Python学習【365日チャレンジ!】226日目のマスターU(@Udemy11)です。
釣りの出だしばかりで申し訳ないのですが、昨日はほんとびっくりすることがありました。
例のごとく、早朝からタチウオを釣りに行っていたのですが、全く釣れなくて日が昇ってきたころ、なにげに飛んでいるトンビがいるな〜と思っていたら、その足からなにかキラキラ光る長いものがぶら下がっていました。
気になって、目を凝らして見てみると、なんとタチウオではありませんか!
釣りをしていたので、残念ながら写真は撮れなかったのですが、トンビがタチウオを捕まえているなんてなかなか衝撃的なシーンでした。
それでは、今日もPython学習をはじめましょう。
昨日の復習
昨日は、対になった親子プロセスでデータの入出力ができるパイプ(Pipe)について学習しました。
Pipeを使って、対になったプロセスを作成して親子でデータの入力、出力をすることができました。
親がなにかの処理をして、子がその値を受け取るという単純な処理ですが、Pipeはコマンドラインでも使うので、よく見るコードだということでした。
詳細については、昨日の記事をごらんください。

今日は、プロセス間でメモリを共有する方法を学習します。
プロセスセーフ
プロセスセーフは、スレッドセーフと同じ意味で、これらのことを考えてプログラムを書く必要があるのですが、スレッドセーフ、プロセスセーフと言う言葉がなんとなくわかるものの、きちんと理解できていなかったので、ネットで調べてみました。
スレッドセーフ・プロセスセーフ
あるコードがスレッドセーフであるという場合、そのコードを複数のスレッドが同時並行的に実行しても問題が発生しないことを意味する。特に、ある共有データへの複数のスレッドによるアクセスがあるとき、一度に1つのスレッドのみがその共有データにアクセスするようにして安全性を確保しなければならない。
スレッドセーフはマルチスレッドプログラミングにおける重要な要素である。
引用元: Witipedia
プロセスセーフで検索しても結果がヒットしなかったので、スレッドセーフの説明となっていますが、スレッドがメモリを共有するのに対してプロセスは独立したメモリを使うので、あまり使われていないから情報がないのかなと思いました。
プロセスセーフもスレッドセーフと同じように、並列処理において、複数のプロセスが同じデータに同時アクセスしてクラッシュしないようにする必要がありますが、基本プロセスはメモリが別々なので、プロセス間で同時アクセスの心配はありません。
とはいえ、プロセス間でデータを共有することはありますので、プロセスセーフで共有メモリを使えるValueとArrayを学習します。
Value・Array
まずは、プロセス一つでValueとArrayを使ったコードを書いてみます。
import logging
import multiprocessing
logging.basicConfig(
level=logging.DEBUG, format='%(processName)s: %(message)s'
)
def func(num, arr):
logging.debug(num)
num.value += 1.0
logging.debug(arr)
for i in range(len(arr)):
arr[i] *= 2
if __name__ == '__main__':
num = multiprocessing.Value('f', 0.0)
arr = multiprocessing.Array('i', [1, 2, 3, 4, 5])
p1 = multiprocessing.Process(target=func, args=(num, arr))
p1.start()
p1.join()
logging.debug(num.value)
logging.debug(arr[:])16行目と17行目でValueを使ったnumオブジェクトとArrayを使ったarrオブジェクトを作成しています。
引数の'f'は、浮遊小数点を指定するときに使い、'i'は、整数を指定するときに使います。
19行目で8行目の関数funcをターゲットにして、引数にnumとarrを指定したプロセスを作成して次の行でプロセスを走らせています。
関数funcは、numオブジェクトを出力して、numのvalueに1.0を足して、arrオブジェクトを出力して、arrのリストの値をそれぞれ2倍する処理を行います。
21行目のp1.join()でプロセスが終了するのを待ってから、num.valueとarrのリストを出力しています。
出力結果
Process-1: <Synchronized wrapper for c_float(0.0)6gt;
Process-1: <SynchronizedArray wrapper for <multiprocessing.sharedctypes.c_int_Array_5 object at 0x7f9fce8eaf80gt;gt;
MainProcess: 1.0
MainProcess: [2, 4, 6, 8, 10]numは、Synchronized wrapperというCと互換性のある浮遊小数点型オブジェクト(c_float)で、同じようにarrは、SynchronizedArray wrapperというCと互換性のある整数型の配列オブジェクト(c_int_Arrayになっているのがわかります。
あとの2行は、メインプロセスの出力で、numのvalueである1.0とarrのリストの値が出力されています。
プロセスを並列処理
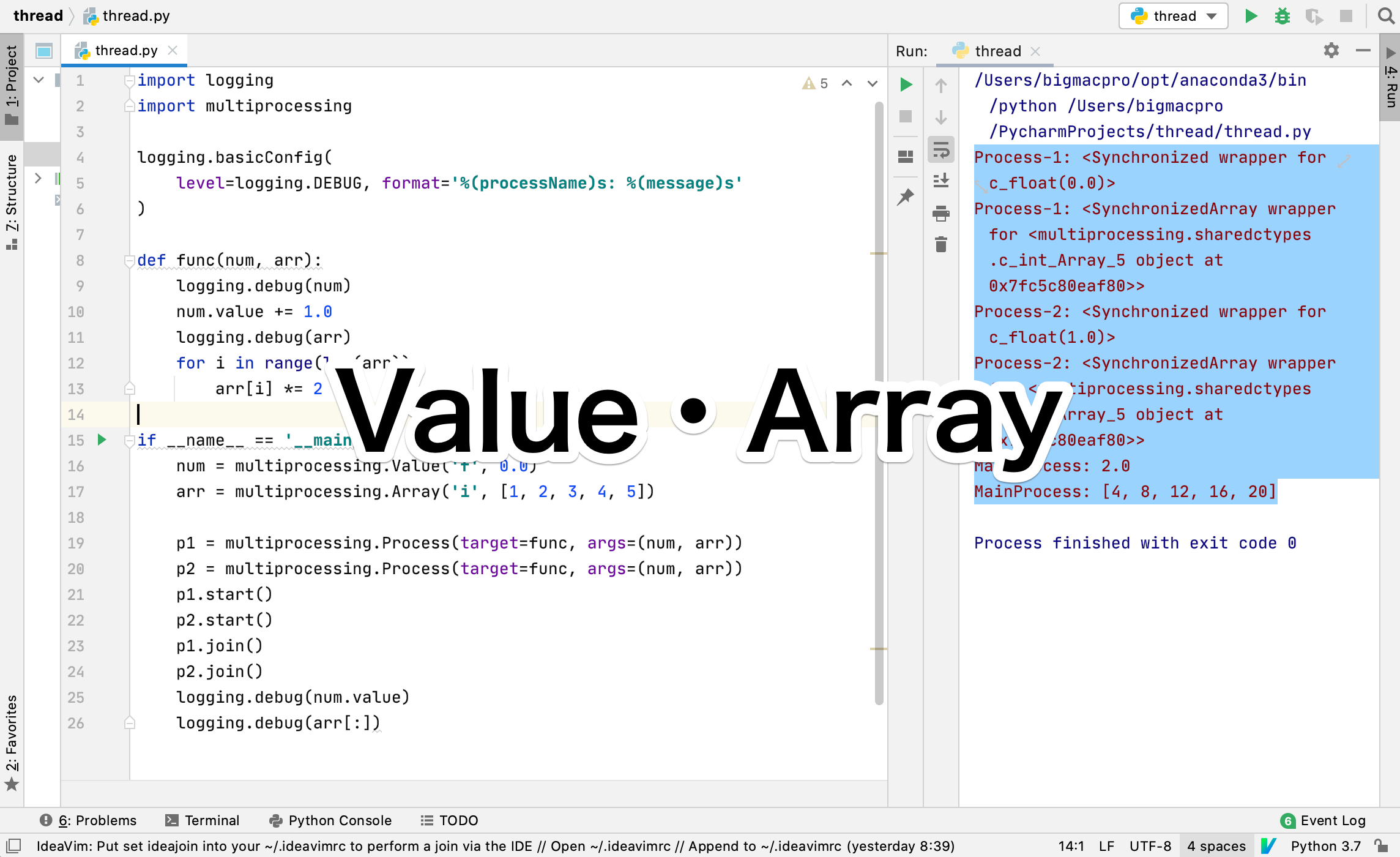
上記のコードは、プロセスが一つだけなので、これでは一体なんのことやらわからないので、プロセスをもう一つ作って並列処理をしてみましょう。
p1 = multiprocessing.Process(target=func, args=(num, arr))
p2 = multiprocessing.Process(target=func, args=(num, arr))
p1.start()
p2.start()
p1.join()
p2.join()p1と同じプロセスをもう一つ作ってstat、joinを付け加えています。
出力結果
Process-1: <Synchronized wrapper for c_float(0.0)gt;
Process-1: <SynchronizedArray wrapper for <multiprocessing.sharedctypes.c_int_Array_5 object at 0x7fc5c80eaf80gt;gt;
Process-2: <Synchronized wrapper for c_float(1.0)gt;
Process-2: <SynchronizedArray wrapper for <multiprocessing.sharedctypes.c_int_Array_5 object at 0x7fc5c80eaf80gtgt;;
MainProcess: 2.0
MainProcess: [4, 8, 12, 16, 20]プロセスが2つ走って、numとarrが共有され、最終的にメインプロセスで出力されている値が2つの処理を行った結果になっているのがわかるかと思います。
ValueとArrayの引数LockはデフォルトでTrueなので、プロセスセーフになっていますが、引数のLockをFalseにしてしまうとプロセスセーフにはならないので、注意が必要です。
あまり使わない
酒井さんの講座では、プロセス間でメモリを共有して処理をするということはあまりないということでしたので、覚えておく必要はないかもしれませんが、こんなことができるというのを頭の片隅にのこしておいたほうがいいでしょう。

あまり使わないからネットでも情報があまりないのかもしれませんし、ここで学習したとしても使わなければそのうち忘れてしまうと思います。
それに、スレッドもプロセスも似たような処理がたくさんあるので、なにがなんやらちょっと頭がこんがらがってきてしまいますよね。
そんなときはAmazonPrimeでも見て、気分転換してみてもいいかもしれませんよ。

それでは明日もGood Python!