Python学習【365日チャレンジ!】288日目のマスターU(@Udemy11)です。
楽天市場のブラックフライデーセールで散財したお話をしましたが、11月27日(金)からは、AmazonのBigSaleブラックフライデー&サイバーマンデーセールが開始しますので、金欠をすっ飛ばして、財布の中身がすっからかんになってしまいそうです。
今どき財布にお金は入ってないんですけどね〜(笑)

ネットだとカードで何でも買えちゃうので、使いすぎに注意が必要ですが、とりあえず、欲しいものはお気に入りに登録しておいたほうがいいですね。
それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、re.compileとre.VERBOSEを使って、正規表現による抽出をよりシンプルでわかりやすく記述する方法を習しました。
何度も同じ正規表現を使って検索する場合は、re.compileを使ってグローバル変数にしておけば、あとから便利に活用することができました。
また、re.VERBOSEを使えば、コンパイルする正規表現のコードをよりわかりやすく記述することができました。
詳細は昨日の記事をごらんください。

今日は、compileとsplitを使って、文字列を分割する方法を学習します。
splitの復習
splitは、下記のリストのメソッドで学習しました。

split()は、デフォルト引数でsep=' 'が入っているので、半角スペースで文字列を切り分けてリストにしてくれるメソッドでした。
s = 'My name is Mike'
print(s.split())出力結果
['My', 'name', 'is', 'Mike']デフォルト引数が半角スペースですが、split(sep=',')と記述すれば、,で切り分けることもできます。
compile + split
単一記号やスペースで分割するならsplitだけで問題ありませんが、My name is () Mikeという文字列の中からアルファベットだけを抜き出そうとすると、splitだと()も一緒に抽出してしまいます。
そんな時は、正規表現を使ってcompileとsplitを組み合わせて使えばアルファベットだけを抜き出すことができます。
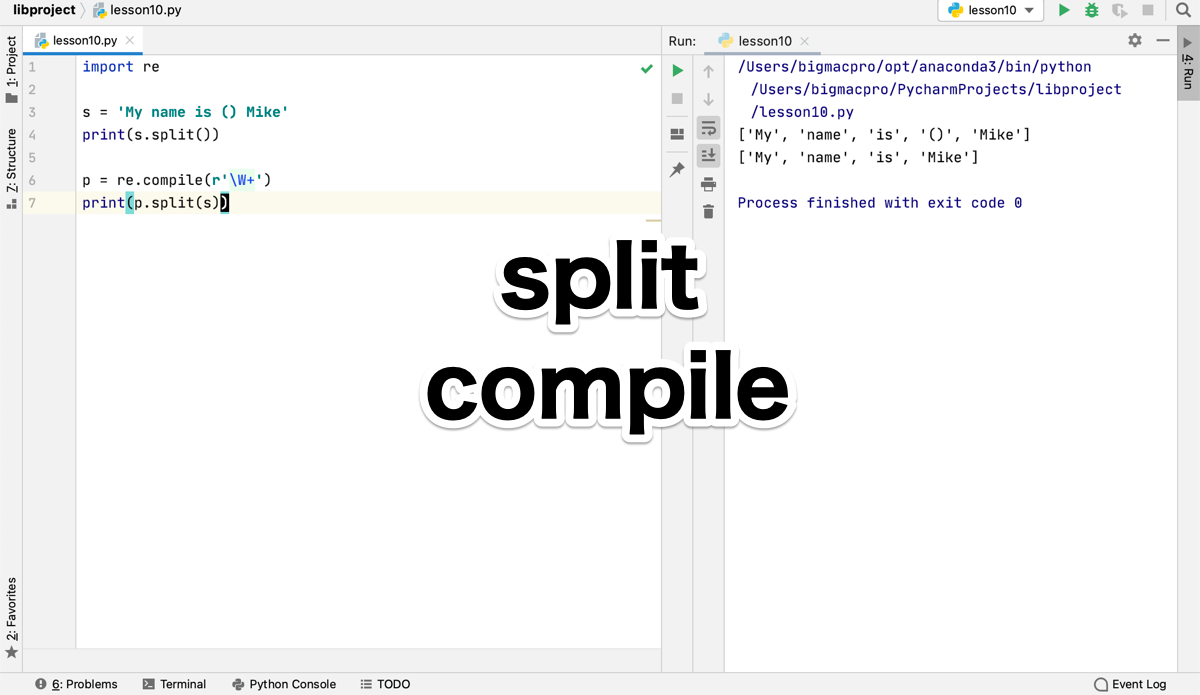
import re
s = 'My name is () Mike'
print(s.split())
p = re.compile(r'\W+')
print(p.split(s))出力結果
['My', 'name', 'is', '()', 'Mike']
['My', 'name', 'is', 'Mike']4行目の出力はデフォルトのsplitなので、()がリストに入ってしまっていますが、7行目の出力はcompileと組み合わせてsplitを使っているので、アルファベットだけが抽出されています。
6行目のre.compile(r'\W+')は、半角英数字とアンダースコア以外の文字の1回以上の繰り返しの文字を指定しているので、7行目のp.split(s)は、指定した文字オブジェクトpで変数sを分割することになり、アルファベットだけが抽出されます。
まとめ
splitは、デフォルトで半角スペースで分割してくれるので、英語の文章を単語に分ける際は非常に便利です。
単一の記号で分割する場合もsplitの引数sepを指定すればできますが、分割したい基準に複数の記号が入っている場合などは、正規表現を使って、re.compileで分割する文字を指定することができます。
正規表現を使えば、考え方次第でいろいろな抽出条件を指定することができるので、デフォルトのメソッドなども拡張した使い方ができます。
このあたりの使い方は、プログラマーの頭の柔らかさが試されるところなので、実践で身につけていくしかありません。
どんどんコードを書いて、経験値を積み上げていきましょう。
それでは、明日もGood Python!