Python学習【365日チャレンジ!】227日目のマスターU(@Udemy11)です。
なんだか一気に朝晩が冷え込むようになってきて、夏用布団から秋用のちょっと厚めの布団をすっ飛ばして一気に冬用布団に変えたら、暑すぎて寝汗をかいてしまいました。
季節の変わり目は、体調を崩しがちなので、気をつけないといけませんね。
健康を保つための基本は、規則正しい生活習慣と適度な運動が重要です。
渡しの場合、夜や早朝に釣りに行ったりするので、運動は適度にできているかもしれませんが、ちょっと不規則な生活になってしまっているかもしれません。
それでは、今日もPython学習をはじめましょう。
昨日の復習
昨日は、プロセス間でメモリを共有するValueとArrayについて学習しました。
ValueもArrayもプロセスセーフのCと互換性のあるオブジェクトで、それぞれ値と配列を扱うことができました。
プロセスは通常メモリを共有しないので、プロセスセーフを意識する必要がありますが、どちらのオブジェクトもデフォルトで引数のlockがTrueになっていました。
くわしくは、昨日の記事をごらんください。

今日は、簡単にプロセス間のメモリ共有ができるManegerを学習します。
Manager
Managerはサーバープロセスを管理するもので、ValueとArray同様に、プロセス間でメモリの共有をすることができますが、速度は若干遅くなります。
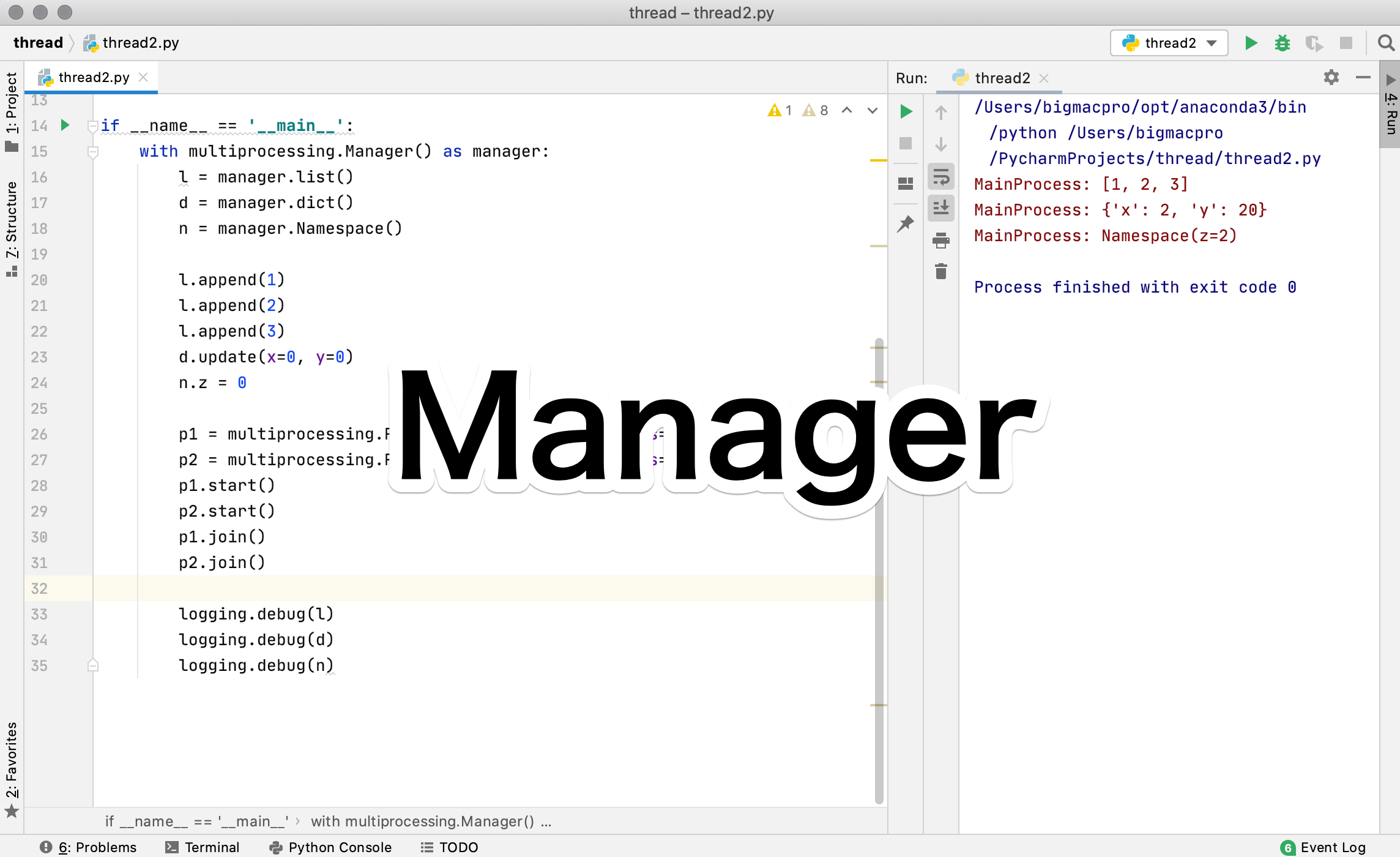
まずはManagerでリストと辞書型、ネームスペースを作って、それらを引数に取るプロセスを1つ作成してみましょう
import logging
import multiprocessing
logging.basicConfig(
level=logging.DEBUG, format='%(processName)s: %(message)s')
def worker1(l, d, n):
l.reverse()
d['x'] += 1
d['y'] += 10
n.z += 1
if __name__ == '__main__':
with multiprocessing.Manager() as manager:
l = manager.list()
d = manager.dict()
n = manager.Namespace()
l.append(1)
l.append(2)
l.append(3)
d.update(x=0, y=0)
n.z = 0
p1 = multiprocessing.Process(target=worker1, args=(l, d, n))
p1.start()
p1.join()
logging.debug(l)
logging.debug(d)
logging.debug(n)14行目から17行目でリスト、辞書型、Namespaceオブジェクトを作成して、19行目から21行目でリストlに値を入れています。
22行目では辞書型にx: 0とy: 0というキーとバリューを代入し、23行目でNamespaceにn=0を入れています。
24行目から26行目で関数workerをターゲット、引数をl, d, nを指定したプロセスを立ち上げて、終了するのを待ちます。
最後の3行で、lとdとnを出力しています。
7行目の関数worker1に戻ってみると、8行目でリストの順番を入れ替えて、9行目で辞書型のkeyがxの値に1を足して、10行目で同じくyの値に10を足しています。
11行目では、Namespaceのzに1を足した値にしています。
最後の3行で、処理の済んだlとdとnを出力してプログラムが終了します。
実行結果
MainProcess: [3, 2, 1]
MainProcess: {'x': 1, 'y': 10}
MainProcess: Namespace(z=1)コードを解説したように、値が更新されて出力されているのがわかります。
続いて、この流れをマルチプロセスで実行してみます。
マルチプロセスで実行
一つのプロセスの場合、データが共有されているかどうかわからないので、プロセスを2つ作成して実行してみます。
変更するのは、25行目からです。
p1 = multiprocessing.Process(target=worker1, args=(l, d, n))
p2 = multiprocessing.Process(target=worker1, args=(l, d, n))
p1.start()
p2.start()
p1.join()
p2.join()他の部分のコードは同じままです。
実行結果
MainProcess: [1, 2, 3]
MainProcess: {'x': 2, 'y': 20}
MainProcess: Namespace(z=2)それぞれのプロセスで、関数worker1が1回ずつ実行されるので、リストはリバースのリバースになり、もとどおりのリストになっています。
次の辞書型データは、xに2回1がたされて2になり、yは10が2回足されて20になっています。
Namespaceは、zに2回1が足されてz=2になっています。
急激にレベルが上がる
私が現在受講しているPythonの講座は、Udemyの酒井さんの講座です。
これまでも紹介してきましたが、たまに一気に難しくなるところがいくつかありますが、これだけ内容が充実した内容のPython講座は存在しないので、超おすすめのPython講座です。
ただ、難しくて挫折してしまう人もいると思うので、必要のあるところだけ学習するというパターンもありです。
プログラミングは、継続して新しいことを学習しながら、しっかりと復習をすることで身につくわけですが、興味のないことを学習するのはある意味苦痛でしかありません。
もちろん、興味がなくてもやってみたら興味が湧いてきたということもあろうかと思います。
酒井さんの講座の中身はかなり充実した内容になっているので、基本的なことだけ酒井さんの講座で学習しても十分納得のいく内容になっていますので、セールなどの際に、ぜひ一度受講してみてください。

それでは、明日もGood Python!