Python学習【365日チャレンジ!】222日目のマスターU(@Udemy11)です。
やっぱ数字が揃うと嬉しくなりますね。
といっても今回は、222なので、確変じゃないところが残念ですが、とりあえずニッコリしてしまいます。
「きりのいいところで」
という言葉がありますが、10とか50とか100だと思うので人によって、今回の数字である【222】もキリのいい数字になるのかもしれません。
まー、私にとっては、111も222もきりのいい数字には違いありません。
それでは、今日もPython学習をはじめましょう。
昨日の復習
昨日は、プールを使って処理をブロックする方法を学習しました。
apply_asyncはPoolを使って並列非同期処理ができましたが、applyは、処理をブロックして、プロセスが終了してから次のコードを処理することができました。
詳細については、昨日の記事をごらんください。

今日は、コードの短縮化ができるmapについて学習します。
map
applyを使って次の処理をブロックしましたが、並列処理をしようと思えば、apply.asyncを使う必要が出てきます。
apply.asyncを使って並列処理をする場合は、非同期処理になるので、続けてなにか処理をするコードがあれば、先に処理が実行されます。
この2つの処理をまとめたような並列処理するプロセスをブロックして次のコードを後回しにできるのが、mapです。
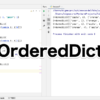
import logging
import multiprocessing
import time
logging.basicConfig(
level=logging.DEBUG, format='%(processName)s: %(message)s'
)
def worker1(i):
logging.debug('start')
time.sleep(5)
logging.debug('end')
return i
if __name__ == '__main__':
with multiprocessing.Pool(3) as p:
r = p.map(worker1,[100, 200, 300])
logging.debug('executed')
logging.debug(r)14行目までは昨日と同じです。
17行目のp.mapで、ターゲットとなる関数をworker1にして、リストに[100, 200, 300]と指定することで、それぞれリストの値を入れた並列処理のプロセスを作ることができます。
次の行のexecutedは、並列処理が終了してから出力され、最後にmapで作られたプロセスの返り値がリストで出力されます。
実行結果
ForkPoolWorker-1: start
ForkPoolWorker-2: start
ForkPoolWorker-3: start #次のコードの出力に5秒まつ
ForkPoolWorker-3: end
ForkPoolWorker-1: end
ForkPoolWorker-2: end
MainProcess: executed
MainProcess: [100, 200, 300]3つのプロセスが並列処理されてから、18行目以降が出力されます。
似たような処理
並列処理だけをするのなら、マルチプロセス(multiprocess.Process)を使えばできますが、似たような処理でも少しちがう処理ができるのがPoolとmapです。
ファジーな人間からすると、「適当にやっといて」というような感じですが、そこはわれわれ人間ではなく、きちっと最初から最後まで指示をしないとできないのがプログラムですので、似たような処理でもコードがちがうわけです。
Pythonはきちんとコードスタイルのルールが決まっていますが、求める結果が決まっていても、プログラマーによって全く違ったコードになります。
答えは一つじゃないところが、楽しいところであり、難しいところでもあるわけですね。
それでは、明日もGood Python!