Python学習【365日チャレンジ!】324日目のマスターU(@Udemy11)です。
いよいよ2020年ももうすぐ終了しますね。
今年は、ほんとに新型コロナウイルスに翻弄された1年でしたが、政治家の無能ぶりがよくわかった1年でもありました。
現状の新型コロナ感染者数を見ると、4月の緊急事態宣言は何だったんだろうと思ってしまいますよね。
ワクチンが供給されて少しは安堵したのもつかの間、イギリスでは変異した亜種のコロナウイルスが日本でも見つかって、2021年も亜種のコロナウイルスに翻弄されそうな予感はします。
ただ、これまで冬になると注意喚起されていたインフルエンザは、2020年11月時点での患者数が例年の100分の1に減っているというデータもあるそうなので、国民がマスクをして、感染予防対策をすれば、空気感染を起こすインフルエンザも蔓延しないという貴重なデータが取れたんじゃないでしょうか?
ある意味、ここまで大規模な実験ができているということなので、超少数派のできる政治家の方には、このデータを今後の感染予防対策に生かした政策を考えてもらいたいものです。。
それでは2020年最後のPython学習を始めましょう。
昨日の復習
昨日は、機械学習ライブラリのscikit-learnを学習しました。
scikit-learnは、教師あり学習、教師なし学習などの機械学習をすることができるオープンソースのライブラリです。
機械学習のためのソースもライブラリに用意されているので、ボストンの住宅情報データベースサンプルを使って、線形回帰と散布図を組み合わせたグラフを描写しました。
くわしくは、昨日の記事をごらんください。

今日は、データ解析のまとめとして、処理工程ごとの役割を学習していきます。
データウェアハウス
今日は、データ解析に必要不可欠であるデータウェアハウスについて、確認していきたいと思います。
データウェアハウスとは
データウェアハウスとは、企業などの業務上発生した取引記録などのデータを時系列に保管したデータベース。また、そのようなシステムを構築・運用するためのソフトウェア。“warehouse” は「倉庫」の意。
引用元: データウェアハウス 【 DWH 】
要するに、データ解析のためのデータを格納しているデータベースということですね。
これまでに学習してきたセッションでは、最終的に株価の予測ができるプログラムに仕上げる予定ですが、その元になるデータを集めて保管する場所がデータウェアハウスということです。
まずは株式市場の株価データを集めてみます。
アメリカ株式市場の株価を取得する
DataReaderを使えば、株価コード、取得するサイト、データ取得開始日などを指定することで、簡単にAPIから株価の情報を取得することができます。
まずは、pipでpandas_datareaderをインストールしておきます。
pip install pandas_datareaderインストールが完了すればDataReaderを使えるようになりますが、引数は次のように指定します。
pandas_datareader.data.DataReader('株価コード','取得元サイト名','開始日','終了日')取得元サイトは、無料でデータを取得できるサイトが減ってきているようで、【Yahoo Finance】が最も手軽に利用できるサービスで、取得できる情報は以下の項目になります。
- Open:始値
- High:高値
- Low:安値
- Close:終値
- Volume:出来高
- Adj Close:配当込み分割調整後株価
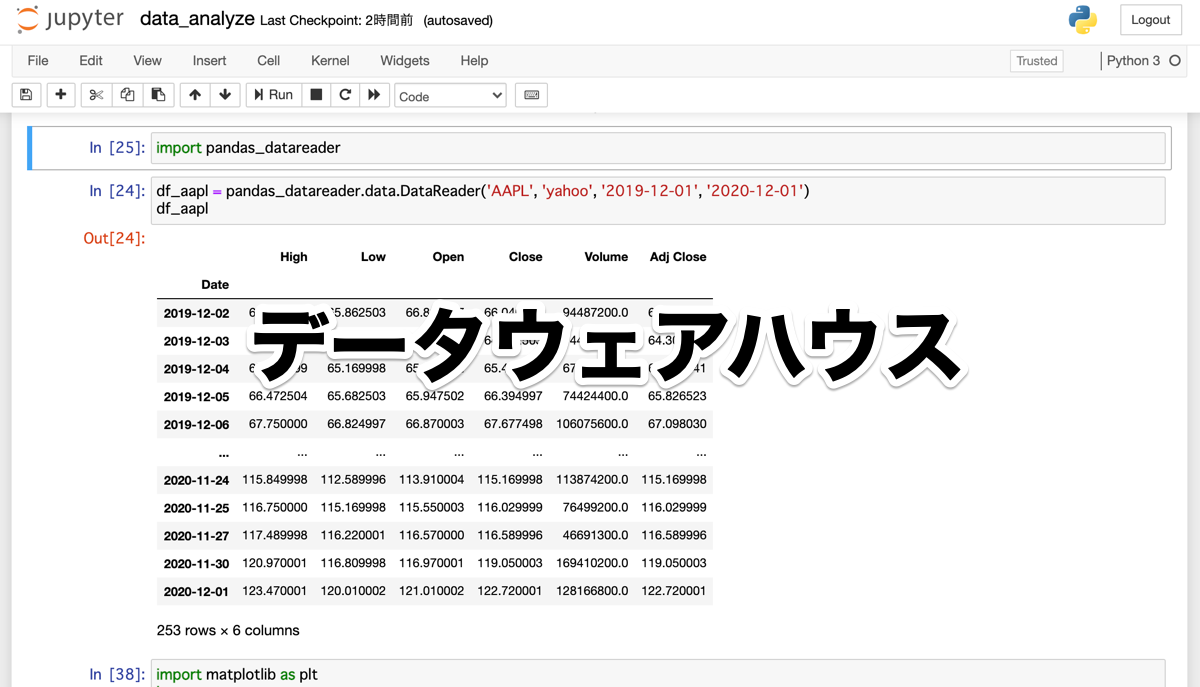
それでは、Yahooからアップルの株価を取得してみましょう。
import pandas_datareader
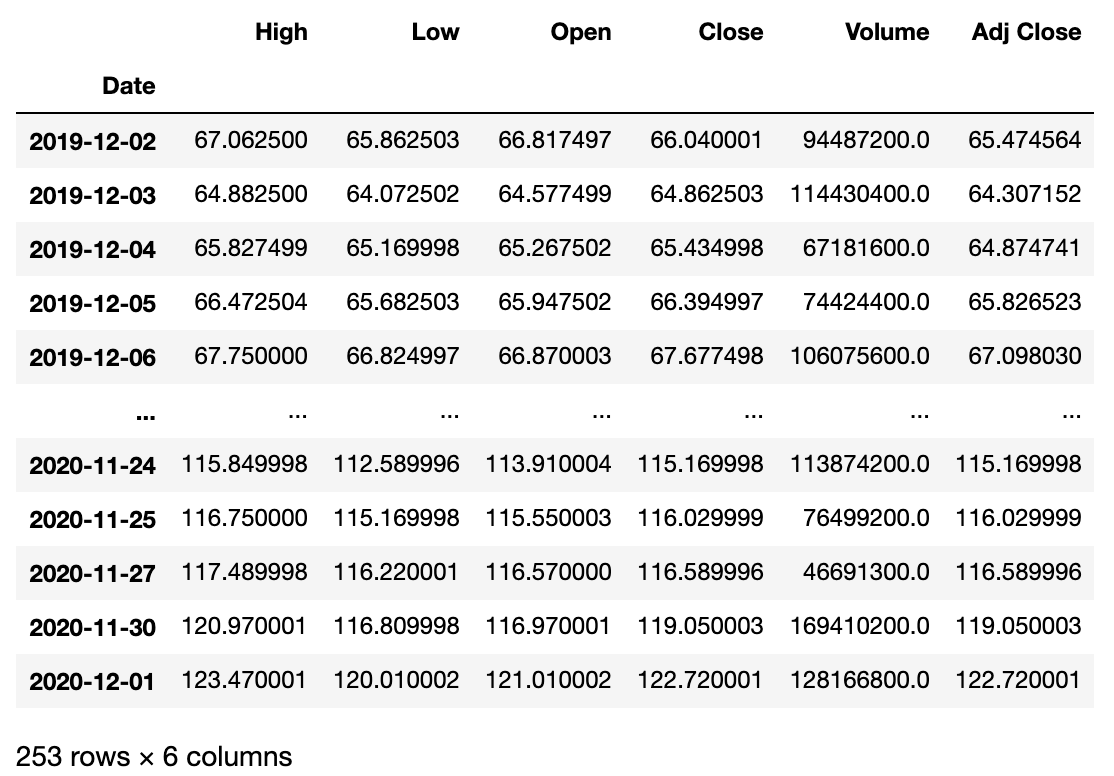
df_aapl = pandas_datareader.data.DataReader('AAPL', 'yahoo', '2019-12-01', '2020-12-01')
df_aaplAAPLがアップルで、yahooがヤフーファイナンス、あとは始まりと終了の日付を引数で指定しています。
日本株式市場の株価を取得する
Yahooから株価を取得できるのは、アメリカの株式市場に上場している会社だけなので、Yahoo Financeからは、日本の株式市場に上場している会社の株価は取得できません。
そこで、Stooq.comが登場するわけですが、こちらのサイトから日本の株式市場の情報を取得することができます。
取得できるデータは、Yahoo Financeよりひとつ少ない次の項目です。
- Open:始値
- High:高値
- Low:安値
- Close:終値
- Volume:出来高
Stooq.comから東京ディズニーリゾートを運営するオリエンタルランド(4661)のデータを取得します。
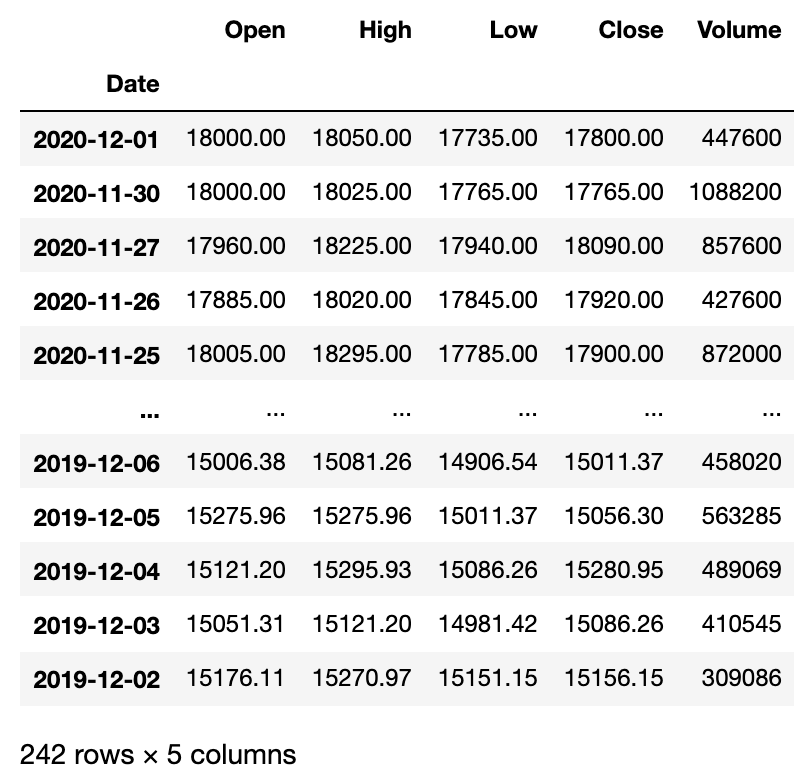
df_olc = pandas_datareader.data.DataReader("4661.JP", "stooq", "2019-12-01", "2020-12-01")
df_olc日本の株式は数字と.JPを付けて第1引数を指定し、取得元はstooqを指定します。
あとは、取得する最初と最後の日付を指定して、データを出力しています。
まとめ
Webスクレイピングを使って株価を提供しているサイトからデータを取得する方法もありますが、pandas_datareaderを利用すれば、1行コードを書くだけで、APIを提供しているサイトからデータを取得できるので、すごい便利なライブラリです。
ちなみに、日本の株価を取得できるStooq.comですが、pandas_datareaderには、専用のクラスStooqDailyReaderが用意されているので、次のコードでも同じデータを取得することができます。
df_olc = pandas_datareader.stooq.StooqDailyReader("4661.JP", "2019-12-01", "2020-12-01")
df_olc.read()同じ結果が得られますが、コードは違ってくるので、どちらを使うかは、好みのもんだいですね。
このように、取得してきたデータを保管しておくのがデータウェアハウスということで、このデータウェアハウスのデータを活用して、次のデータから客観的な指標を得る統計に進んでいきます。
2020年最後のエントリーになりましたが、明日の新年からもしっかりと継続して学習していきたいと思います。
それでは、明日もGood Python!