Python学習【365日チャレンジ!】323日目のマスターU(@Udemy11)です。
ふるさと納税でおせち料理を頼んでいるとはいえ、このお正月は、初詣にも実家にも行かないことにしているので、おせちだけでは家で食べる料理が少ないため、いろいろと買い込んで冷蔵庫の中がパンパンになっています。
以前紹介した自家製チャーシューも仕込んだので、間違いなくお正月で5kgは太ってしまいそうです。
天気予報では、年末年始にこの冬一番の寒波が襲ってくるそうなので、お家で大人しくするのが一番いいのかもしれませんよ。
国民のことを考えない政治家の一連の行動は許せませんが、なんだかんだいって自分のことを守るのは自分なので、しっかりとリスクマネージメントしていきましょう。
それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、グラフ描写ライブラリのMatplotlibを学習しました。
折れ線グラフや棒グラフ、円グラフ、凡例の表示など、グラフの応用的な描写方法について学習しましたが、昨日学習した内容はMatplotlibのほんの一部ですので、自分でコードを書いて、いろいろなグラフを表示させてみてください。
昨日の記事はこちらからごらんになれます。
今日は、機械学習ライブラリのscikit-learnを学習します。
scikit-learnとは
scikit-learnはサーキットラーンと読み、公式ドキュメントもしっかりと用意されている初心者でも使いやすいオープンソースの機械学習ライブラリです。
大量のデータをコンピューターが学習し、データを分類したり、データの推移を予想するアルゴリズムやモデルを自動的に作り出すのが機械学習で、【教師あり学習】【教師なし学習】などがあります。
【教師あり学習】は、正しい答え(データ)を与えた状態で学習させる方法で、代表的なものが連続する数値を予測する【回帰】とデータがどのグループに属するかを判断する【分類】です。
【教師なし学習】は、正しい答え(データ)を与えない状態で学習させる方法で、一例として、大量のメールを似たような内容でグループ分けするような使い方ができますが、グループが何を表すかについては、正しい答えを教える必要があります。
scikit-learnは、どちらの処理も可能で、いろいろな学習方法が用意されていて、公式チュートリアルからお手軽簡単な機械学習モデルを作ることができます。

load_boston
scirkit-learnの公式チュートリアルにはサンプル用のデータが用意されているので、その中のボストンの住宅情報が入ったサンプルデータが入ったload_bostonを使って機械学習を進めていきます。

pipでscirkit-learnをインストールして、必要なライブラリをインポートしたあと、load_bostonから取得できるデータを表示してみます。
pip install scikit-learnimport matplotlib.pyplot as plt
import pandas as pdimport sklearn.datasets
import sklearn.linear_model
import sklearn.model_selectionboston = sklearn.datasets.load_boston()
df = pd.DataFrame(boston.data, columns = boston.feature_names)
dfmatplotlibとsklearn.linear_model、sklearn.model_selectionは、ここまでのコードでは必要ありませんが、あとから必要になるので、インポートしています。
load_bostonからbostonオブジェクトを作成し、dfにboston_dataを入れて列の項目に名前を入れたデータフレームを代入して表示しています。
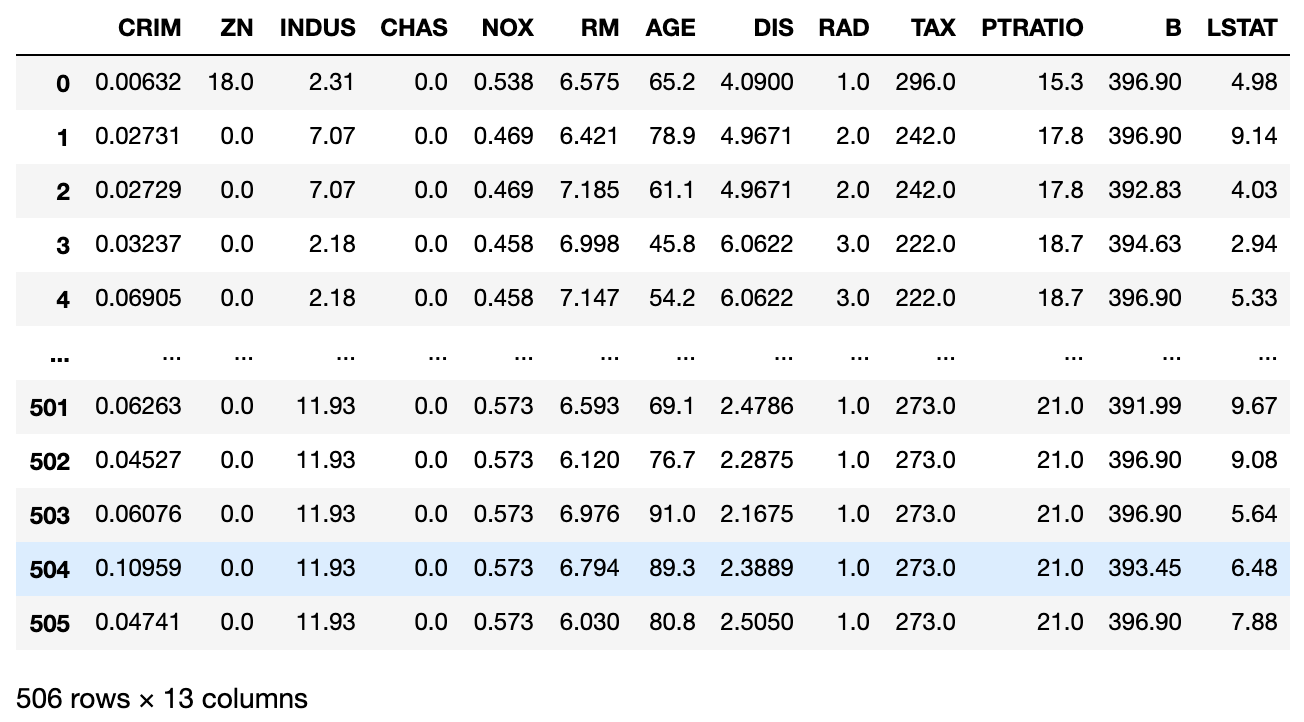
犯罪率や年齢、部屋の数などが入った506行13列のデータが表示されていますが、Xとyに値を入れてデータの学習と検証をしていきます。
LinearRegression
LinearRegrassionは、線形回帰で、データを学習して、値の増減がどうなるのかを予測するモデルになります。
取得したボストンの住宅事情と住宅価格を分析して、今後の予測を線形回帰で表しますが、先に、データをテスト用とトレーニング用に分けてそのスコア(信頼度)を出してみます。
X = boston.data
y = boston.targetX_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, test_size=0.2)lr = sklearn.linear_model.LinearRegression()lr.fit(X_train, y_train)
# LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)lr.score(X_test, y_test)
# 0.7870110014292988scikit-learnでは、分析するデータをX、ターゲットにするデータをyで扱います。
最初に分析のための情報boston.dataをXに代入し、ターゲットとなるboston.target(住宅価格)をyに代入しています。
次に、トレーニングデータとして、X_train、y_train、テストのためのデータX_test、y_testとして、test_size=0.2で、テストデータを20%に設定します。
次に、線形回帰のモデルクラスからlrオブジェクトを生成し、lr.fit(X_train, y_train)で、データに基づいてパターンを学習します。
最後に、lr.scoreで、テストデータをもとに、どの程度正確なパターンになっているかを出力していて、約78.7%がパターンに適合しているという結果が得られていることがわかります。
線形回帰を描写
次に、線形回帰を描写していきますが、グラフの描写は【Plotting Cross-Validated Predictions】のサンプルデータからそのままコピーペーストして使います。
predicted = lr.predict(X)fig, ax = plt.subplots()
ax.scatter(y, predicted, edgecolors=(0, 0, 0))
ax.plot([y.min(), y.max()], [y.min(), y.max()], 'r', lw=2)
ax.set_xlabel('Measured')
ax.set_ylabel('Predicted')
plt.show()先にXつまりboston.dataをlr.predictに入れて、predictedオブジェクトを作ります。
最後の6行が線形回帰のグラフを作成するコードですが、x軸、y軸にラベルを付けて、散布図(scatterと最小値と最大値を結んだplotの2つのグラフを描写しています。
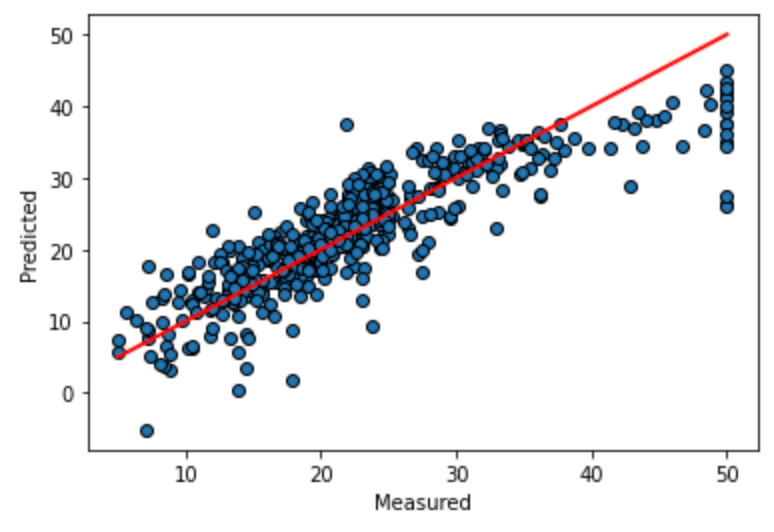
サンプルコードをそのままコピーしたあと、ここいじったらこうなるんじゃないかなと思って、'r', lw=2に変更して、線形回帰の線の色と太さを変更してみました。
まとめ
酒井さんの講座でPythonを学習しているのですが、このあたりまで来ると内容が難しくて、5回以上繰り返して学習しないと内容が理解できなくなります。

オンライン講座のいいところは、何度も復習することができるというところですが、これが1回だけの講義だった場合、復習する時に思い出せなくなったり、間違ったコードを書いているのに気付かなかったりしてしまうリスクがあります。
オンライン講座だと、わからなければ何度も見て理解すればいいので、これほど効率のいい学習スタイルはないんじゃないかと思っています。
今回学習したscikit-learnについては、ほんの少しだけの紹介になりますが、最初のload_bostonが出てきた段階で、そのデータはどこから来てるんだろかという疑問から始まり、公式チュートリアルでload_bostonを見つけてから、ようやく理解が進んだという感じです。
ここまで学習してきたにも関わらず、わからないことが多すぎるPythonですが、大晦日の明日も明後日のお正月も途切れることなくしっかりと学習を継続していきたいと思います。
それでは、明日もGood Python!