Python学習【365日チャレンジ!】361日目のマスターU(@Udemy11)です。
最近寒くって運動できないうえ、食べるものがおいしくって、右肩上がりに体重が増えてきてこまっています。
本来なら、気持ちを引き締めて、食べる量を減らして、運動もスタートしたいところなのですが、どうも気持ちがダイエットの方に向かわないんですよね。
そんなときに、今更ですが、オメガ3脂肪酸がたくさん含まれる【しそ油(エゴマ油)】を継続して摂取している人から、血液の値が良くなったとか、同じように摂取している人の乳がんがなくなったという話を聞いて、早速注文して飲んでみることにしました。
こういうものって、1年か2年は継続して飲み続けないと効果は数値に表れてこないので、大概の人は途中で挫折して摂取するのをやめてしまうんですよね。
私の場合、Python学習もそろそろ継続して1年を迎えようとしていて、継続することの大切さがわかるので、【しそ油】も最低1年は続けてみたいと思います。
それでは、今日もPython学習をはじめましょう。
昨日の復習
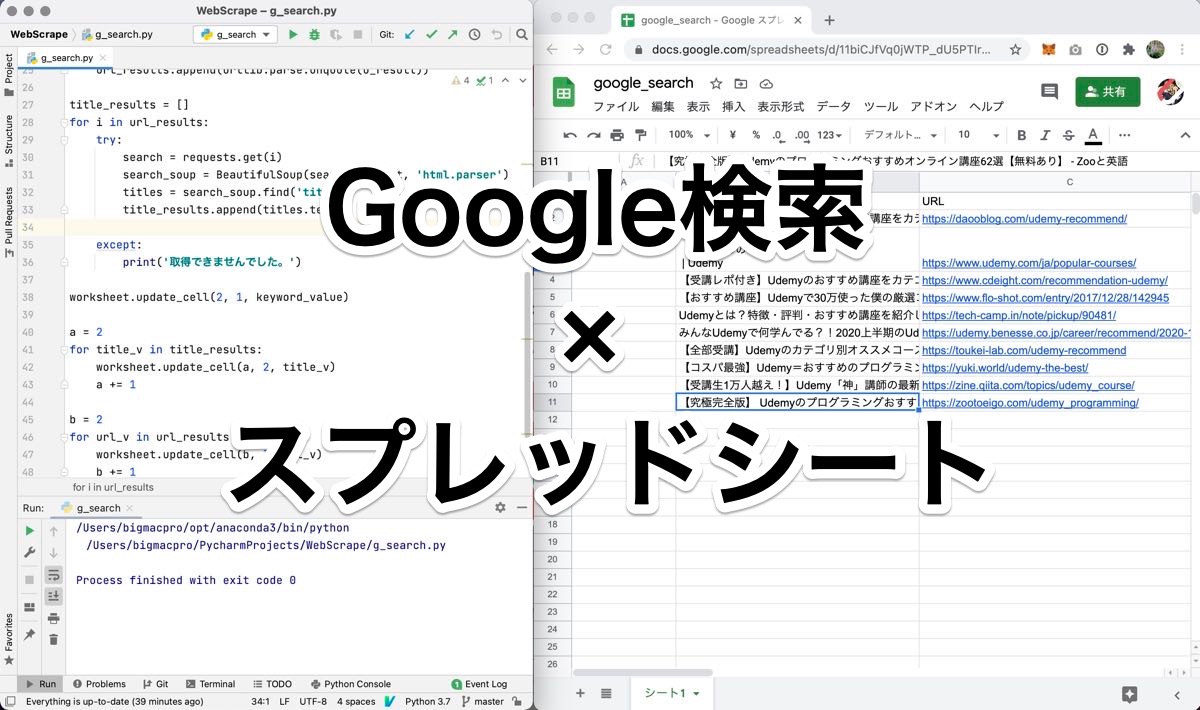
昨日は、Google検索の結果からPythonで抽出したURLとタイトルをGoogleスプレッドシートに書き込むためのスプレッドシートを作成しました。
鬼滅の刃のせいで?!、かなりサボってしまった内容になってしまいましたが、スプレッドシートを作成して、検索するキーワードと抜き出したタイトル、URLを記録するための見出しを作っただけでしたね。
ある意味、見る必要もないかもしれませんが、昨日の内容は、こちらの記事をごらんください。

今日は、Google検索の結果からPythonで抽出したURLとタイトルをGoogleスプレッドシートに書き込むためのコードを書いていきます。
g_search.py
今回のファイル名はg_search.pyにしました。
の内容としては、Googleスプレッドシートを操作するための設定をして、Google検索からデータを取得し、最後にスプレッドシートに取得したデータを書き込むコードになっています。
import re
import urllib.parse
from bs4 import BeautifulSoup
import gspread
from oauth2client.service_account import ServiceAccountCredentials
import requests
file_name = 'secret_gcp.json'
scopes = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name(file_name, scopes)
gc = gspread.authorize(credentials)
SHEET_KEY = '11biCkfVq0jgTp_dU5PTIrv6CtoeoKcpV4ssk-7Bv95g'
worksheet = gc.open_by_key(SHEET_KEY).sheet1
keyword_value = 'udemy おすすめ講座'
r = requests.get('https://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=' + keyword_value)
html_soup = BeautifulSoup(r.content, 'html.parser')
url_results = []
for t in html_soup.select('.kCrYT > a'):
u_result = re.sub(r'/url\?q=|&sa.*', '', t.get('href'))
url_results.append(urllib.parse.unquote(u_result))
title_results = []
for i in url_results:
try:
search = requests.get(i)
search_soup = BeautifulSoup(search.content, 'html.parser')
titles = search_soup.find('title')
title_results.append(titles.text)
except:
print('取得できませんでした。')
worksheet.update_cell(2, 1, keyword_value)
a = 2
for title_v in title_results:
worksheet.update_cell(a, 2, title_v)
a += 1
b = 2
for url_v in url_results:
worksheet.update_cell(b, 3, url_v)
b += 1Google検索の結果をCSVに書き出すプログラムと同じなので、ソースをそのまま活用して、さらにGoogleスプレッドシートを操作するコードを付け足してforループで順番にセルに書き出しています。
それぞれのパーツをチェックしてみましょう。
インポートするライブラリ
import re
import urllib.parse
from bs4 import BeautifulSoup
import gspread
from oauth2client.service_account import ServiceAccountCredentials
import requestsインポートするライブラリは、re、urllib、BeautifulSoup、gspread、oauth2client、requestsです。
まだインストールしていない場合は、ターミナルからpipインストールしておきます。
秘密鍵ファイルとスプレッドシートキーを設定
file_name = 'secret_gcp.json'
scopes = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name(file_name, scopes)
gc = gspread.authorize(credentials)
SHEET_KEY = '11biCkfVq0jgTp_dU5PTIrv6CtoeoKcpV4ssk-7Bv95g'
worksheet = gc.open_by_key(SHEET_KEY).sheet1Google Cloud Platformからダウンロードしたファイル名が9行目のsecret_gcp.jsonです。
このファイルは、このコードのPythonファイルと同じ階層に保存しておきます。
11行目から15行目で、秘密鍵ファイルを使ってスプレッドシートにアクセスしていますが、詳しくは、こちらの記事を復習してみてください。

Google検索の結果を取得
keyword_value = 'udemy おすすめ講座'
r = requests.get('https://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=' + keyword_value)
html_soup = BeautifulSoup(r.content, 'html.parser')
url_results = []
for t in html_soup.select('.kCrYT > a'):
u_result = re.sub(r'/url\?q=|&sa.*', '', t.get('href'))
url_results.append(urllib.parse.unquote(u_result))
title_results = []
for i in url_results:
try:
search = requests.get(i)
search_soup = BeautifulSoup(search.content, 'html.parser')
titles = search_soup.find('title')
title_results.append(titles.text)
except:
print('取得できませんでした。')17行目から35行目までがGoogle検索の結果からタイトルとURLを抽出するコードになります。
17行目で検索するキーワードを入力しています。
19行目、20行目で検索結果を解析できるオブジェクトにして、22〜25行目でURLをリストurl_resultsに抽出し、27〜35行目でタイトルをリストtitle_resultsに抽出しています。
スプレッドシートに書き出し
worksheet.update_cell(2, 1, keyword_value)
a = 2
for title_v in title_results:
worksheet.update_cell(a, 2, title_v)
a += 1
b = 2
for url_v in url_results:
worksheet.update_cell(b, 3, url_v)
b += 1最後のパーツは、スプレッドシートに書き出すコードです。
37行目で検索するキーワードをセルA2に入力しています。
39〜42行目で、タイトルをB2〜B11に入力し、44〜47行目でURLをC2〜C11に入力しています。
動作を確認
今回も動作確認の動画を作ってみました。
ちょっと時間がかかりますが、きちんと【検索キーワード】、【タイトル】、【URL】が抽出されているのがわかるかと思います。
まとめ
今回もコードを書きつつ、エラーを起こしながら修正して無事きちんと目的のデータを書き出すことができました。
コードは以前うまく動いたものを再利用しているので、当たり前といえば当たり前なのですが、新しく付け加えた最後のパーツで、セルの列を指定する変数aとbをforループの中で定義してしまい、ずっとB2やC2の値を更新するというミスをしちゃっています。
ミスをしながら、どこが間違っているのかチェックしつつ、最終的にはうまくデータを抽出してスプレッドシートに書き出すことができたときは、やっぱり気持ちがいいんですよね。
うまく動いたときの顔を鏡で見ると、きっとにやけていると思いますよ〜。
それでは、明日もGood Python!