Python学習【365日チャレンジ!】284日目のマスターU(@Udemy11)です。
今シーズンからイカを釣るエギングのエギは、餌木猿スーパーシャローを使っているのですが、釣具屋さんではほぼ売り切れ状態で、メルカリなどで、通常販売より高い値段で手に入れるしかない状態です。
通常のエギは1,000円しないものがほとんどなのですが、餌木猿は税込みでだいたい1,400円ほどするので、根がかりでロストしたときのショックは計り知れません。
また、エギをロストしてしまうと環境にも良くないので、根がかり対策や根がかりしたときの外し方動画を見て、できるだけロストしないように意識しているのですが、それでもやはり根がかりした時に外れずにロストしてしまうことがあります。
いつぞやのニュースで、明石の漁協が2ヶ月で1万6千個ものエギを回収したということが問題になっていましたが、なるべくエギをロストしないエギングは、自分の財布だけでなく地球環境にも優しいので、エギをロストしないよう、意識してエギングを楽しもうと思います。

それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、正規表現を扱うre(RegularExpressions)を学習しました。
正規表現は、指定した条件に一致する複数の文字列を一つの形式でで表現する方法でした。
その正規表現に関する処理を実行できるのがreライブラリでした。
詳細については昨日の記事をごらんください。

今日は、match()、search()、findall()、finditer()を学習します。
match()
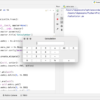
まずはmatch()ですが、文字列の先頭で指定した正規表示とマッチするか調べてヒットした場合は、マッチオブジェクトを返してくれます。
import re
m = re.match('a.c', 'ayc')
print(m)出力結果
<re.Match object; span=(0, 3), match='ayc'>3行目のre.match('a.c', 'ayc')は、aから始まって、.(任意の位置文字)が入って、cで終わる文字列が、第2引数の文字列にマッチするかどうかを判断しています。
第2引数はaycで条件に合うため、インデックスが0から3でaycがヒットしたというマッチオブジェクトが出力されています。
マッチオブジェクトの中身を取得するにはgroup()メソッドを使います。
print(m.group())出力結果
ayc第2引数をaにしたり、aaacにすると、正規表現の条件に合う文字列がないので、結果はNoneが出力されます。
import re
m = re.match('a.c', 'a')
print(m)
m = re.match('a.c', 'aaac')
print(m)出力結果
None
Nonesearch()
search()は、文字列のどの部分に指定した正規表現がマッチするか調べることができます。
import re
m = re.search('a.c', 'text abc test')
print(m)出力結果
<re.Match object; span=(5, 8), match='abc'>第2引数のtext abc testの中には、正規表現のa.cにマッチする部分があるので、結果はインデックスが5から8の間のabcがヒットしたことを示すマッチオブジェクトが出力されています。
match()と同じように、group()メソッドを使えば中身のabcを抽出することができます。
findall()
serch()の場合は、条件に合う文字列が複数あった場合でも、最初にマッチした文字列を見つけた時点でその値を取得します。
一方でfindall()は、正規表現の条件にマッチする文字列をすべて見つけてリストにして返してくれます。
なので、正規表現の条件にあうものをすべて抽出する場合は、findall()を使用します。
import re
m = re.findall('a.c', 'text abc test aac')
print(m)出力結果
['abc', 'aac']第2引数のtext abc test aacの中には、第1引数の正規表現にマッチする文字列が2つあるので、リストにしてその値を返しています。
finditer()
finditer()は、第1引数の正規表現にマッチする値をイテラブルオブジェクトにして返してくれます。
import re
m = re.finditer('a.c', 'text abc test aac')
print(m)出力結果
<callable_iterator object at 0x7f4ee239ee50>イテラブルオブジェクトなので、中身を見るにはgroup()メソッドを使ってリスト内包表記でリストに表示することができます。
print([w.group() for w in m])出力結果
['abc', 'aac']まとめ
正規表現に関するメソッドははいろいろなものがあるので、今回学習したメソッドだけではありませんが、使用頻度が高い一例として今回挙げた4つがあります。
過去に学習したリストリスト内包表記なども使いながら学習しましたが、過去に学習したものをきちんと復習することは大切なので、すでに忘れかけている人はこちらの記事で復習してみてください。

それでは、明日もGood Python!