Python学習【365日チャレンジ!】325日目のマスターU(@Udemy11)です。
あけましておめでとうございます。
2021年が始まりましたね!
とはいえ、コロナの影響で、初詣も実家への年始の挨拶も自粛で家でおとなしく過ごしています。
いつもと変わらずPythonのコードを書いているので、普段とあまり変わりない年明けになりました。
それでは今年も変わらず、Python学習を始めましょう。
昨日の復習
昨日は、データ解析の最初の段階である【データウェアハウス】について学習しました。
はじめ見たときは、データシェアハウスだと思いこんでいたのですが調べていくうちに【データウェアハウス】が正しいことに気づきました。
データ解析の最初の段階であるデータ収集で、データを取得して保管しておくことで、アップルの株価とオリエンタルランドの株価の情報を取得してみました。
Yahoo Fianceが手っ取り早く株価の取得に使えるのですが、日本の銘柄は取得できないので、世界の株価をAPIで提供しているStooq.comを活用して、2つの違うコードで同じ結果を出力してみました。
くわしくは、昨日の記事をごらんください。

今日は、集めたデータをもとにどのような傾向になっているのかを指標を使って判断するための統計学について学習します。
統計
統計とは
集団における個々の要素の分布を調べ、その集団の傾向・性質などを数量的に統一的に明らかにすること。また、その結果として得られた数値。
引用元: 統計とは?
統計はつまり、データの関係性を調べて傾向などをみつけることなので、いろいろな指標を使ってデータの傾向を掴む必要があります。
指標は作ろうと思えばいくらでも作れるので、統計しやすい情報を手に入れて指標にすることが大切になってきますが、傾向は1つの指標ではなく、多方面からの指標を検討して検証することが、結果の信頼性を上げることに繋がります。
ということで、昨日調べた株価のデータシェアハウスを活用して、統計をしてみたいと思います。
Simple Moving Avarage
Simple Moving Avarageは、過去何日か分の平均値をとって、現状と比較することで先の流れを予想する方法です。
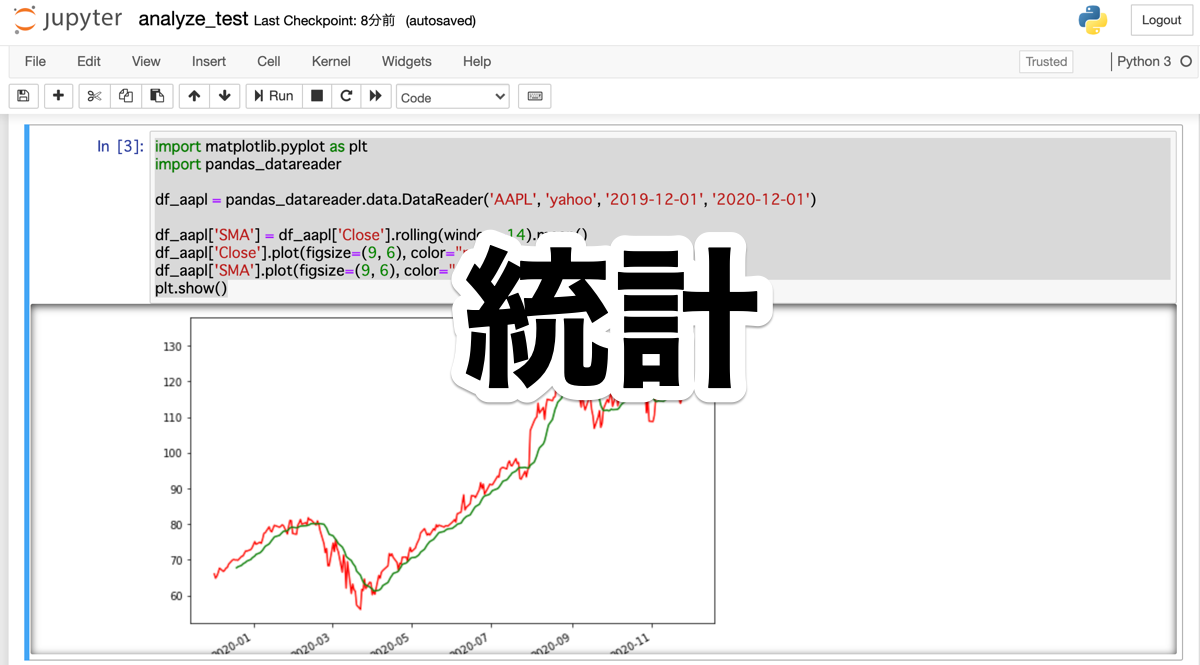
import matplotlib.pyplot as plt
import pandas_datareader
df_aapl = pandas_datareader.data.DataReader('AAPL', 'yahoo', '2019-12-01', '2020-12-01')
df_aapl['SMA'] = df_aapl['Close'].rolling(window=14).mean()
df_aapl['Close'].plot(figsize=(9, 6), color="red")
df_aapl['SMA'].plot(figsize=(9, 6), color="green")
plt.show()データウェアハウスに、アップルの2019年12月1日から2020年12月1日までの株価のデータをdf_aaplとして保存します。
次に、df_aaplに新しいSMA列を追加しますが、この値は、その日の終値の過去14日分の平均値を指定しています。
グラフの表示を9:6にして、Closeは赤線、SMAは緑の線で折れ線グラフを描写しています。
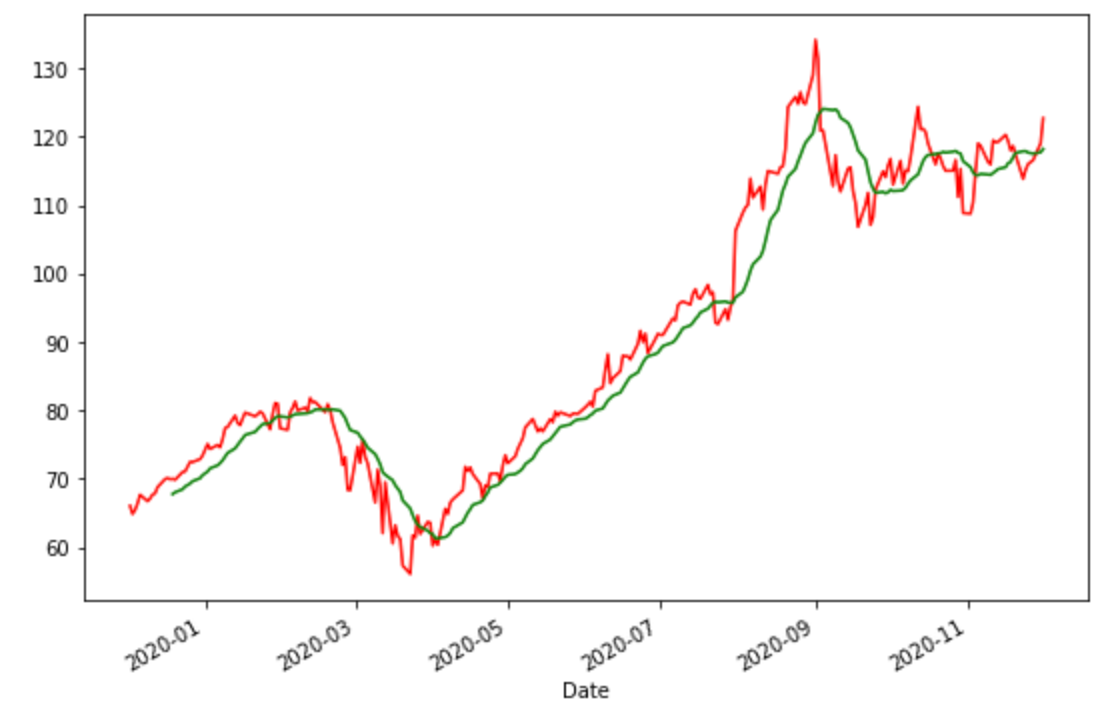
このグラフから何を見るかというと、過去の平均と現状の株価を重ね合わせることで、2つのグラフがクロスしたところで、株の売り買いを判断する材料にすることができます。
つまり、過去14日間の平均株価より現状が下がっているということは、売りが強くなり、株価が下がっているということなので、売りのタイミングで、その逆は、買いのタイミングと判断できるということです。
テクニカル指標
このSimple Moving Avarage以外にも、株価の分析には、いろいろな指標が用意されていますが、Simple Moving Avarageはトレンド分析に分類され、次のような指標があります。
- MACD
- ボリンジャーバンド
- 一目均衡表
- DMI
他にもいろいろと指標があって、証券会社のサイトでは詳しく解説されたものがあるので、参考にしてみてください。

まとめ
集められたデータウェアハウスを元に統計学によってデータを分析、可視化することが2つ目の段階ですが、ここまでである程度データ分析はできるのですが、やはり傾向がつかめるというレベルでしかないので、もっと深くデータを活用して精度を上げる必要があります。
例えるなら、職人さんの勘は信頼度は高いものの、あくまでも個人の頭の中に蓄えられた不正確な情報を元に導き出されているものですが、それをデータ化して、分析することで、より精度が上がります。
職人の勘に頼るのではなく、圧倒的なデータをさまざまな視点から分析を加えることで、より正確な予測が可能になるということですね。
明日は、データから新しい予測を発掘するデータマイニングを学習したいと思います。
それでは、明日もGood Python!