Python学習【365日チャレンジ!】344日目のマスターU(@Udemy11)です。
昨年からストックしていたイカの刺し身を食べたのですが、これで最後だったので冬のデカイカを求めて南紀にエギングに行きたいのですが、ちょっと遠出になるので、春まで我慢しておこうと思っています。
春にイカを釣った経験がないのですが、昨年の経験でエギングのスキルも上がっていることを信じて、春のデカイカをゲットしたいと思います。
ま〜、春まではまだ2ヶ月ほどあるので、それまでは状況を見ながら、アジング・メバリングを楽しもうと思います。
それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、Tkinterを使って、検索キーワードを入力して、URLとタイトルを取得するコマンドを実行するためのボタンを配置した入力ウインドウを作成しました。
Tkinterの基本的な書き方を確認しながら、入力枠、クリアボタン、抽出ボタンを配置して、ボタンにはコマンドを紐付けました。
詳しくはこちらの記事をごらんください。

今日は、これまでの検索キーワードからURLとタイトルをCSVに書き出すコードを少しカスタマイズして、昨日作成したファイルからインポートできるモジュールに仕上げたいと思います。
scrape_u_t.py
scrape_u_t.pyは、昨日書いたgetut_data.pyからインポートされるファイルで、getut_data.pyの入力ウインドウから渡されたkeywordsを受け取って、Google検索の結果から取得したURLとタイトルをCSVに保存するプログラムです。
今回のコードはこれまで作成したコードと内容は同じで、他のファイルからインポートされるので、インポートしたときに実行されないよう、コードをmain関数にして、最後にいつものif文を付け加えています。
import csv
import os
import re
import urllib.parse
from bs4 import BeautifulSoup
import requests
DESKTOP_PATH = os.getenv('HOME') + '/Desktop/url_title.csv'
def main(keywords):
r = requests.get('https://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=' + keywords)
html_soup = BeautifulSoup(r.content, 'html.parser')
url_results = []
for t in html_soup.select('.kCrYT > a'):
u_result = re.sub(r'/url\?q=|&sa.*', '', t.get('href'))
url_results.append(urllib.parse.unquote(u_result))
title_results = []
for i in url_results:
try:
search = requests.get(i)
search_soup = BeautifulSoup(search.content, 'html.parser')
titles = search_soup.find('title')
title_results.append(titles.text)
except:
print('取得できませんでした。')
with open(DESKTOP_PATH, 'w') as csv_file:
fieldnames = ['TITLE', 'URL']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for t, u in zip(title_results, url_results):
writer.writerow({'TITLE': t, 'URL': u})
if __name__ == '__main__':
main()追加、変更したコードをハイライトしていますが、インポートするライブラリにosを追加しています。
次に、CSVを保存する場所をデスクトップにするためのグローバル変数DESKTOP_PATHをos.getenv()を使って定義しています。
ちなみに、このコードはMacようですが、Windowsだと次のようなコードでデスクトップのPathが取得できるようです。
os.getenv('HOMEDRIVE') + os.getenv('HOMEPATH') + '\\Desktop'次に、11行目にdef main(keywords)で、getut_data.pyから引数keywords受け取れるようにして、36行目までのコードを1つインデントを下げています。
main関数の引数をkeywordsにしていますが、wordなどの任意の名前でも問題はありませんが、わかりやすいように受け取る変数と同じ名前にしています。
31行目のファイル名utl_title.csvは、グローバル変数のDESKTOP_PATHに変更しています。
最後の38行目と39行目は、他のモジュールからインポートされたときに、自動的に関数が実行されないようにするためのif文を書いて完成です。
動作確認動画
今回作成したアプリを実行して、動作確認の動画を撮ってみましたので、参考にどうぞ
最初に実行するファイルはgetut_data.pyです。
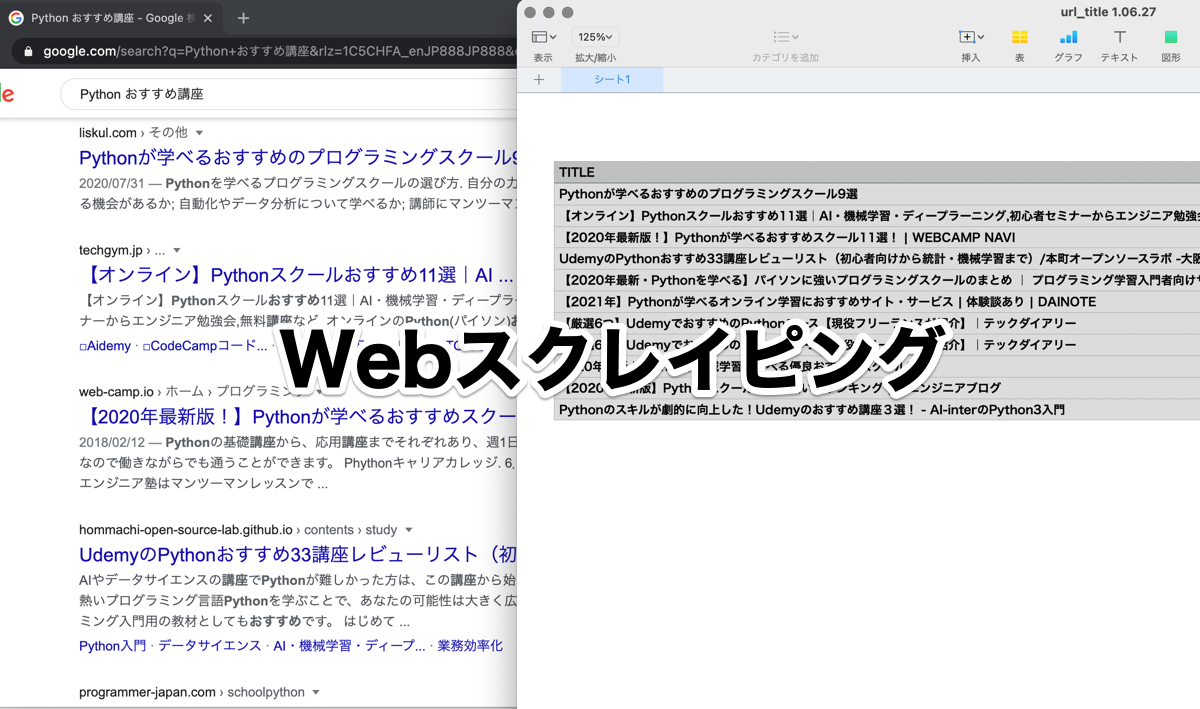
getut_data.pyを実行すると、入力ウインドウが表示されて、キーワードを入力して、抽出ボタンをクリックすると、入力したキーワードの検索ページのタイトルとURLがデスクトップにCSVファイルとして保存されて、メニューのFileからExitを選ぶとアプリが終了しています。
実際にブラウザでGoogle検索したページを表示させるのを忘れてしまったのですが、下の画像をごらんになれば、Google検索結果と同じページが保存されているのがわかるかと思います。
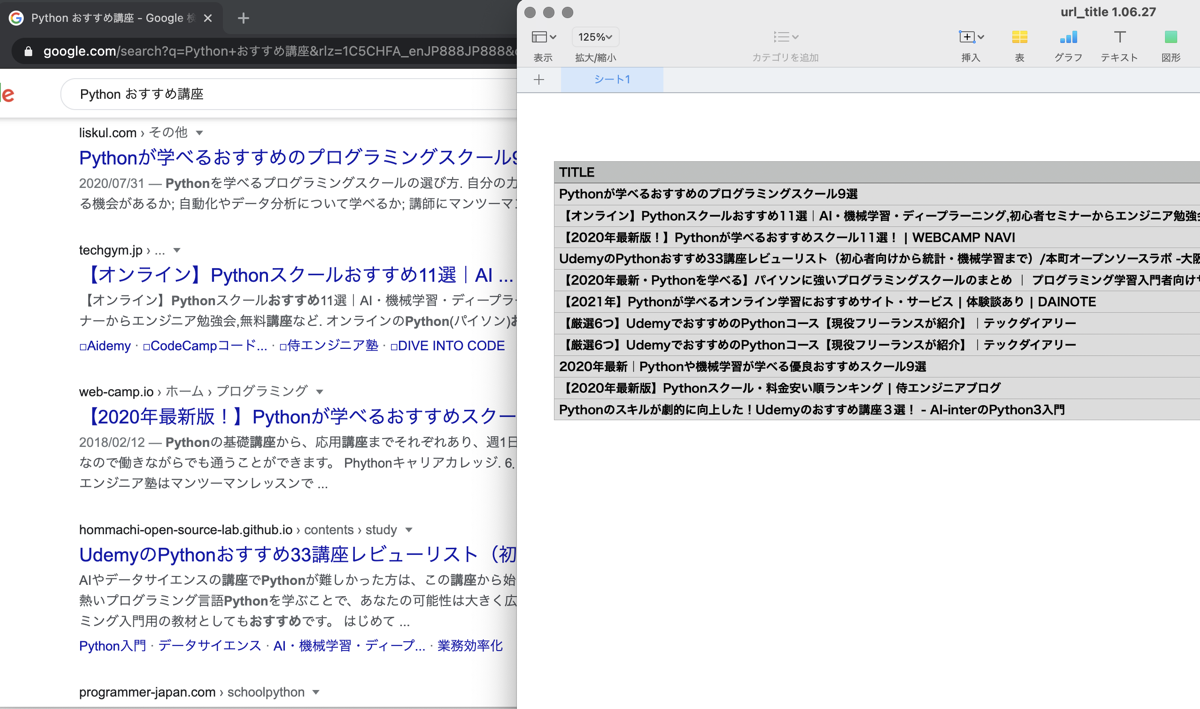
まとめ
これでとりあえず、入力したキーワードのGoogle検索結果からURLとタイトルを抽出してCSVファイルに保存するアプリが完成です。
やっぱり、自分でやりたいことをPythonで具体的に形にすることは、めっちゃ楽しいですし、うまくいかなくても、問題を解決するまでの気持ちの持ち方が違いますし、実際にきちんと動いたときのなんとも言えない満足感は、他では得られないものがあります。
Pythonマスターからすると、きちんとしたエラー対応ができていないかもしれないのですが、一応はURLとタイトルをGoogleの検索結果からCSVに出力することができました。
このプログラムをもとにして、検索結果ページからh2タグやH3タグなどを抜き出すコードを作って、Googleスプレッドシートに書き出すコードも作っていこうと思います。
その前に、明日はこのプログラムをpy2appを使って、Mac用アプリを作りたいと思います。
それでは、明日もGood Python!