Python学習【365日チャレンジ!】285日目のマスターU(@Udemy11)です。
今年もブラックフライデーに合わせたUdemyのブラックフライデーセールが始まっています。
普段から時折実施されるセールでもお得にUdemyの講座を購入できますが、ブラックフライデーセールは特別です。
酒井さんの講座を受講しながらPython学習365日チャレンジを継続しているのですが、私も具体的な実践に役立ちそうなPython講座をいくつか購入しておきました。
Udemyの講座は受講期限がないので、セールの時に魅力的な講座を購入しておいて、後からゆっくりと受講することが可能です。、
私の場合、酒井さんの講座を受講し終えてから、購入した講座を受講しようと思っています。
ぜひ、この機会にUdemyの講座でスキルアップを目指してください。
それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、reライブラリのmatch()、search()、findall()、finditer()を学習しました。
match()、search()は、正規表記にマッチする文字列を取得することができました。
findall()はマッチするすべての文字列をリストにして返してくれ、finditer()はマッチする複数の文字列をイテラブルオブジェクトとして取得することができました。
詳しくは、昨日の記事を参照してください。

今日は、match()を使って、正規表現の基本的な記述について学習します。
?
?は、直前文字の繰り返しが0回か1回の文字列がマッチします。
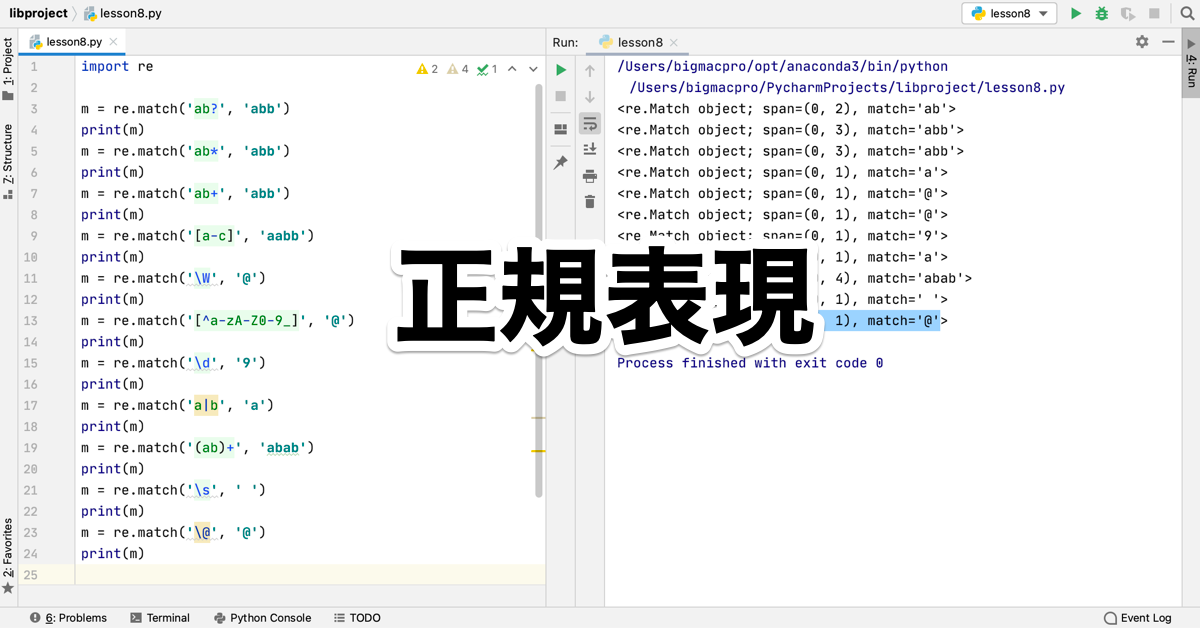
import re
m = re.match('ab?', 'abb')
print(m)出力結果
<re.Match object; span=(0, 2), match='ab'>直前の文字つまりbがaに続いて0回もしくは1回繰り返されている文字列なので、マッチしている部分は、abになります。
aだけでもマッチしますが、後ろに何を付け足してもマッチしている文字列はabだけがマッチしています。
*
*は、直前の文字が0回以上繰り返されているという意味になります。
m = re.match('ab*', 'abb')
print(m)出力結果
<re.Match object; span=(0, 3), match='abb'>コードはimport reを含めた最初の2行を省略しています。
bはなんど繰り返してもマッチするので、出力結果はabbとなっています。
また、aのみでもbが0回なのでマッチします。
+
+は直前の文字が1回以上繰り返されているという意味です。
m = re.match('ab+', 'abb')
print(m)出力結果
<re.Match object; span=(0, 3), match='abb'>+は、直前の文字bが1回以上繰り返されている場合にマッチするので、abbがマッチしますが、第2引数をaにするとマッチしません。
{,}
{}は、直前の文字の繰り返し回数を指定して検索することができます。
m = re.match('a{2,4}', 'aabb')
print(m)出力結果
<re.Match object; span=(0, 2), match='aa'>{}の直前の文字はaで、{2,4}で、2回から4回を指定しています。
マッチする部分は、aaとなります。
aが1つしかない場合はマッチしませんので、Noneが返されます。
[-]
[-]は、マッチするアルファベットや数字の範囲を指定します。
m = re.match('[a-c]', 'aabb')
print(m)出力結果
<re.Match object; span=(0, 1), match='a'>-でつなげることで、指定したアルファベットの範囲内の文字がマッチします。
数字を指定する場合も-でつなげます。
大文字と小文字は区別されるので、大文字小文字のアルファベットと数字を指定する場合は、[a-zA-Z0-9]と記述します。
\w \W
\wは、上記で学習した[a-zA-Z0-9]に加えて_(アンダースコア)を加えた文字を意味する[a-zA-Z0-9_]と同じ意味になります。
m = re.match('\w', '_')
print(m)出力結果
<re.Match object; span=(0, 1), match='_'>大文字小文字英数字と_がマッチしますが、@などの記号を入れるとマッチせずにNoneが返されます。
\Wは、[a-zA-Z0-9_]以外の文字がマッチし、[^a-zA-Z0-9_]と記述することもできます。
m = re.match('\W', '@')
print(m)出力結果
<re.Match object; span=(0, 1), match='@'>\wは、使用頻度が高いので、覚えておきたい正規表現ですが、wとWでは意味が違うので、注意しましょう。
\d \D
\dは、数字のみを指定する正規表現です。
m = re.match('\d', '9')
print(m)出力結果
<re.Match object; span=(0, 1), match='9'>数字のみなので、9がマッチしています。
感のいい方ならすでにおわかりかと思いますが、\Dは、数字以外を指定する正規表現です。
m = re.match('\D', 'a')
print(m)出力結果
<re.Match object; span=(0, 1), match='a'>今度は数字以外なので、aがマッチしますし、@などの記号も含まれます。
|
|(パイプ)は、前後の文字を指定する正規表現です。
m = re.match('a|b', 'a')
print(m)出力結果
<re.Match object; span=(0, 1), match='a'>aかbなので、aがマッチしますが、他の文字や数字が入っているとNoneが返されます。
()+
()+を使って文字の塊の繰り返しを指定することもできます。
m = re.match('(ab)+', 'abab')
print(m)出力結果
<re.Match object; span=(0, 4), match='abab'>abの1回以上の繰り返しになるので、ababがマッチしています。
\s \S
\sは、スペースのみがマッチする正規表現です。
m = re.match('\s', ' ')
print(m)出力結果
<re.Match object; span=(0, 1), match=' '>スペースがマッチしているのがわかります。
この正規表現にも当然大文字が存在しますが、お察しのとおり\Sは、スペース以外の文字となり、スペース以外の文字がマッチします。
m = re.match('\S', 'a')
print(m)出力結果
<re.Match object; span=(0, 1), match='a'>\
最後に、re.match()の正規表現で使用する*などの記号を文字列から見つけるには、\を使います。
m = re.match('\@', '@')
print(m)出力結果
<re.Match object; span=(0, 1), match='@'>\@とすることで、第2引数の文字列から@を見つけることができます。
まとめ
正規表現について、いろいろと学習しましたが、これらの表記を組み合わせて使用したり、他の正規表記もありますので、正規表記をコンプリートしたい場合は、Pythonの公式ドキュメントを参考にしてみてください。
最初は、いろいろとありすぎて、どれがどうだったか頭がこんがらがってしまうと思いますので、実際に実践しながら、少しずつ覚えていきましょう!
それでは、明日もGood Python!