Python学習【365日チャレンジ!】286日目のマスターU(@Udemy11)です。
MacのOSをアップデートしたらセキュリティーソフトのE-SETが未対応だったので、あたふたしています。
OSの大きなアップデートの際は、インストールしているソフトがOSに対応しているかどうかを確認する必要があるので、注意しないとと思っているにも関わらず、ついついアップデートしてしまうんですよね。
毎回失敗しているので、次は注意しようと思うのですが、全く学習していないようです。
とりあえず、Pycharmは使えるので一安心。
Python学習には支障がないので、今日もPython学習を始めましょう。
昨日の復習
昨日は、match()を使って、正規表現の基本的な記述方法を学習しました。
?や*や+といった正規表現で、直前の文字の繰り返し回数を指定してマッチする文字列を抽出しました。
{}や[]を使って範囲を指定したり、抽出する種類を指定したりすることもできました。
その他の基本的な正規表現については、昨日の記事をごらんください。

今日は、match()とgroup()を使って、規則のある長い文字列から必要な情報を取り出す方法を学習します。
AWSCloudFormation
AWSCloudFormationじゃなくてもいいのですが、酒井さんの講座で使われていたので、他の適切な文字列をどのように見つけていいかわからなかったため、講座と同じようにAWSCloudFormationの文字列を活用してみました。
こちらのページの中ほどにある【StackIdarn:aws:cloudformation:us-east-2:123456789012:stack/mystack-mynestedstack-sggfrhxhum7w/f449b250-b969-11e0-a185-5081d0136786】を活用します。

matchとgroup
上記のStackIdの文字列がcloudformationのフォーマットになっているかどうかを確認するコードを書いていきます。
import re
s = ('arn:aws:cloudformation:'
'us-east-2:123456789012:stack/'
'mystack-mynestedstack-sggfrhxhum7w/'
'f449b250-b969-11e0-a185-5081d0136786')
m = re.match(r'arn:aws:cloudformation:[\w-]+:[\d]+:stack/[\w-]+/[\w-]+', s)
print(m)
print(m.group())sにAWSから取得した文字列を代入して、8行目のre.matchで、StackIdのフォーマットにマッチした正規表現で文字列を抽出し、9行目でマッチオブジェクト、10行目で抽出した文字列を出力しています。
出力結果
<re.Match object; span=(0, 123), match='arn:aws:cloudformation:us-east-2:123456789012:sta>
arn:aws:cloudformation:us-east-2:123456789012:stack/mystack-mynestedstack-sggfrhxhum7w/f449b250-b969-11e0-a185-5081d01367861行目の出力はマッチオブジェクト、2行目はsに代入したStackIdがそのまま出力されています。
group name
正規表現を使って抽出する部分に名前を指定して、指定した名前で値を取得することもできます。
m = re.match(r'arn:aws:cloudformation:(?P<region>[\w-]+):(?P<account_id>[\d]+):stack/(?P<stack_id>[\w-]+)/[\w-]+', s)
print(m.group('region'))
print(m.group('account_id'))
print(m.group('stack_id'))出力結果
us-east-2
123456789012
mystack-mynestedstack-sggfrhxhum7w正規表現で指定している部分を(?P<name>正規表現の部分)とすることで、group('name')で取り出すことができるようになります。
出力結果は順番に指定したregion、account_id、stack_idが出力されていますが、こちらはユーザーによって値が変わってきます。
条件分岐を使う
具体的な使い方の一例は、データベースからStackIdのフォーマットを取得して、if分での条件分岐を使い、データベースの値がマッチすれば、次の処理に進み、マッチしていない場合はエクセプションでエラーを表示するという使い方ができます。
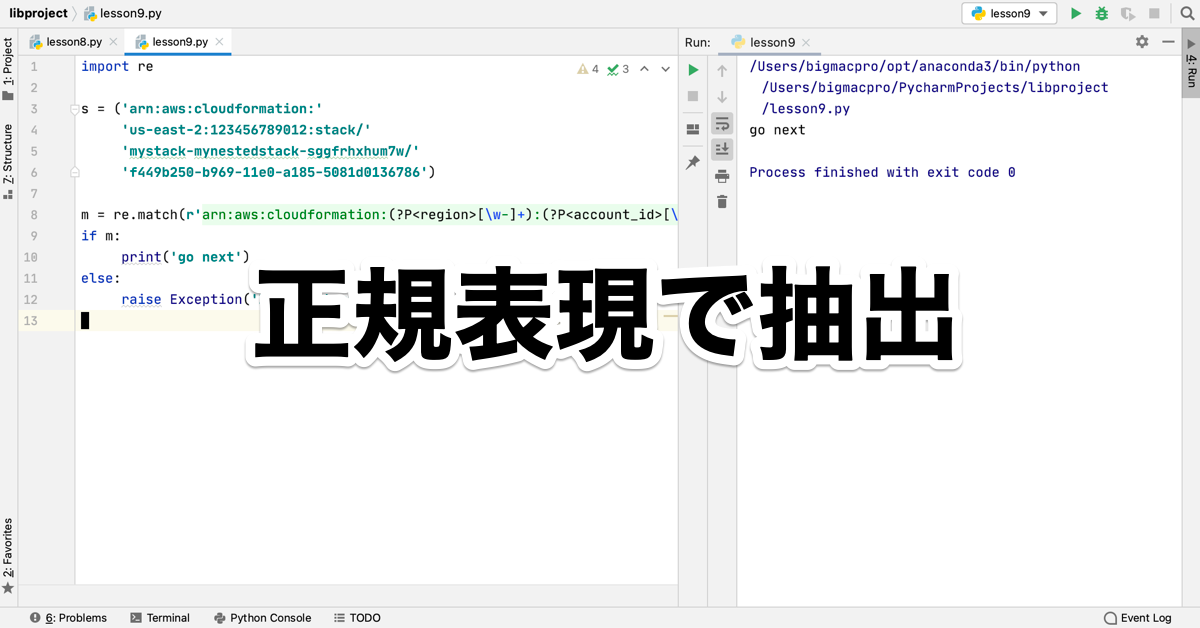
m = re.match(r'arn:aws:cloudformation:(?P<region>[\w-]+):(?P<account_id>[\d]+):stack/(?P<stack_id>[\w-]+)/[\w-]+', s)
if m:
print('go next')
else:
raise Exception('ID is not match.')出力結果
go next8行目の正規表現がきちんとフォーマットどおりなので、mがTrueとなって、go nextが出力されています。
最初のsの変更がなく統一された値が間違っていたり、正規表現が間違っていたりすると、エラーが発生して、ID is not matchが出力されます。
まとめ
わかりやすく説明するために、固定された文字列を使ったり、かんたんなprint出力を使ったりしていますが、実際に使う場面は、データベースに保存されているデータと入力されたデータを正規表現で比較してなにかの処理をさせたり、マッチしなければエラーを起こさせたりする使い方があるのかなと思います。
いつも感じるのですが、全く知識がない状態で学習したことは、そのまま実践で使われるのかと思っちゃいますが、あくまでかんたんにそれぞれの機能を説明するために紹介されているだけですので、実践は今回学習したような使い方はないのかもしれません。
とはいえ、基本を抑えておくことは大変重要なので、これからも頑張って継続していきたいと思います。
ということで、明日もGood Python!