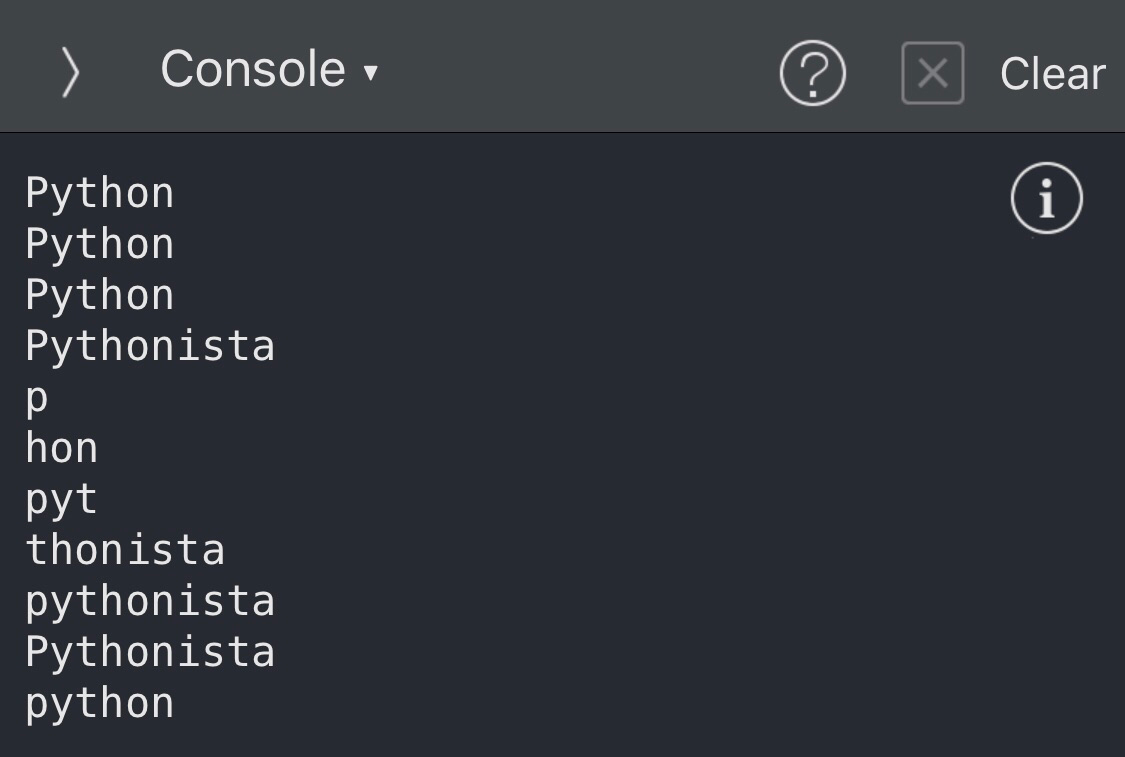
出力される結果はこちら。
p
hon
pyt
thonista
pythonista
Pythonista
pythonあと一つ忘れていたのですが、最後の文字を出力するには、blacketに-1を入れます。
print(work[-1])出力結果
a
トライアンドエラー
基本的に、間違えれば間違えるほどコードの書き方がわかってきます。
つまり、きちんと動いているときは、間違っているわけじゃないので、間違いがわかりません。
間違いがわかると、間違わなくなりますが、間違わないとエラーが起こったときに慌ててしまいます。
どんどんエラーを体験してコードを覚えていきましょう!
もう、どれだけエラー出力したのかわからなくなりました(笑)
ちなみに、トライアンドエラーは間違った使い方だそうで、正しくは【trial and error】のようです。
ではでは、Good Python!
