Python学習【365日チャレンジ!】327日目のマスターU(@Udemy11)です。
お正月3が日を何もせずに家でおとなしくしていたのは、生まれて初めてのことです。
東京都などが緊急事態宣言を国に要請したり、国はそれを無視したり、ほんといつまで責任の押し付け合いをしてるんでしょうか?
ある意味、どちらも策がなくて、流れに任せるしかないんでしょうけど、どちらも本気でどうにかしようと考えてるのかは甚だ疑問です。
責任を取れないのなら、専門家に任せて、失敗したら、専門家のせいにでもすればいいのにと思いますけどね。
とりあえず、密集を避けていればある程度感染は抑えられるようなので、人混みに行かないことが一番なので、家でアマゾンプライムビデオでも見るのがおすすめです。

それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、収集したデータと同じようなデータを比較して、判断指標とするためのデータマイニングを学習しました。
大量のデータやいくつかの指標を組み合わせて、関係性をみつけることがデータマイニングですが、株式に関しては、いくつかの指標が用意されているので、それらを活用して、株の売り買いの判断基準を見つけました。
複数の会社の株価の値動きや株価の値上がり率などをグラフ化して比較しましたが、たくさんの基準がある中で、自分が判断できる基準を持つことが大切でしたね。
くわしくは、昨日の記事をごらんください。
今日は、準備したデータを活用して機械学習させるマシンラーニング学習します。
マシンラーニング
マシンラーニングは、【Jupyter】機械学習のscikit-learnの基本でも学習しましたが、機会に学習をさせて、その傾向を予測に活かす流れのことで、教師あり学習や教師なし学習がありますが、株価の予測については、過去の大量データを与えて、その先の株価の変動を予測します。
今回は、30日前の株価と現在の株価を学習させて、今後の株価の予測をさせてみます。
import datetime
import matplotlib.pyplot as plt
import numpy as np
import pandas_datareader
import sklearn
import sklearn.linear_model
import sklearn.model_selectionまずは、必要なライブラリをインポートします。
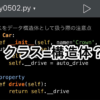
df_aapl = pandas_datareader.data.DataReader('AAPL', 'yahoo', '2018-12-01')
df_aapl['label'] = df_aapl['Close'].shift(-30)
X = np.array(df_aapl.drop(['label'], axis=1))
X = sklearn.preprocessing.scale(X)2018年12月1日から現在までのアップルの株価を取得して、30日後の株価を入れた新しいlabel列を追加。label列を除いた値をXに代入して、予測結果の精度を上げるため、sklearn.preprocessing.scale(X)で変動が大きすぎる値を除去します。
predict_data = X[-30:]
X = X[:-30]
y = np.array(df_aapl['label'])
y = y[:-30]
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
X, y, test_size = 0.2)
lr = sklearn.linear_model.LinearRegression()
lr.fit(X_train,y_train)predict_dataに30日後データ(label)のないデータを入れ、同じように、Xのデータを更新しています。
yには、30日後データ(label)のないデータを除いたlabel行を代入して、Xとyをトレーニングデータ80%、テストデータ20%に分けて配列を作り、、sklearnで学習させています。
accuracy = lr.score(X_test, y_test)
accuracy
# 0.9285180916632623トレーニングデータとテストデータの関連性に、どの程度の信頼性があるかlr.scoreで確認してみると、約93%のスコアが出ていることが確認できました。
predicted_data = lr.predict(predict_data)
predicted_data
# array([131.98235655, 131.3038217 , 130.83856174, 128.03520343,
# 127.95165906, 129.92973445, 131.2920952 , 130.60616589,
# 132.63292698, 133.42538704, 133.8232751 , 133.31498378,
# 134.95556483, 134.52406585, 133.93701452, 134.69825509,
# 132.6195338 , 133.85114281, 134.98245377, 136.44840771,
# 137.34076361, 133.42512041, 135.71999044, 138.35950928,
# 139.1579759 , 141.61939788, 141.96890888, 141.74304343,
# 141.00677921, 140.05916606])
次に予測ですが、先に用意していた30日後データが入っていないpredict_dataについて、学習したアルゴリズムを使ってpredicted_dataに値を予測して代入して出力しています。
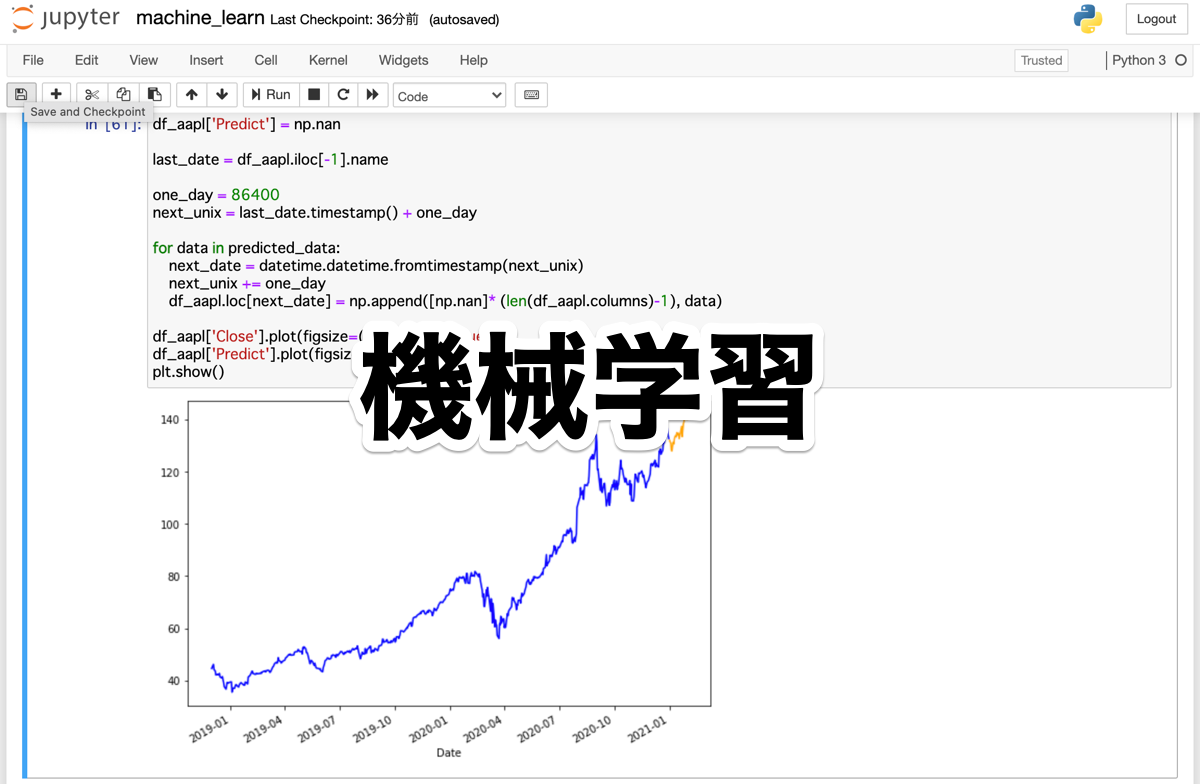
df_aapl['Predict'] = np.nan
last_date = df_aapl.iloc[-1].name
one_day = 86400
next_unix = last_date.timestamp() + one_day
for data in predicted_data:
next_date = datetime.datetime.fromtimestamp(next_unix)
next_unix += one_day
df_aapl.loc[next_date] = np.append([np.nan]* (len(df_aapl.columns)-1), data)
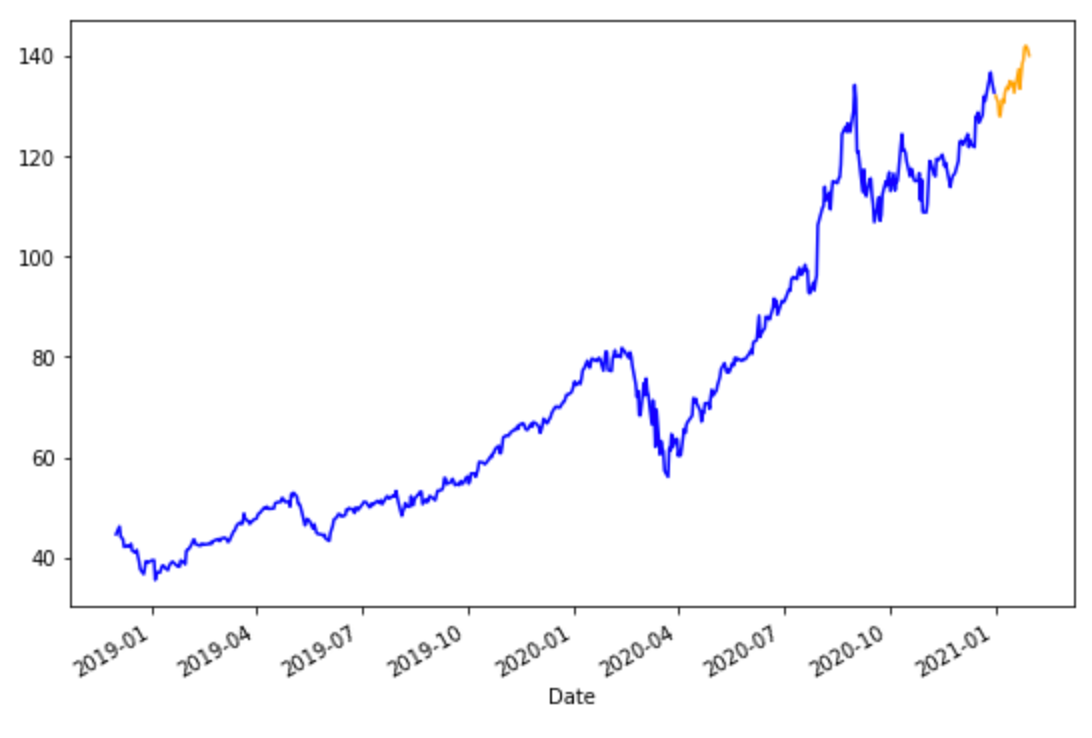
df_aapl['Close'].plot(figsize=(9,6), color="blue")
df_aapl['Predict'].plot(figsize=(9,6), color="orange")
plt.show()df_aaplに新しい空のPredict列を付け加えて、最後の日付をlast_dateに入れます。
UNIX系で1日が86400になるので、1日分足したものをnext_unixに代入します。
次に、予測したpredicted_dataをforループで回して、次の日付(next_dateを計算して、next_unixに1日足して値を更新します。
新しく追加した行のPredictにdataを入れて、他の列には、nanを入れています。
最後に、df_aapl['Close']を青色、df_aapl['Predict']をオレンジで折れ線グラフにして表示しています。
まとめ
酒井さんの講座のサンプルコードを少し変更しているのですが、0からコードを書くのはかなり難しいと感じています。

0から何かを作り上げるのはかなりの知識とスキルが必要になるので、まずは参考になるコードを少しずつ変更して、変更がどのように反映されるのか確認しながら、コードを覚えていく必要があります。
すでに300日以上、Python学習を進めているのですが、一日中コードと向き合っているわけではないので、なかなか理解が進んでいないのが現状です。
やはり集中してコードを書きまくる期間を設けてトレーニングする必要があると感じている今日このごろ。
まずは酒井さんの講座をひととおり学習することを目標にしているので、講座を修了したら、集中期間を設けたいと思います。
それでは、明日もGood Python!