Python学習【365日チャレンジ!】232日目のマスターU(@Udemy11)です。
みなさん普段使っているお箸って、どんなものを使っていますか?
私は、自宅では、京都の白竹箸、携帯用に江戸木箸の黒檀の八角箸やCHOPSTICKS.JPのKUN【棍:コン】を使っています。
実は結構なお値段がするのですが、ある意味ちょっとした自己満足ですね。
江戸木箸の専門店【大黒屋】は、テレビで紹介されてから大忙しみたいですが、私みたいなお箸にお金をかける変わり者も結構いるようです。
そんな私が今、もっともほしい携帯箸がこちら

新潟の三条市にあるマルナオ株式会社の黒檀の携帯用箸セットです。
値段が35,200円(税込)もするので、ロッドやリールと天秤にかけるとやっぱり釣具に軍配が上がるんですよね。
ということで、これからも欲しいものリストに入ったままの状態を当分キープすることは間違いないでしょう。
それでは、今日もPython学習をはじめましょう。
昨日の復習
昨日は、2進数と10進数、16進数について学習しました。
コンピューターが得意な2進数、人間が得意な10進数、そしてどちらも無難に理解できる16進数が人間とコンピューターの間を取り持っていますが、それぞれの考え方や変換方法について学習しました。
2進数から16進数への変換は少しなれが必要だと思いますが、どれもコツを掴めばきちんと理解できるようになりますので、しっかりと理解を深めるようにしましょう。
2進数、16進数を復習したい方は、ぜひ昨日の記事をごらんになってみてください。

それでは今日から新しいセクションの暗号化に進みますが、まずは文字コードについて学習します。
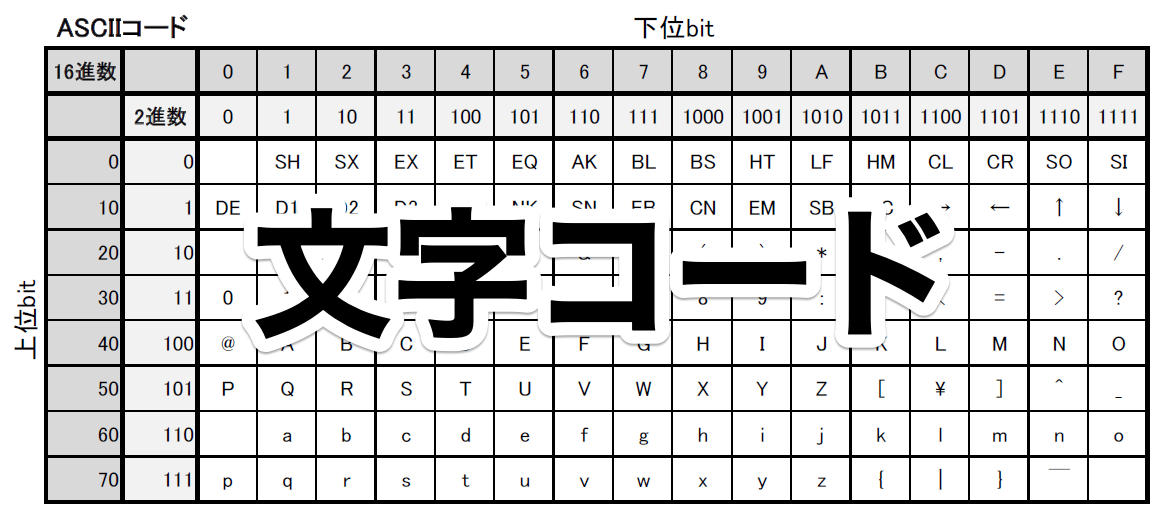
文字コード
文字コードは、人が扱う文字をコンピューターが使うコードに置き換えた対応表で、ASCIIコードやShift-JIS、Unicodeなどの文字コードが存在します。
その対応表には次の2つの分類が存在します。
- 符号化文字集合:【文字】と【文字に割り当てたコード】の対応表
- 文字符号化方式:【文字に割り当てたコード】と【コンピューターが扱うコード】の対応表
【文字】を【コンピューターが扱うコード】に割り当てればいいわけですが、コンピューターが扱うのは0と1だけしかない2進数であり、2進数に割り当てる文字が多くなってくると桁がどんどん増えてきて、人間が認識するにはわかりにくくなってしまいます。
そこで登場するのが16進数で、文字を16進数にしてから16進数をコンピューターが理解できる2進数に変換します。
それではなぜ16進数が使われるかについて少し考えてみましょう。
コンピューターが扱えるのは2進数ですが、その最小単位である1桁が1bit(ビット)と定義されて、2通りの値を扱うことができます。
2桁になると2bitで4通り、4桁になると4bitで16通り、8桁になると8bitになり256通りの値を扱うことが可能になります。
ちなみに、8bitが1Byte(バイト)と決められています。
16進数は、1桁で4bit(2進数の4桁)分の値を扱えるので、16進数で4桁使えば16bitで65536通りの値を扱うことができます。
Excel2003までを使っていた人なら、65536という数字にピンときた方もいるでしょう。
他にもIPアドレスは、256通りの値を4つ使って表していますので、32bitで4294967296通り、つまり約43億通りのアドレスを作ることが可能なんですね。
次に、世界で使われている主要の言語に使われている文字数を考えてみます。

こちらのページの情報によると、各言語で扱う文字数は、日本語で2300文字、中国語で3510文字、英語は62文字、ドイツ語69文字、フランス82文字なので、16進数で4桁の16bit分の65536通りあれば、主要な世界の言語に対応した文字コードができるということですね。
ASCIIコード
今日学習するASCIIコードは、符号化文字集合ですが、最初に説明した2つの分類とは少し違い【文字】を直接【コンピューターが扱うコード】である2進数に割り当てています。
もちろん人間がわかりやすいように、ASCIIコードの対応表は16進数でも書かれています。
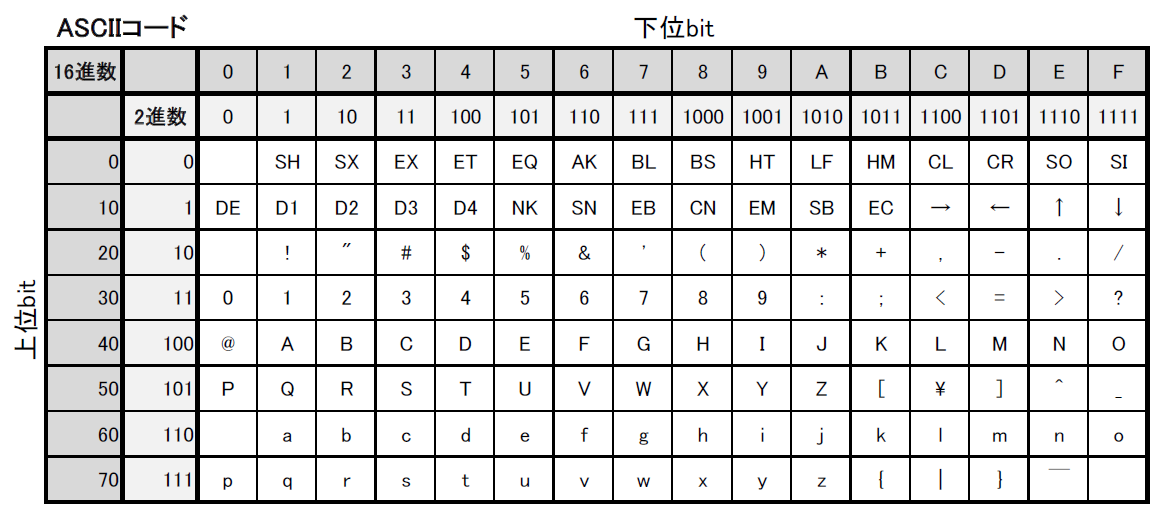
ASCIIコードは、英数字とラテン文字、アラビア数字など、約130通りの文字や動作が割り当てられているので、8bit(256通り)で十分事足りるということなのです。
コンピューターが生まれた地域は、アルファベットだけを扱えれば問題の無い英語圏ですので、割り当てが英数字のみでよく、文字を直接2進数に変換しても桁が長くなりすぎることがなかったので、直接変換しても問題がなかったわけです。
それでは、具体的にPythonを使って、文字を変換したASCIIコードを調べてみます。
ord()
ord()を使えば文字を10進数に変換することができますのでいくつか変換してみましょう。
items = ['a', 'A', '$', '=', '1']
d = []
for i in items:
d.append(ord(i))
print(d)1行目でリストitemsを作って、変換する文字a、A、$、=、1を入れています。
3行目で空のリストdを作り、ord()で10進数に変換した値をappend()でリストdに追加して最後にリストを出力しています。
出力結果
[97, 65, 36, 61, 49]10進数だと、文字a、A、$、=、1は、それぞれ97、65、36、61、49に変換されます。
bin()
bin()を使えば10進数を2進数に変換することができます。
先ほどの文字を10進数に変換したリストdを使って、それぞれの文字a、A、$、=、1を2進数に変換してみます。
b = []
for i in d:
b.append(bin(i))
print(b)10進数に変換したときと同様に、空のリストbを作って、forループとappendでリスbトに追加し、最後にリストを出力します。
出力結果
['0b1100001', '0b1000001', '0b100100', '0b111101', '0b110001']先頭についている0bは、2進数を表していて、文字a、A、$、=、1は、それぞれ2進数で1100001、1000001、100100、111101、110001になります。
hex()
次にhex()を使って10進数のリストdを16進数に変換してみましょう。
h = []
for i in d:
h.append(hex(i))
print(h)出力結果は、先程のコードから関数をhex()に変更されただけのコードになります。
出力結果
['0x61', '0x41', '0x24', '0x3d', '0x31']2進数の時と同じように先頭に0xがついていますが、これは16進数のデータを表したものです。
なので、文字code class=”art”>a、A、$、=、1は、それぞれ16進数で、61、41 24、3d、31に変換されます。
なんだか嬉しくなる
何気に文字コードって誰でも見たことはあると思います。
パソコンの文字パレットなんかで文字を探すときに82A0なんていう4桁の16進数のコードが表示されているんです。
これまでは、「なんだろなこれ?」と思っていたのですが、今回2進数、16進数、文字コードを学習したことで、意味が分かるようになり、コード表を見ているだけで楽しくなってきました。
普段は目にしない奇妙な文字の羅列も意味が分かってくるとほんとうれしくなっちゃうんですよね。
これでさらに変態の領域に近づいた気がしないでもありませんが、他の文字コードも理解して、さらなるレベルアップを目指します。
それでは明日もGood Python!