Python学習【365日チャレンジ!】342日目のマスターU(@Udemy11)です。
いまさらながらですが、年末から食べまくっていたせいで、胃が大きくなったのか、ご飯を食べて2時間経たずにお腹が減った感を感じてしまいます。
なんとか我慢をしているのですが、夕飯のあとにデザートを食べる習慣がついてしまい、体重を減らすどころか、微増の状態をキープしてしまっています。
今日を最後に食事を減らしていこうと思います。
それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、Google検索の1ページ目にヒットしたURLとタイトルを取得するファイルと、CSVに書き出すファイルに分けて、URLとタイトルをCSVファイルに書き出してみました。
CSV書き出しファイルの方で、データを取得したファイルをインポートして、インポートしたファイルのリストをCSVに書き出しました。
詳細についてはこちらの記事をごらんください。

今日は、検索キーワードを入力して、入力されたキーワードで検索した結果のページからURLとタイトルを抽出するコードに挑戦してみたいと思います。
inputを使うだけ
これまでのコードを振り返るとわかりますが、search_queryに検索キーワードを代入しているので、この部分を以前学習したinputにするだけです。
import csv
import re
import urllib.parse
from bs4 import BeautifulSoup
import requests
search_query = input('検索キーワード:')
r = requests.get('https://www.google.co.jp/search?hl=jp&gl=JP&num=10&q=' + search_query)
html_soup = BeautifulSoup(r.content, 'html.parser')
url_results = []
for t in html_soup.select('.kCrYT > a'):
u_result = re.sub(r'/url\?q=|&sa.*', '', t.get('href'))
url_results.append(urllib.parse.unquote(u_result))
title_results = []
for i in url_results:
try:
search = requests.get(i)
search_soup = BeautifulSoup(search.content, 'html.parser')
titles = search_soup.find('title')
title_results.append(titles.text)
except:
print('取得できませんでした。')
with open('url_title.csv', 'w') as csv_file:
fieldnames = ['TITLE', 'URL']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for t, u in zip(title_results, url_results):
writer.writerow({'TITLE': t, 'URL': u})ファイルを実行するとキーワードの入力を求められるので、入力してEnterを押すとCSVファイルが出力されます。
出力結果
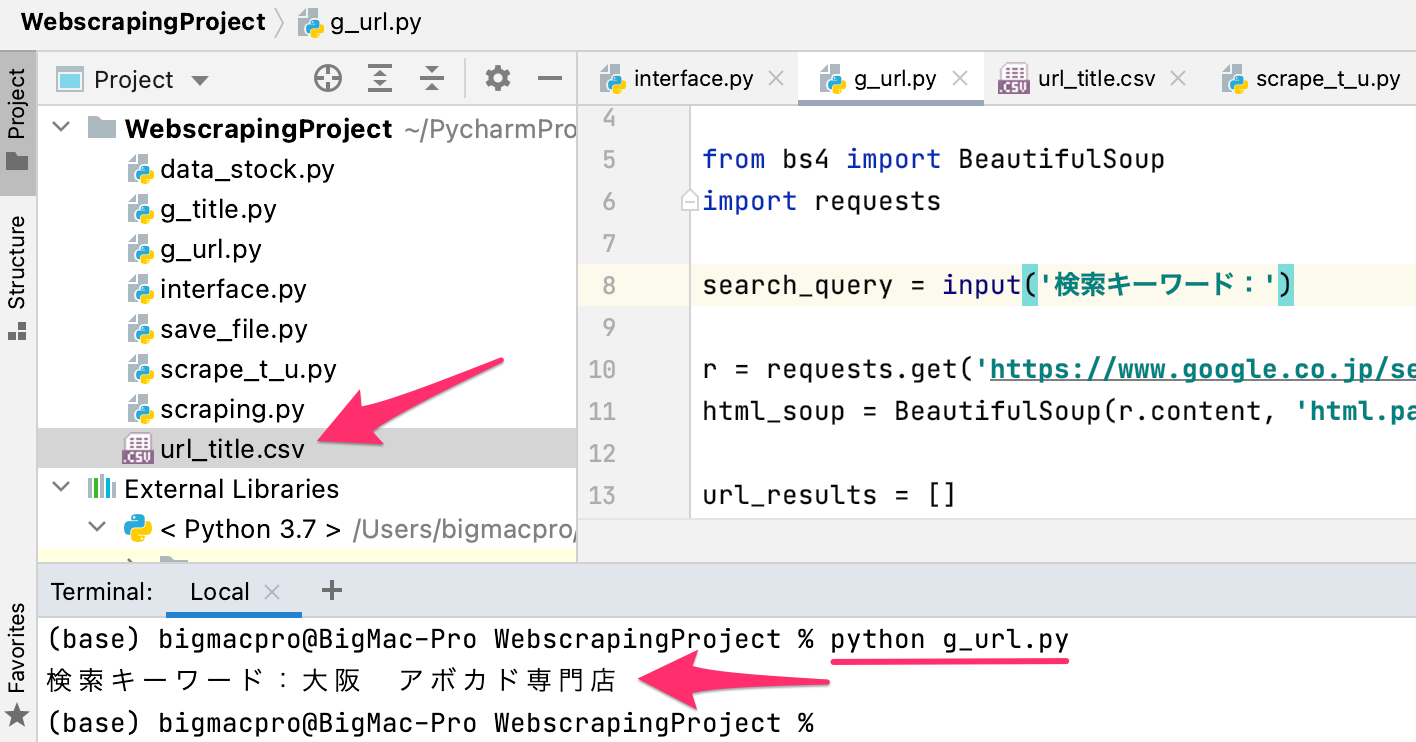
url_title.csv
TITLE,URL
大阪・京都・神戸のアボカド専門店5選!関西でアボカド好きには必見なお店を紹介 - おすすめ旅行を探すならトラベルブック女子旅,https://www.travelbook.co.jp/topic/32751
大阪・福島のアボカド専門店『Cafe&Bar AVOCADO』で、アボカド料理をアテにゆる飲みのすすめ | PrettyOnline,https://www.pretty-online.jp/news/793/
無性に食べたくなったときはここへ!アボカドが楽しめる大阪のお店7選 | RETRIP[リトリップ],https://rtrp.jp/articles/111259/
アボカド (AVOCADO) - 野田阪神/カフェ [食べログ],https://tabelog.com/osaka/A2701/A270108/27054503/
全メニューにアボカド使用!アボカド専門店「Cafe&Bar AVOCADO」 | icoico,https://icoico.jp/archives/25929
大阪の『アボカド』特集 グルメ・レストラン予約 | ホットペッパーグルメ,https://www.hotpepper.jp/food/SA23/f0101566/
大阪・京都・神戸のアボカド専門店5選!関西でアボカド好きには必見なお店を紹介 | NAVITIME Travel,https://travel.navitime.com/ja/area/jp/guide/TRV20180707050047/
アボカド (Avocado) (野田/カフェ) - Retty,https://retty.me/area/PRE27/ARE618/SUB8904/100000702610/
アボカド「アボカド専門店。すべてのメニューにアボカドが使われており、...」:野田,https://retty.me/area/PRE27/ARE618/SUB8904/100000702610/1135657/
【2021年 最新グルメ】梅田・大阪駅にあるアボカド料理が食べられるお店 | レストラン・カフェ・居酒屋のネット予約(大阪版),https://beauty.biglobe.ne.jp/gourmet/osaka-%E3%82%A2%E3%83%9C%E3%82%AB%E3%83%89/%E6%A2%85%E7%94%B0%E3%83%BB%E5%A4%A7%E9%98%AA%E9%A7%85%E3%82%A8%E3%83%AA%E3%82%A2/CSVファイルには、きちんとタイトルとURLが保存されています。
文字化けの修正
前回までのコードだと、検索キーワードによって、取得するページのタイトルが文字化けを起こしてしまうものがありました。
ネットで調べつつコードを変更していろいろと試していたのですが、BeautifulSoupでパースするときに、.textにするのではなく、.contentに変更することで、文字化けを起こさずにタイトルを取得することができるようになりました。
上記のコードだと、11行目と22行目の部分です。
html_soup = BeautifulSoup(r.content, 'html.parser') search_soup = BeautifulSoup(search.content, 'html.parser').textだと文字列を取得するのに対して、.contentはHTMLのbytes形式データを取得するので、文字化けするリスクを減らすことができるようです。
ということで、Beautifulsoupの.textを.contentに変更したら、文字化けがなくなったというお話でした。
まとめ
最初に見たサンプルコードでコードを書き始めるので、.textが文字化けの原因だったというのになかなか気づくことができませんでした。
最初にうまくいけば、そのやり方が自分自身のスタンダードになるので、きちんとどんな役割があるコードなのかを理解せずにコードを書き進めてしまいます。
今回はいろいろなコードを見ている中で、.contentという記述を見つけたので、試してみることができました。
同じ結果を取得できるコードは何通りもあるので、いろいろと試すことが大切だというわかりやすい例になりました。
今回の目的であった入力したキーワードで検索するのは、input()だけでできたので、あまった時間を有効活用できて良かったです。
それでは、明日もGood Python!