Python学習【365日チャレンジ!】362日目のマスターU(@Udemy11)です。
ここに来て、Amazonプライムからの誘惑が強くなってきています。
ちょっと前まではAmazonプライムビデオの魅力的な映画はほとんど見ていたのですが、最近リストが更新されて、見てみたいと思う作品がラインナップされています。
特に、歴史好きには時間をかけても見たくなるような作品である長編中国史の大作で、95話もある【三国志】がプライムに登場しているので、見るのを我慢するのが大変です。
1話40分位あるので、単純に3800分(634時間)、24時間見続けても半月以上かかってしまう計算です。
慌てて見る必要はないので、Python学習365日チャレンジを達成して、少し落ち着いてから、ゆっくり3ヶ月くらいかけて見ようと思っています。
魅力的な作品がたくさんあるので、映画好きな人はぜひAmazonプライムを試してみてください。

それでは、今日もPython学習をはじめましょう。
昨日の復習
昨日は、Google検索の結果からPythonで抽出したURLとタイトルをGoogleスプレッドシートに書き込むためのプログラムを書きました。
一昨日は、鬼滅の刃のせいで、寝不足でさぽってしまったような内容でしたが、昨日はしっかりしたコードを書けたのではないかと思います。
とはいっても、これまでに学習してきたBeautifulSoupを使ったWebスクレイピングとGoogleスプレッドシートの操作を組み合わせただけなので、そんなにハマることろはありませんでした。
詳細については、こちらの記事をごらんください。

今日は、さらにTkinterを使って、入力フォームから【スプレッドシートキー】と【秘密鍵ファイル名】、【検索キーワード】を取得して、検索結果をGoogleスプレッドシートに書き出すプログラムを作成します。
入力フォーム(interface.py)
まず、Tkinterを使った入力フォームのコードですが、以前作成した【スプレッドシートキー】と【秘密鍵ファイル名】、【数値】を入力して、スプレッドシートに入力された数値を元にした計算結果を出力するコードを再利用します。

interface.py
import tkinter as tk
import control
class Application(tk.Frame):
def __init__(self, master=None):
super().__init__(master)
self.master.geometry()
self.master.title('get title and URL')
self.menu_bar = tk.Menu(self.master)
self.master.config(menu=self.menu_bar)
self.entry = tk.Entry(self.master, width=40)
self.entryf = tk.Entry(self.master, width=40)
self.entry2 = tk.Entry(self.master, width=20)
self.lavel = tk.Label(text='シートキー:')
self.lavelf = tk.Label(text='ファイル名:')
self.lavel2 = tk.Label(text='検索ワード:')
self.create_widgets()
def clear_all(self):
self.entry2.delete(0, tk.END)
def search(self):
keys = self.entry.get()
keywords = self.entry2.get()
file_name = self.entryf.get()
control.main(keys, keywords, file_name)
def create_widgets(self):
file_menu = tk.Menu(self.menu_bar)
file_menu.add_command(label='Exit', command=self.master.quit)
self.menu_bar.add_cascade(label='File', menu=file_menu)
self.entry.grid(row=1, column=2, columnspan=6, pady=10, padx=10)
self.entryf.grid(row=2, column=2, columnspan=6, pady=10, padx=10)
self.entry2.grid(row=3, column=2, pady=10)
self.lavel.grid(row=1, column=1)
self.lavelf.grid(row=2, column=1)
self.lavel2.grid(row=3, column=1)
self.entry.focus_set()
tk.Button(self.master, text='Clear', width=4,
command=self.clear_all).grid(row=4, column=6)
tk.Button(self.master, text='抽出', width=4,
command=self.search).grid(row=4, column=7, pady=10)
root = tk.Tk()
app = Application(master=root)
app.mainloop()
変更したのは、ハイライトしている行の引数や値です。
9行目は入力フォームのタイトルをget title and URLに変更しています。
15行目で、テキストボックスの幅を広くして、18行目のラベルの名前を検索ワードに変更。
25行目の関数名をsearchに変更して、検索キーワードを入れるので、keywordsに変更しました。
あとは、46行目、47行目でボタンに表示する文字を抽出にして、クリック時のアクションにsearch()関数を引き当てています。
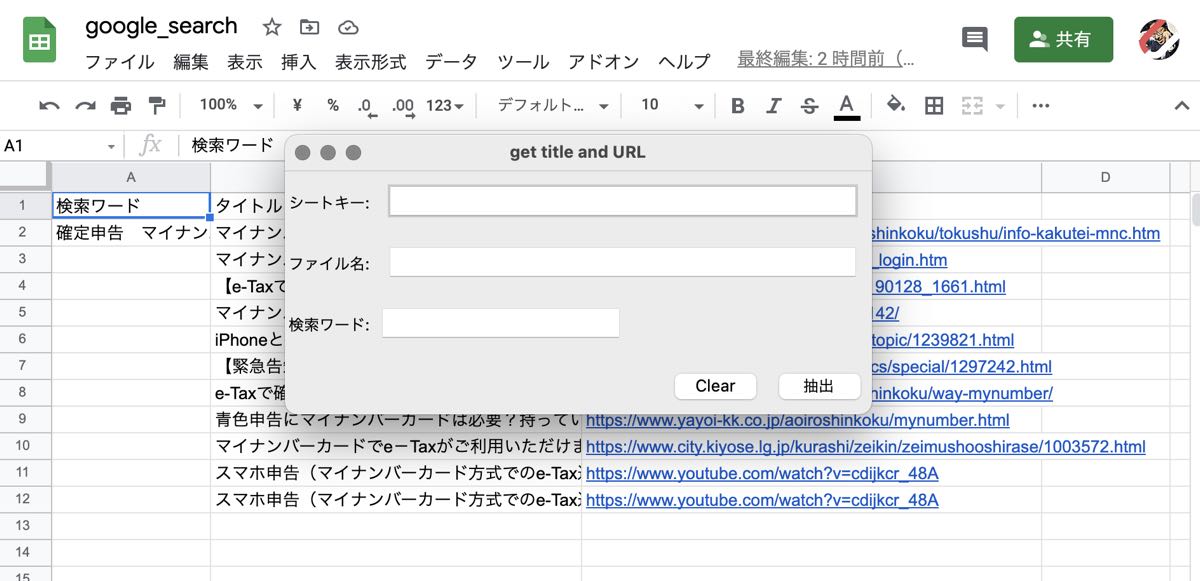
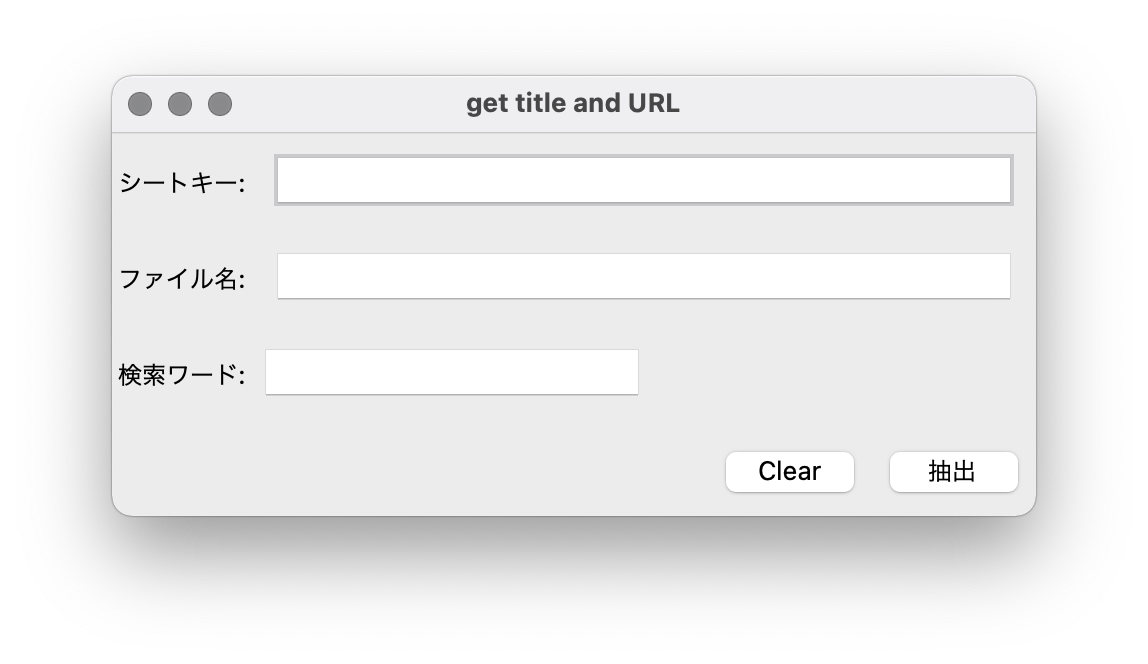
このファイルを実行すると、次のような入力フォームが立ち上がります。
続いて、3行目でインポートしているcontrol.pyのコードを見てみましょう。
実行ファイル(control.py)
control.pyも、入力フォームから取得した【秘密鍵ファイル名】や【スプレッドシートキー】を活用して、スプレッドシートにアクセスするコードや入力フォームから取得した【検索キーワード】を元にGoogle検索からURLとタイトルを取得してリストに保存するコード、スプレッドシートに取得したデータを書き込むコードは、以前作成した下記の記事のコードとほぼ一緒です。
他の部分も含めて全体のコードを見てみましょう。
control.py
import re
import urllib.parse
from bs4 import BeautifulSoup
import gspread
from oauth2client.service_account import ServiceAccountCredentials
import requests
def main(keys, keywords, file_name):
scopes = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name(file_name, scopes)
gc = gspread.authorize(credentials)
worksheet = gc.open_by_key(keys).sheet1
r = requests.get('https://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=' + keywords)
html_soup = BeautifulSoup(r.content, 'html.parser')
url_results = []
for t in html_soup.select('.kCrYT > a'):
u_result = re.sub(r'/url\?q=|&sa.*', '', t.get('href'))
url_results.append(urllib.parse.unquote(u_result))
title_results = []
for i in url_results:
try:
search = requests.get(i)
search_soup = BeautifulSoup(search.content, 'html.parser')
titles = search_soup.find('title')
title_results.append(titles.text)
except:
print('取得できませんでした。')
worksheet.update_cell(2, 1, keywords)
a = 2
for title_v in title_results:
worksheet.update_cell(a, 2, title_v)
a += 1
b = 2
for url_v in url_results:
worksheet.update_cell(b, 3, url_v)
b += 1
if __name__ == '__main__':
main()9行目のmain関数の引数はinterface.pyの変更に合わせて変更し、引数名をそのまま使えるので、引数を代入して定義していた不要な変数の行を削除しました。
10〜13行目が、入力フォームに入力された【秘密鍵ファイル名】と【スプレッドシートキー】を使ってスプレッドシートを操作できる状態にするコードです。
15〜31行目が入力フォームに入力された【検索キーワード】からGoogle検索をして、その結果からタイトルとURLをリストに保存するコードです。
33〜43行目は、【検索キーワード】をA2に入力し、リストに入っているタイトルをB2〜B11に、URLをC2〜C11に入力するコードです。
最後の2行は、このファイルがインポートされたときに関数が実行されないように、いつも記述する定番のコードとなります。
動作確認
interface.pyを実行すると、入力フォームが立ち上がり、【スプレッドシートキー】と【秘密鍵ファイル名】、【検索キーワード】を入力して、【抽出】ボタンをクリックすると、control.pyのmain()関数が実行されて、Googleスプレッドシートに抽出したタイトルとURLが入力されます。
今回も実際の動きを動画にしました。
動画の最後でシークレットモードのChromeを使って検索キーワードで検索した結果と抽出されたタイトルを見比べてみましたが、同じ結果が返されているのがわかるかと思います。
まとめ
これまで実践してきた内容を組み合わせて作ったプログラムなので、比較的スムーズにコードが出来上がりましたが、実は超単純な間違いをして、何がおかしいのか理解するまでに結構時間がかかってしまいました。
間違いに気づいたのは、エラーのコードをきちんと見たからですが、スプレッドシートキーのテキストボックスに秘密鍵ファイル名を入力して、秘密鍵ファイル名のテキストボックスにスプレッドシートキーを入れてしまっていました。
ファイルが見つからないというエラーだったので、エラーをしっかり確認したところ、ファイル名のところに入力したスプレッドシートキーが表示されていたので、この間違いに気づくことができました。
この間違いに気づくまでに、何がおかしいのかわからず、コードを見直していると、main関数で受け取る引数を一旦変数に代入してその変数を使っているコードがあり、引数名をそのまま活用できることに気づき、無駄なコードを削除することができました。
コードを見直すってことは重要ですね。
かなりPythonのコードに慣れてきたものの、まだまだ実践時間が足りないので、時間のあるときはコードを書くように意識しようと思います。
それでは、明日もGood Python!