Python学習【365日チャレンジ!】290日目のマスターU(@Udemy11)です。
最近、周りでAppleWatchを使っている人が増えてきて、そろそろAppleWatchデビューしたいな~と思いつつ、楽天のブラックフライデーセールで散財したことを思い出し、AppleWatchデビューはあきらめました。
ほんとセールは待ち遠しいのですが、あれもこれも欲しいものがありすぎて、まったくもってお金が足りません。。。
世間では、そろそろボーナスなんてものに向けた年末年始のセールもあるし、金欠どころか、下手をすると借金まみれになってしまいそうです。
きちんと自分の物欲をコントロールしなければ!
そういえば、今日からAmazonブラックフライデー&サイバーマンデーセールが始まっていますので、この機会に欲しいものをゲットしてください。

それでは今日も、Python学習を始めましょう。
昨日の復習
昨日は、compileとsubを使って、文字列を置換する方法をを習しました。
compileの引数に|(パイプ)を使って検索文字を指定して、subを使って検索した文字を任意の文字列に置換することができました。
置換する回数を指定したり、subnを使って置換した回数を取得することもできました。
くわしくは昨日の記事をごらんください。

今日は、正規表現のGreedyとLazyについて学習します。
Greedy
正規表現を使ったコードの処理で、GreedyとLazyというものがあり、正規表現を使う際には注意しておく必要があります。
まず、Greedyですが、英語で【貪欲】という意味ですが、正規表現を使ったパターンにマッチする範囲が最大になることで、re.matchやre.searchは、デフォルトでGreedyになっています。
例えば、HTMLタグでタグを抽出する場合を考えてみます。
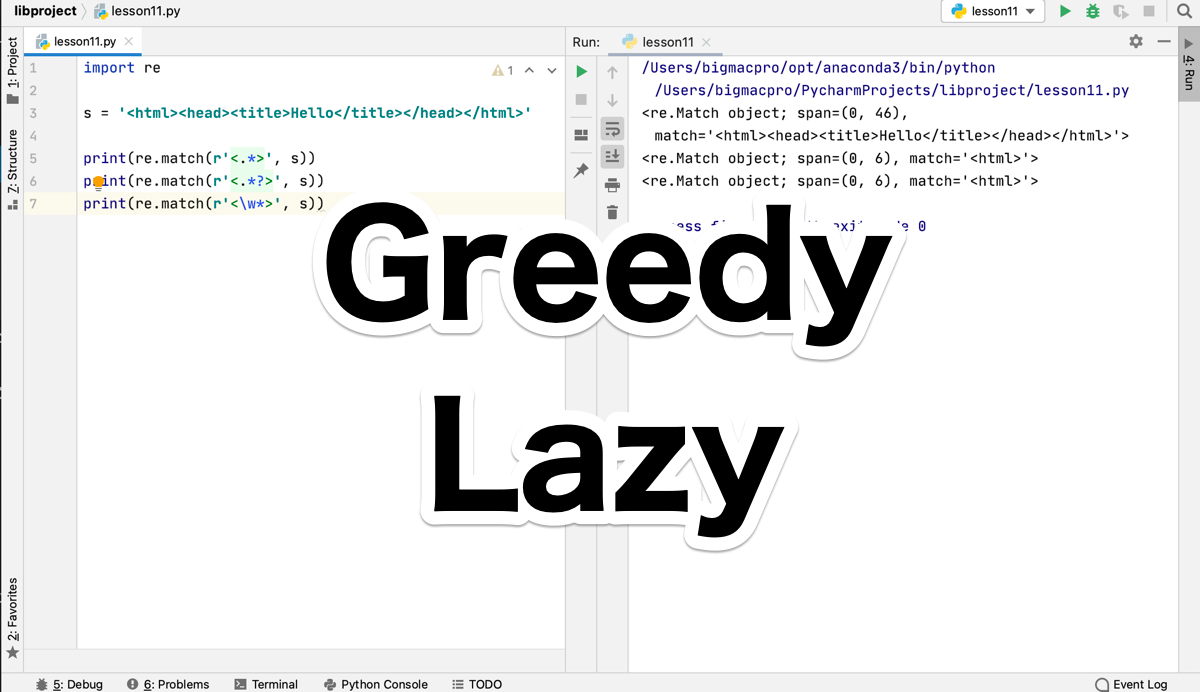
import re
s = '<html><head><title>Hello</title></head></html>'
print(re.match(r'<.*>', s))出力結果
<re.Match object; span=(0, 46), match='<html><head><title>Hello</title></head></html>'>3行目でHTMLタグを記述して、変数sに代入し、5行目のr'<.*>'でタグで囲まれた何らかの文字を0回以上繰り返すマッチオブジェクトを出力しています。
出力結果を見ると、指定した変数sがすべて出力されていますが、.が何らかの文字なので、途中の>が何らかの文字として認識され、最後の>でようやくマッチが完了しているわけです。
途中の>は、終了の>として認識されていないということです。
Lazy
一方、Lazyは、【怠惰】という意味で、正規表現のパターンの最後に?をつけることで、最小限のマッチする部分を取得することができます。
print(re.match(r'<.*>?', s))出力結果
<re.Match object; span=(0, 6), match='<html>'>?によって、.*(何らかの文字の0回以上の繰り返し)を必要最小限にすることを指定してるので、出力されたマッチオブジェクトのマッチしている部分が<html>だけになっているのがわかります。
まとめ
今回の正規表現も、.*ではなく、\w*(英数字とアンダースコアー)の0回以上の繰り返しにすれば、<html>を抽出することができますが、抽出したい文字が正規表現に含まれている場合は注意が必要ですので、気をつけておきましょう。
ある意味種類分けさえ理解しておけば問題なさげなところですが、コードには?を使ったLazyな正規表記を見かけることもあるとのことなので、頭の片隅に入れておくようにしましょう。
ということで、明日もGood Python!